







 本文详细介绍了Kafka的数据存储机制,包括其基于磁盘的持久化存储特性,消息的存储策略,以及如何通过时间或大小策略删除旧数据。此外,文章深入探讨了Kafka与Zookeeper的交互,包括控制器的选举过程,以及Zookeeper如何用于存储broker和消费者信息。
本文详细介绍了Kafka的数据存储机制,包括其基于磁盘的持久化存储特性,消息的存储策略,以及如何通过时间或大小策略删除旧数据。此外,文章深入探讨了Kafka与Zookeeper的交互,包括控制器的选举过程,以及Zookeeper如何用于存储broker和消费者信息。
kafka的数据是存储在磁盘上的,重启之后数据不会丢失。
但是kafka的默认配置中,消息只会存储7天,7天以后会被删除,默认配置在config/server.properties中的log.retention.hours这一参数中。
原理:
https://blog.youkuaiyun.com/u013063153/article/details/73799907
https://blog.youkuaiyun.com/bluetjs/article/details/52986652
1 存储方式
物理上把topic分成一个或多个patition(对应 server.properties 中的num.partitions=3配置),每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件),如下:
[tom@hadoop102 logs]$ ll
drwxrwxr-x. 2 tom tom 4096 8月 6 14:37 first-0
drwxrwxr-x. 2 tom tom 4096 8月 6 14:35 first-1
drwxrwxr-x. 2 tom tom 4096 8月 6 14:37 first-2
[tom@hadoop102 logs]$ cd first-0
[tom@hadoop102 first-0]$ ll
-rw-rw-r--. 1 tom tom 10485760 8月 6 14:33 00000000000000000000.index
-rw-rw-r--. 1 tom tom 219 8月 6 15:07 00000000000000000000.log
-rw-rw-r--. 1 tom tom 10485756 8月 6 14:33 00000000000000000000.timeindex
-rw-rw-r--. 1 tom tom 8 8月 6 14:37 leader-epoch-checkpoint
2 存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
1)基于时间:log.retention.hours=168
2)基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
3 Zookeeper存储结构
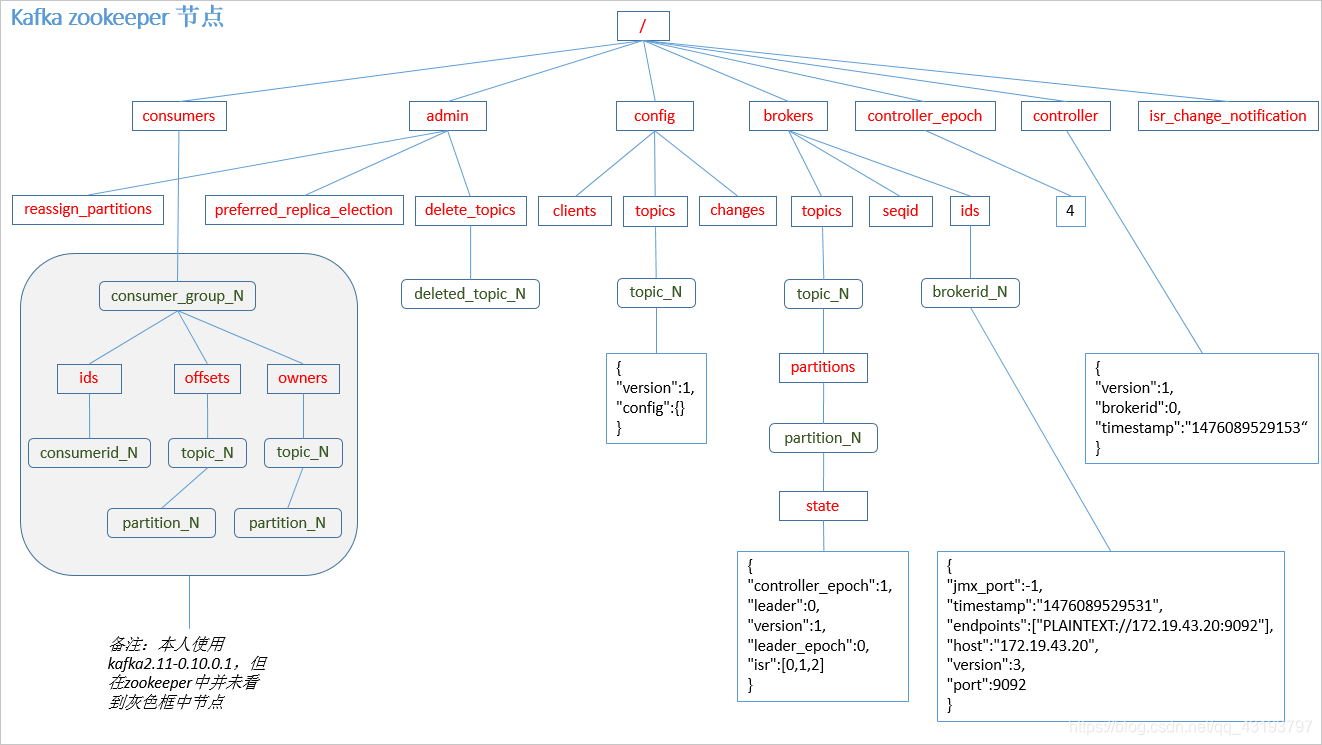
注意:producer不在zk中注册,消费者和kafka在zk中注册。
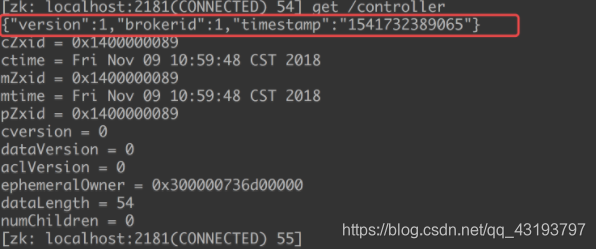
/controller 节点
这个节点是临时节点.
集群里第一个启动的 broker 通过在 Zookeeper 里创建一个临时节点 /controller让自己成为控制器。
控制器其实就是一个 broker,只不过它除了具有一般 broker 的功能之外,还负责分区 首领的选举.
其他 broker 在启动时也会尝试创建这个节点,不过它们会收到一个 “节点已存在” 异常 , 然后“意识”到控制 器节点已存在, 也就是说集群里已经有一个控制器了。 其他 broker 在控制器节点上创建 Zookeeper watch 对象, 这样它们就可以收到这个节点的变更通知。 这种方式可以确保集群里一次只有一个控制器存在。
如果控制器被关闭或者与 Zookeeper 断开连接, Zookeeper 上的临时节点就会消 失。 集群里的其他 broker 通过 watch 对象得到控制器节点消失的通知,它们会尝试让自己成为新的控制器。 第一个在 Zookeeper 里成功创建控制器节点的 broker 就会成为新的控制器, 其他节点会收到“节点已存在”的异常,然后在新的控制器节点上再次创建 watch 对象。
当控制器发现一个 broker 已经离开集群(通过观察相关的 Zookeeper 路径,它就知道, 那些失去首领的分区需要一个新首领(这些分区的首领刚好是在这个 broker 上)。 控制器遍历这些分区,并确定谁应该成为新首领(简单来说就是分区副本列表里的下一个副本), 然后向所有包含新首领或现有跟随者的 broker 发送请求。 该请求消息包含了谁是新首领以及谁是分区跟随者的信息。 随后,新首领开始处理来自生产者和消费者的请求,而跟随者开始从新首领那里复制消息。
简而言之, Kafka 使用 Zookeeper 的临时节点来选举控制器, 并在节点加入集群或 退出集群时通知控制器。 控制器负责在节点加入或离开集群时进行分区首领选举。 控制器使用 epoch 来避免“脑裂” 。 “脑裂”是指两个节点 同时认为自己是当前的控制器。
/brokers 节点
这个节点存储了当前所有 broker 的信息.
它包含 3 个子节点: ids, topics, seqid
![]()
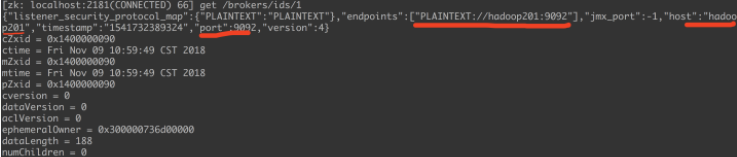
/brokers/ids
每个 broker 都会在这个子节点下创建以自己的 id 值为名的子节点.

这些自己点存储这个 broker 相关的信息:
/brokers/topics
这个节点存储了所有的 topic.
![]()

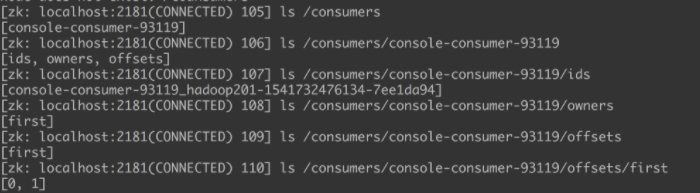
/consumers
保存了消费者的相关信息.

















 5365
5365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









