









1. Few-Shot Question Answering by Pretraining Span Selection
- 为了消除预训练与抽取式问答任务微调之间的GAP,设计了一种新的预训练方式:Recurring Span Selection。简单来说,就是利用一段文本中重复出现的span,比如下图中的"Roosevelt",选取其中一个"Roosevelt"作为答案,其他的使用[QUESTION]代替,预训练时使用[QUESTION]的输出来寻找答案"Roosevelt"的位置。微调时采用"文本[SEP]问题[QUESTION]"的输入形式,同样是使用[QUESTION]的输出来寻找答案"Roosevelt"的位置。

- 小样本情况下,效果比Roberta、SpanBert好
- 使用了为小样本学习设计的带有偏差校正矩估计的Adam优化器(ICLR 2021)
2. A Neural Model for Joint Document and Snippet Ranking in Question Answering for Large Document Collections
- 联合了文档重排序和段落重排序,首先使用传统IR检索引擎检索top-N文档,然后使用模型对文档中所有段落进行打分,取出文档中得分最高的段落分数,与手工定制的文档特征拼接送入全连接层,得到每个文档的得分,再根据文档得分重写段落得分。模型结构如下:
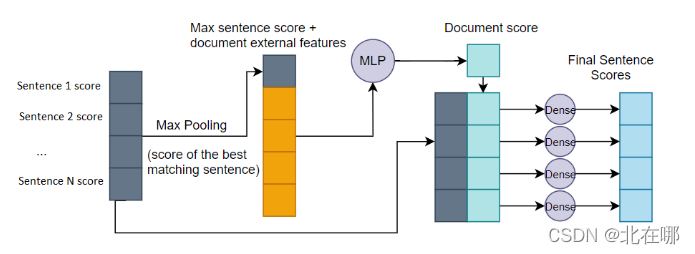
- 分别计算两个损失:文档损失(hinge loss)和段落损失(cross entropy loss),总损失为这两损失的加权和。
- 使用了BIOASQ 7 (2019) 数据集,其中包含 2747 个问题,平均每个问题有 11 个黄金文档和 14 个黄金片段。以及使用了修改后的Natural Questions 数据集。
- 使用了一个可以和BERT掰手腕的轻量级模型——PDRMM,其模型结构如下:
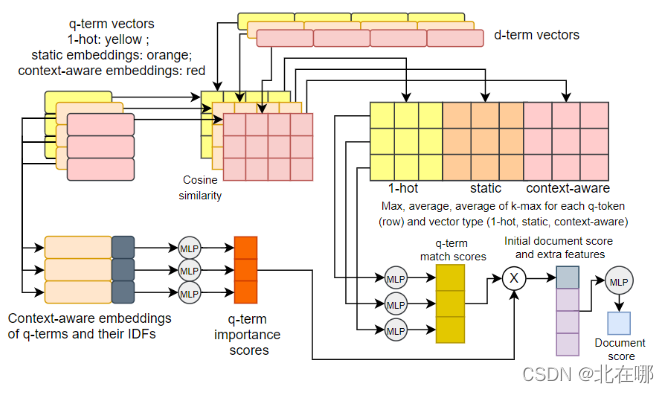
- PDRMM的几个要素:
- 三种embedding:word2vec、经卷积网络变换后的word2vec,onehot;分别采用这三种embedding对查询q(token数量为m)和文档d(token数量为n)做相似度计算,得到三个相似度矩阵 m x n;
- 三种pooling:max-pooling,average-pooling,average-k-max(对最大的k个值取平均);分别对三个矩阵的每一行采用这三种pooling,得到三个 m x 3 的矩阵,将这3个矩阵拼接,得到一个 m x 9 的矩阵;
- 候选匹配得分:由上述 m x 9 矩阵经过MLP层得到,大小为 m x 1;
- 查询q中每个token的权重:将他们的IDF得分与经卷积网络变换后的word2vec拼接,送入MLP层,得到每个token的权重,使用权重将候选匹配得分加权求和;
- 额外的手工文档特征:比如z-score归一化后的BM25得分;d和q完全匹配的token占d中总token的比例;完全匹配的bi-grams的比例。所有的手工特征与上述求和得到的匹配得分拼接,送入MLP得到最终的文档匹配得分。
3. Addressing Semantic Drift in Generative Question Answering with Auxiliary Extraction
- 使用生成模型的encoder提取与答案最为相关的片段(论文中将其称为 Rationale Span,与标准答案相比,F1分数最高的 span 即确定为 Rationale Span),在encoder最后一层添加全连接层和sigmoid函数对每个token进行二分类,Rationale Span 为1,否则为0;使用二分类交叉熵 L R E L_{RE} LRE作为损失函数。
- 使用生成模型的decoder进行答案生成,使用负对数似然 L G E N L_{GEN} LGEN作为损失函数。
- 总的损失为 L = L R E + β L G E N L = L_{RE} + \beta L_{GEN} L=LRE+βLGEN,在训练过程中,线性地衰减 β \beta β 的值。
- 使用了MS MACRO数据集。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









