






 本文介绍了在SQL查询中处理多表JOIN的方法,包括左深树和右深树策略。左深树通过依次JOIN表格并保留中间结果在内存中以减少磁盘读取,而右深树则可能导致更多的磁盘I/O。优化JOIN顺序能显著影响查询效率,例如先JOIN结果较小的表可以加速过程。在实际应用中,寻找最佳的JOIN顺序对于提升数据库性能至关重要。
本文介绍了在SQL查询中处理多表JOIN的方法,包括左深树和右深树策略。左深树通过依次JOIN表格并保留中间结果在内存中以减少磁盘读取,而右深树则可能导致更多的磁盘I/O。优化JOIN顺序能显著影响查询效率,例如先JOIN结果较小的表可以加速过程。在实际应用中,寻找最佳的JOIN顺序对于提升数据库性能至关重要。
在part1中我们知道了join两张表的基本操作和方法,但是我们日常的使用中,经常一个sql语句要join多张表,那么如果join是多个的时候应该怎么做呢,
Naive Way
左深树
最简单的办法就是将所有的table都放在一颗左深树中,进行依次join
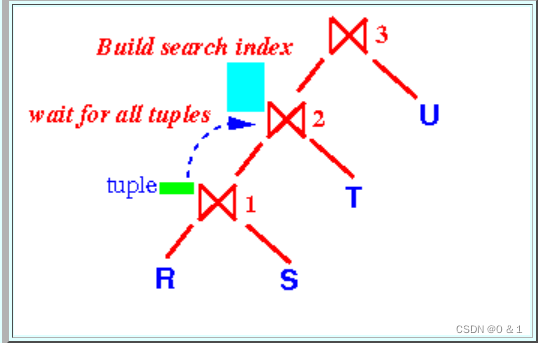
这里的左深树是,前面的两个tables的join结果作为下一个table的左兄弟,然后进行下一次join。
join方法我们都知道,对于左右两张表,我们要为左表进行一个哈希表的映射,放入内存。那么对于左深树而言,我们得到⋈1后,对⋈1进行哈希表的映射,这样一来当进行⋈2的时候,R和S的内存就可以被释放掉了。
并且内存中存放的是⋈1,我们只需要对T进行磁盘的读取操作就可以了。
右深树
那么我们来看看右深树
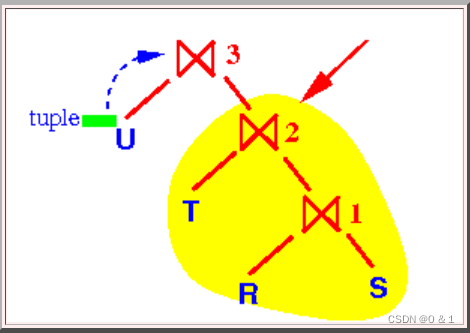
右深树,进行⋈3的操作时内存中存放的是U的哈希映射表,同事需要去磁盘中对T,R,S进行多次读取操作,这样一来大大的增加了对磁盘的读取操作。
左深树和右深树并不一定要理解为树的结果,其实更直接的理解是,将join的结果作为左表,存在内存中进行下一次join,那么我们就可以称这些表的顺序组成的树为左深树。‘
’
找到连接结果最小的结果
左深树确定了,那么每个table的连接顺序也非常影响join的速度,比如说R⋈S之后只剩下10条结果,而S⋈T之后剩下100条,那么很明显我们先进行R⋈S会更快。
pro3的part2就是让我们实现找到左深树的顺序连接,然后按照顺序进行join的操作。

















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









