









提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
定长顺序存储
typedef struct{
char str[maxSize+1];
int length;
}Str;
变长分配存储
typedef struct{
char* ch;
int length;
}Str;
基本操作
赋值
int strcpy(Str& str, char* ch){
if(str.ch){
free(str.ch);
}
int len = 0;
char* c = ch;
while(*c){
len++;
c++;
}
if(len == 0){
str.ch = NULL;
str.length = 0;
return 1;
}
str.ch = (char*)malloc(sizeof(char)*(len+1));
if(str.ch == NULL) //malloc失败
return 0;
c = ch;
for(int i = 0; i<=len; i++){
str.ch[i] = c;
c++;
}
str.length = len;
return 1;
}
取长度
int strlen(Str str){
return str.length;
}
比较
int strcmp(Str s1, Str s2){
for(int i = 0; i<s1.length && i<s2.length; i++){
if(s1.str[i] != s1.str[j){
return s1.str[i] - s2.str[i];
}
}
return s1.length - s2.length;
}
拼接
int strcat(Str &str, Str s1, Str s2){
if(str.ch){
free(str.ch);
str.ch = NULL;
}
str.ch = (char*)malloc(sizeof(char)*(s1.length + s2.length + 1));
if(str,ch == NULL){
return 0;
}
int i = 0;
while(i<s1.length){
str.ch[i] = s1.ch[i];
i++;
}
int j = 0;
while(j<=s2.length){ // <= 复制最后'\0'
str.ch[i+j] = s1.ch[j];
j++;
}
str.length = s1.length + s2.length;
return 1;
}
求子串
int substring(Str &substr, Str str, int pos, int len){
if(pos < 0 || pos > str.length || len < 0 || len >str.length){
return 0;
}
if(substr.ch){
free(substr.ch);
substr.ch = NULL;
}
if(len == 0){
substr.ch = NULL;
substr.length = 0;
return 1;
}
substr.ch = (char*)malloc(sizeof(char) * (len+1));
int i = pos, j = 0;
while(j<len){
substr.ch[j] = str.ch[i+j];
j++;
}
substr.ch[j] = '\0';
substr.length = len;
return 1;
}
串清空
int clear(Str& str){
if(str.ch){
free(str.ch);
str.ch = NULL;
}
str.length = 0;
return 1;
}
KMP算法
求next数组
F:P1P2…Pj-1Pj
最长公共前缀 FL:P1 P2…Pt-2 Pt-1
最长公共后缀 FR:Pj-t+1 Pj-t+2…Pj-2Pj-1

状态定义
t:当前F最长相等前后缀的 长度
next[j+1]:记录模式串第j+1个字符不匹配时,模式串中重新与主串比较的字符的下标位置
状态转移方程
n
e
x
t
[
j
+
1
]
=
{
t
+
1
p
t
=
p
j
n
e
x
t
[
t
]
+
1
p
t
≠
p
j
,
p
n
e
x
t
[
t
]
=
p
j
n
e
x
t
[
n
e
x
t
[
t
]
]
+
1
p
t
≠
p
j
,
p
n
e
x
t
[
t
]
≠
p
j
,
p
n
e
x
t
[
n
e
x
t
[
t
]
]
=
p
j
…
…
next[j+1]= \begin{cases} t+1 &p_t=p_j \\ next[t]+1 &p_t≠p_j, p_{next[t]}=p_j \\ next[next[t]]+1 &p_t≠p_j,p_{next[t]}≠p_j,p_{next[next[t]]}=p_j& \\ ……\\ \end{cases}
next[j+1]=⎩⎪⎪⎪⎨⎪⎪⎪⎧t+1next[t]+1next[next[t]]+1……pt=pjpt=pj,pnext[t]=pjpt=pj,pnext[t]=pj,pnext[next[t]]=pj
初始化
n e x t [ 1 ] = 0 next[1] = 0 next[1]=0
void getNext(Str substr, int next[]){
int j = 1, t = 0;
next[1] = 0;
while(j<substr.length){
if(t == 0 || substr.ch[j] == substr.ch[t]){
next[j+1] = t + 1;
j++;
t++;
}else{
t = next[t];
******************************************************************
*最长相等前后缀长度 更新为 该长度下不匹配时,重新比较的字符 在模式串中的位置*
******************************************************************
}
}
}
练习
在用KMP算法进行模式匹配时、模式串“ababaaababaa”的next数组值为
| 最长前后缀 | t | a | b | a | b | a | a | a | b | a | b | a | a | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | a | 0 | ||||||||||||
| 0 | b | 1 | ||||||||||||
| 0 | a | 1 | ||||||||||||
| a | 1 | b | 2 | |||||||||||
| ab | 2 | a | 3 | |||||||||||
| aba | 3 | a | 4 | |||||||||||
| a | 1 | a | 2 | |||||||||||
| a | 1 | b | 2 | |||||||||||
| ab | 2 | a | 3 | |||||||||||
| aba | 3 | b | 4 | |||||||||||
| abab | 4 | a | 5 | |||||||||||
| ababa | 5 | a | 6 |
Answer: 0,1,1,2,3,4,2,2,3,4,5,6
KMP算法
假定存储序号为1……n, i 指向主串,j 指向模式串
i 不回溯
j 超出范围 ⇨ 匹配成功 ⇨ 返回模式串在主串中的初始位置
int KMP(){
int i = 1, j = 1;
while(i<=str.length && j <= strsub.length){
if(j == 0 || str.ch[i] == substr.ch[j]){
i++;
j++;
}else{
j = next[j];
}
}
if(j>substr.length){
return i - substr.length;
}else{
return 0;
}
}
KMP的改进
原因
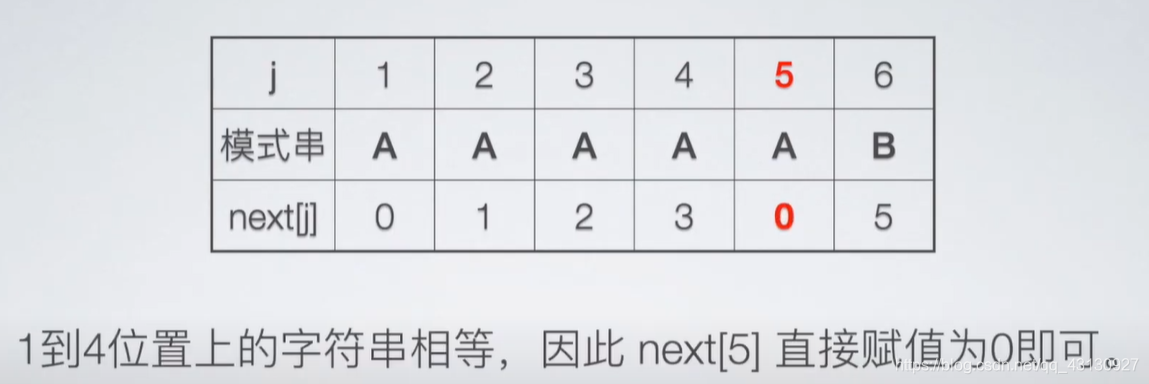
j = 5 j = 5 j=5 时
n e x t [ 5 ] = n e x t [ 4 ] next [5] = next[4] next[5]=next[4]
n e x t [ 4 ] = n e x t [ 3 ] next [4] = next[3] next[4]=next[3]
n e x t [ 3 ] = n e x t [ 2 ] next [3] = next[2] next[3]=next[2]
n e x t [ 2 ] = n e x t [ 1 ] next [2] = next[1] next[2]=next[1]
问题
过多的回溯
思考
能否记忆化上个
n
e
x
t
[
j
]
next[j]
next[j]


状态转移方程
n
e
x
t
v
a
l
[
j
]
=
{
0
j
=
1
n
e
x
t
[
j
]
p
j
≠
p
n
e
x
t
[
j
]
n
e
x
t
v
a
l
[
n
e
x
t
[
j
]
]
p
j
=
p
n
e
x
t
[
j
]
nextval[j]= \begin{cases} 0 &j=1 \\ next[j] &p_j≠p_{next[j]}\\ nextval[next[j]] &p_j=p_{next[j]} \\ \end{cases}
nextval[j]=⎩⎪⎨⎪⎧0next[j]nextval[next[j]]j=1pj=pnext[j]pj=pnext[j]
代码
void getnextval(Str substr, int nextval[]){
int j = 1, t = 0;
nextval[1] = 0;
while(j<substr,length){
if(t == 0 || substr.ch[j] == substr.ch[t]){
j++;
t++;
if(substr.ch[j] != substr.ch[t]){
nextval[j] = t;
}else{
nextval[j] = nextval[t];
}
}else{
t = nextval[t];
}
}
}
练习
在用KMP算法进行模式匹配时、模式串“ababaab”的nextval数组值为
首先求出next数组
| 模式串 | a | b | a | b | a | a | b |
|---|---|---|---|---|---|---|---|
| j j j | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| n e x t [ j ] next[j] next[j] | 0 | 1 | 1 | 2 | 3 | 4 | 2 |
</tr>
| next[j] | next[j]字符 | 当前字符 | 是否相等 | a | b | a | b | a | a | b |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | a | 0 | ||||||||
| 1 | a | b | ✗ | next[2] | ||||||
| 1 | a | a | ✔ | nextval[next[3]] | ||||||
| 2 | b | b | ✔ | nextval[next[4]] | ||||||
| 3 | a | a | ✔ | nextval[next[5]] | ||||||
| 4 | b | a | ✗ | next[6] | ||||||
| 2 | b | b | ✔ | nextval[next[5]] |
Answer: 0,1,0,1,0,4,1
综合应用题
-
将串str中所有值为ch1的字符转换成ch2的字符,如果str为空串,或者串中不含值为ch1的字符则什么都不做
void swap(Str &str, char ch1, char ch2){ for(int i = 0; i<str.length; i++){ if(str.ch[i] == ch1){ str.ch[i] = ch2; } } } -
实现串str的逆转函数,如果str为空串,则什么都不做
void swap(char &ch1, char &ch2){ char temp = ch1; ch1 = ch2; ch2 = temp; } void reverse(Str &str){ int i = 0, j = str.length - 1; while(i<j){ swap(str.ch[i], str.ch[j]); i++;j--; } } -
删除str中值为ch的所有字符,如果str为空串,或者串中不含值为ch的字符,则什么都不做
void delete(Str &str, char ch){ if(str.length == 0) return; int sum = 0, i, j; for(i = 0; i<str.length; i++){ if(str.ch[i] == ch){ sum++; } } if(sum != 0){ char *temp_ch = (char*)malloc(sizeof(char)*(str.length - sum+1)){ for(i = 0, j = 0; i<str.length; i++){ if(str.ch[i] != ch){ temp_ch[j++] = str.ch[i]; } } temp_ch[j] = '\0'; str.length = str.length - sum; free(str.ch); str.ch = temp_ch; } } } -
从串str中的pos位置起,求出与 substr串匹配的子串的位置,如果str为空串,或者串中不含与sbsr匹配的子串,则返回-1做标记
int KMP(Str str, Str substr, int pos){ int i = pos, j = 1; while(i<=str.length && j <= substr.length){ if(j == 0 || str.ch[i] == str.ch[j]){ ++i; ++j; }else{ j = next[j]; } } if(j > substr.length) return i - substr.length; else return -1; } -
采用定长顺序存储表示串,编写一个函数,删除串中从下标为 i i i的字符开始的 j j j个字符,如果下标为 i i i的字符后没有足够的 j j j个字符,则有几个删除几个
void delete(Str& str, int i, int j){ if(i<str.length && i>=0 && j>=0){ for(int k = i + j; k<str.length; k++){ str.ch[k - j] = str.ch[k]; } ************************************************** str.length -= (str.length-i<j? str.length - i: j); ************************************************** str.ch[str.length] = '\0'; } } -
采用顺序存储方式存储串,编写一个函数,将串 s t r 1 str1 str1中的下标 i i i到下标 j j j之间的字符(包括i和两个位置上的字符)用 s t r 2 str2 str2串替换
int concat(Str& str, Str str1, Str str2){ if(str.ch){ free(str.ch); str.ch = NULL; } str.ch = (char*)malloc(sizeof(char) * (str1.length + str2.length + 1)) if(str.ch == NULL){ return false; } int i = 0; while(i<str1.length){ str.ch[i] = str1.ch[i]; i++; } int j = 0; while(j<str2.length){ str.ch[i+j] = str2.ch[j]; j++; } str.length = str1.length + str2.length; return true; } int subString(Str &substr, Str str, int pos, int len){ if(pos<0 || pos>=str.length || len<0 || len>str.length-pos) return false; if(substr.ch){ free(substr.ch) substr.ch = NULL; } if(len == 0){ substr.ch == NULL; substr.length = 0; return true; }else{ substr.ch = (char*)malloc(sizeof(char) * (len + 1)); for(int i = 0; i<len; i++){ substr.ch[i] = str.ch[pos+i]; } substr.ch[len+pos] = '\0'; return true; } } int stuff(Str& str1, Str str2, int i, int j){ Str strl1; strl1.ch = NULL; strl1.length = 0; Str strl2; strl2.ch = NULL; strl2.length = 0; Str temp_str; if(!subString(strl1, str1), 0, i) return 0; if(!subString(strl2, str1, j+1, str1.length-j-1)) return 0; if(!concat(temp_str, strl1, str2)) return 0; if(!concat(str1, temp_str, strl2)) return 0; return 1; } -
编写一个函数,计算一个子串在一个主串中出现的次数,如果该子串不出现,则返回0。本题不需要考虑子串重叠,如:主串为aaaa,子串为aaa,考虑子串重叠结果为2,不考虑子串重叠结果为1
int count(Str str, Str substr){ int i = 1, j = 1, k = 1, sum = 0; while(i<=str.length){ if(str.ch[i] == substr.ch[j]){ i++;j++; }else{ j = 1; i = ++k; } if(j>substr.length){ j = 1; sum++; } } return sum; } -
构造的链表结点数据结构(每个结点内存储一个字符),编写一个函数,找出串 s t r 1 str1 str1中第一个不在 s t r 2 str2 str2中出现的字符
typedef struct SNode{ char data; Struct SNode *next; } char findfirst(SNode *str1, SNode *str2){ for(SNode *p = str1; p!=NULL; p = p->next){ bool flag = false; for(SNode *q = str2; q!=NULL; q = q->next){ if(p->data == q->data){ flag = true; break; } } if(flag == false){ return p->data; } } return '\0'; }
总结
- 😄
- 😢

















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









