







文章目录
ABSTRACT
本文研究了在自动语音识别 (ASR) 中从个性化说话人适应神经网络声学模型 (AM) 中有效检索说话人信息的方法。 这个问题在 ASR 声学模型的联合学习环境中尤为重要,其中基于从多个客户端接收到的更新在服务器上学习全局模型。 我们提出了一种方法来分析神经网络 AMs 中的信息,该方法基于所谓的指标数据集上的神经网络足迹。 使用这种方法,我们开发了两个攻击模型,旨在从更新的个性化模型中推断说话者身份,而无需访问实际用户的语音数据。 TED-LIUM 3 语料库上的实验表明,所提出的方法非常有效,可以提供 1-2% 的相等错误率 (EER)。
这里边出现了一个数据集TED-LIUM 3
1. INTRODUCTION
共享模型更新,即梯度信息,而不是原始用户数据,旨在保护在设备本地处理的用户个人数据。
这样很容易受到攻击,包括:1.成员推断攻击;2.GAN推断攻击等。同样的我们也提出了保护的方式:1.secure multiparty computation安全多方计算;2.differential privacy差分隐私(在用户参数中添加噪声,但这种方法会降低精确度)。例如完全同态加密和安全多方计算在加密域中执行计算,但是这些方法会增加计算复杂度。
语音隐私保护的替代方法包括用于环境声音分析的删除方法,以及旨在抑制语音信号中的个人可识别信息保持所有其他属性不变的匿名化方法。并且这些方法可以混合使用。
通过分析可以从本地更新的用户数据的个性化 AM (声学模型)中检索到的说话者信息,作者开发了两个隐私攻击模型,它们直接对更新的模型参数进行操作,而无需访问实际用户的数据。提出的方法能有效和轻松地从适应的 AM 中检索说话者信息。所提出方法的主要思想是使用外部指标数据集来分析 AM 在该数据上的足迹。这项工作的另一个重要贡献是了解说话人信息如何在适应的 NN(神经网络) AM 中分布。
2. FEDERATED LEARNING FOR ASR ACOUSTIC MODELS
假设数据来自多个远程设备,
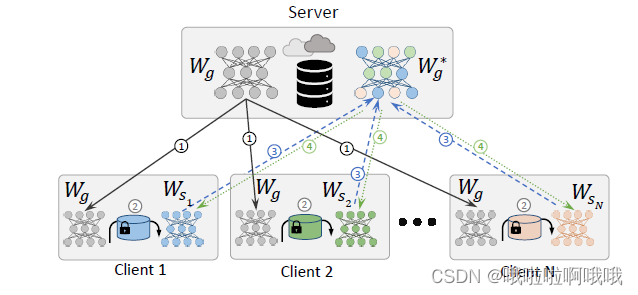
3. ATTACK MODELS
3.1. Privacy preservation scenario
服务器和客户端之间没有语音数据交换,客户端和服务器之间(或某些客户端之间)只传输模型更新。攻击者旨在使用服务器拥有的信息攻击用户。 他们可以访问一些更新的个性化模型。
假设可以接触到的数据:
1.初始全局 W g W_{g} Wg。
2.加入FL系统的目标说话者 s s s的个性化模型 W s W_{s} Ws。通过使用说话人数据对 W g W_{g} Wg进行微调,从全局模型 W g W_{g} W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









