






MySQL索引的类型分三种
- B+树索引
- Hash索引
- 全文索引
这次文章主要介绍我们最常用的InnoDB搜索引擎中的B+树索引。说到B+树索引我们就不得不从二叉树、二叉平衡树、B树开始说起,B+树就是基于这三棵树的基础上衍变过来的。
二叉树结构
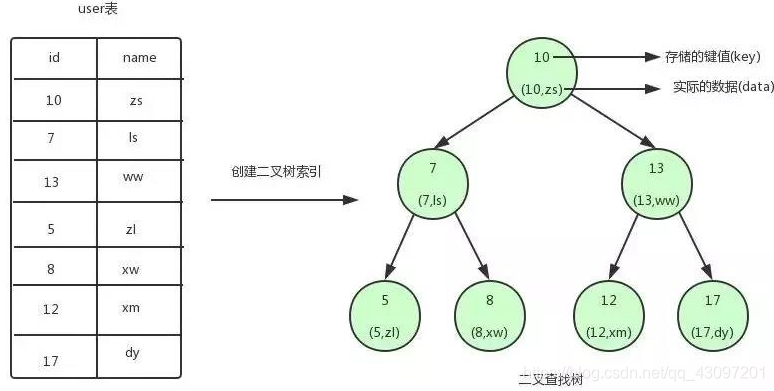
二叉树结构特征介绍
- 二叉树如同所示,每个圆点都代表着一个节点,其中每个节点都对应有一个
K-V | 键值-数据对,图示中的key对应的是我们user表中的用户id,每个键对应的数据就是user表中的行数据。 - 可以从图中看到,二叉树的每个左子节点的键值均小于当前键值,右子节点的键值大于当前键值。
- 一般把顶部的结点称为根节点,没有子节点的结点称为叶节点。
二叉树查找数据的流程 (以查找id = 12的数据为例)
- 首先,查询是从根节点开始的。id = 12的键值大于当前根节点10,因此我们的当前节点从10处向右移动到了13处。
- 随后,继续用id = 12的键值与当前键值进行比较,发现当前键值为13是大于id = 12的键值的,我们的当前节点就需要继续向左往子节点移动。
- 当前节点移动到键值为12处之后,与id = 12的键值进行比较,此时我们当前节点的键值与其相等,满足条件,取出当前键值所对应的数据内容,即id = 12,name = xm;
总结:利用二叉树我们仅查询了三次便查询出了结果,倘若扫表查询的话,最少都需要6次才能确定结果。
从二叉树进化到平衡二叉树
虽然二叉树相比于扫表,少了很多次查询次数,但是遇到二叉树成为链表结构时,那就很难受了,如下图

由图可知,当我们需要查询id = 17的用户信息时,我们总共都需要扫描七次数据才能查询到结果。这种链表结构的二叉树,无异于扫全表了。导致这种情况最主要的原因还是因为这颗二叉树的高度太高了,从而导致查询效率太低。由此才引出了平衡二叉树的概念,其实平衡二叉树只是在二叉树的基础上,新增了左右子节点树的高度差不超过1的规定。
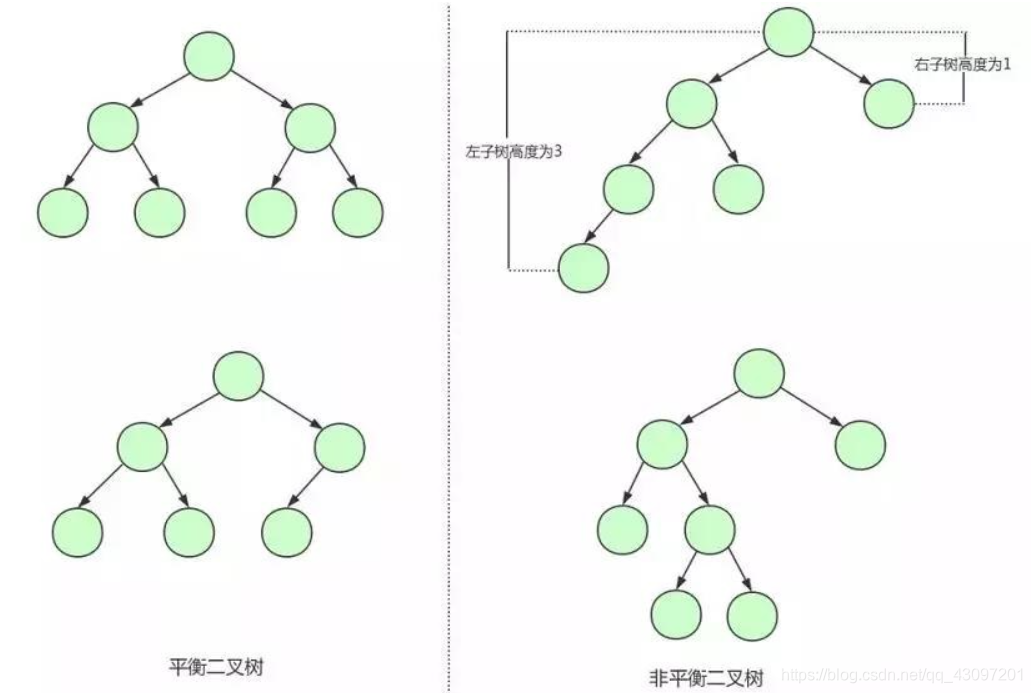
由此可知平衡二叉树会一直保持左右子节点的树高差不超过1,其保证了树的结构是平衡的,当我们插入、删除的数据会导致这棵树不平衡的时候,这颗平衡二叉树的节点是会进行调整以保证平衡的。因此,平衡二叉树相比于二叉树其更为稳定,查询速度也更快
再从平衡二叉树进化到B树
数据库一般都会把索引和数据都存储在磁盘中的,相比于存储在内存中,存储在磁盘中的读取速度较慢,并且读取磁盘的时候是按磁盘块的方式来读取的,而不是一条一条读取的。因此我们要想办法,在存储数据到磁盘块的时候尽量存储多的数据内容,以尽量减少从磁盘中读取数据的次数。
由于二叉树的结构,其子节点只能存储只能存储一个
k-v | 键值-数据对,那么在磁盘块中只能存储一个k-v | 键值-数据对,如果是海量数据进行IO的时候,其是十分恐怖的!这种存储结构的查询效率极低!
为了能解决这种存储结构所带来的弊端,我们需要一个单节点可以存储多个k-v | 键值数据对 的平衡树。
优化存储结构,引出B树
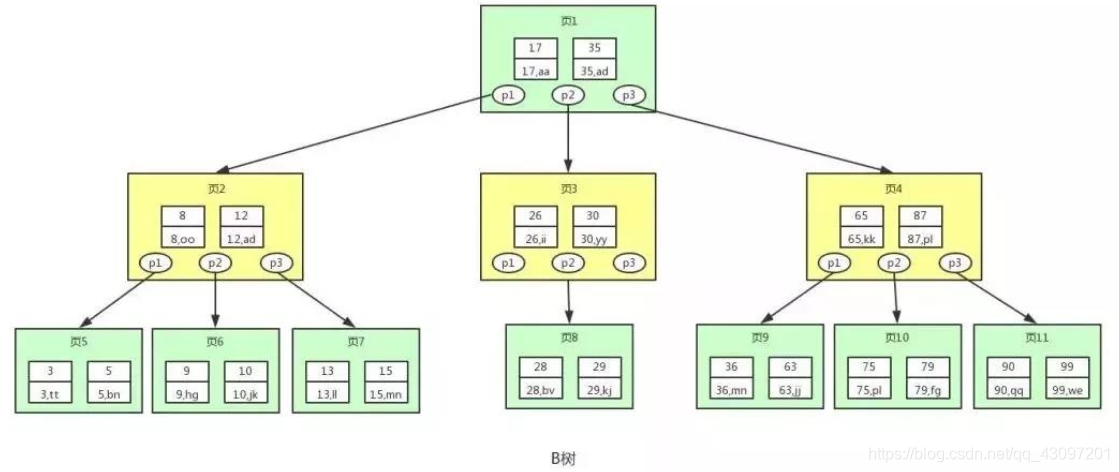
分析结构
- P节点是指向子节点的指针,每个节点在此处称为页,页即为磁盘中的磁盘块。在MySQL中读取数据的基本单位就是页。
- B树相比于平衡树,其节点(页)中存储的
k-v | 键值数据对更多,每个节点(页)也拥有更多的子节点,子节点的个数称为阶。如上图,就为三阶B树。 - 相比于平衡树,B树查找磁盘块的次数会少很多,IO效率也会高很多。
B树查询流程分析(以查找id = 28的用户数据为例)
- 首先从根节点,页1开始查找,id = 28的键值处于 [ 17, 35 ] 之间,那么我们就可以在页1中获取到指针p2,指针p2指向页3
- 再将id = 28的键值和页3中的 [ 26 , 30 ] 进行比较,发现id = 28的键值处于它们中间,因此再在页3中获取到指针p2找到页8
- 将id = 28的键值与页8中的 [28 , 29] 进行比较,发现id = 28的键值有匹配结果,获取到 (28 , bv) 的结果。
究极进化之,B+树
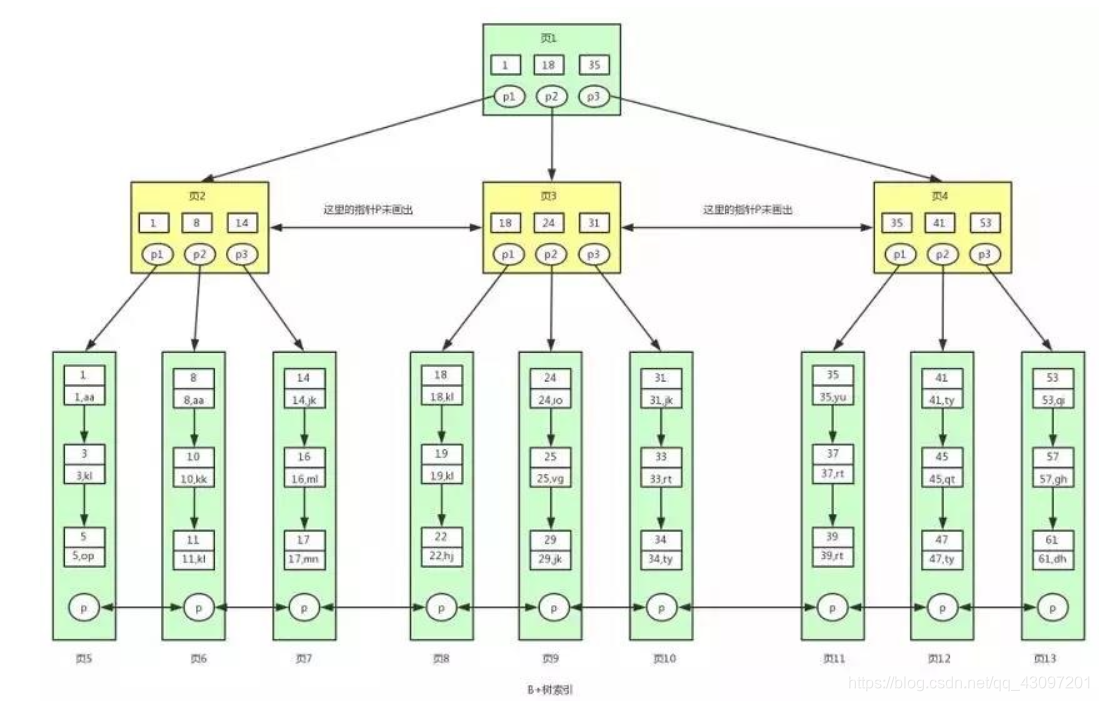
对比B+树和B树的异同之处
- B+树的非叶子节点都是不存储数据的,而B树非叶子节点也存储数据。
之所以这么做,是因为在MySQL中页的大小是固定的,InnoDB中页的默认值为16KB。这样在一个页中就可以存储更多的键值,则树的阶数(节点的子节点数)越大,树也会更矮胖一些,这样查找数据时对磁盘进行的IO次数会更少,查询效率更高。 - B+树索引的所有数据都存储在叶子节点,并且是按照顺序排序的。并且B+树的页之间是有双向链表
互通的,叶子节点中的数据是通过单向链表链接的。 - B+树索引就是InnoDB中B+树索引的真正方式,准确来说是聚簇索引。
聚簇索引 vs 非聚簇索引
聚簇索引
- 以InnoDB作为存储引擎的表,以主键作为键值生成B+树的索引称为聚簇索引。
聚簇索引是默认的,即便创建的表中没有主键,MySQL也会默认的帮你创建唯一且不为空的索引列作为主键,再不行则会隐式创建一个主键,从而生成聚簇索引 - InnoDB中的B+树,是把数据存放在叶子节点中的,叶子节点的键值对应主键,同时叶子节点是存储所有数据的。
- 以主键作为索引键值所构建的B+树索引,则为聚簇索引。
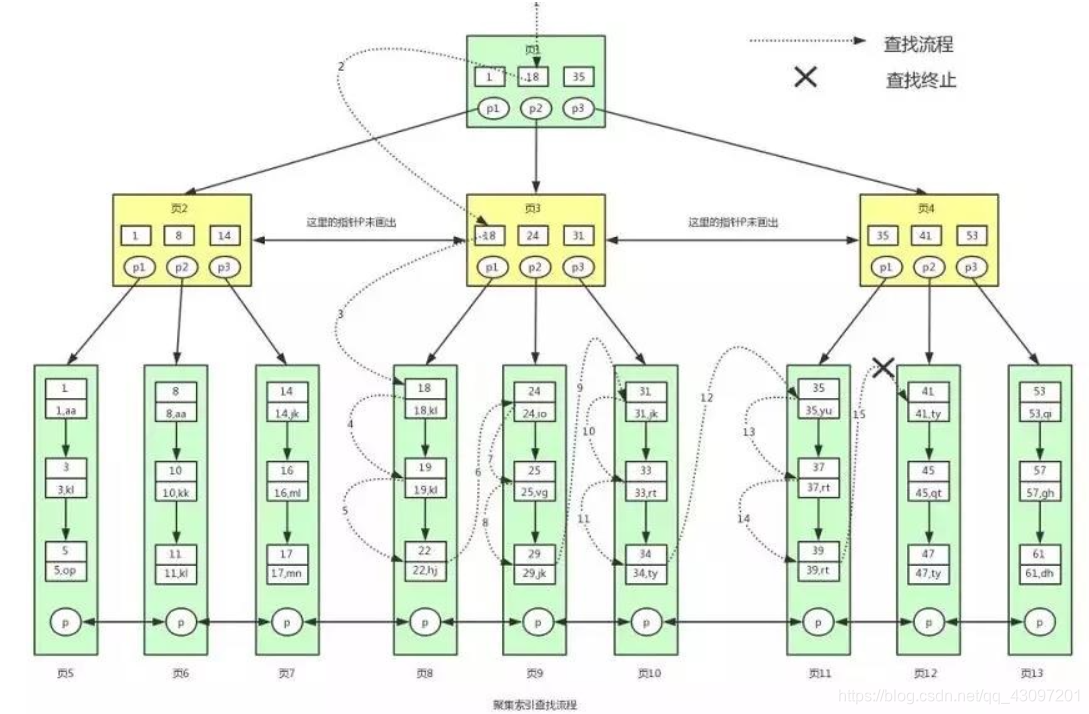
聚簇索引查找数据的流程,查找id处于 [18 , 40] 之间的数据
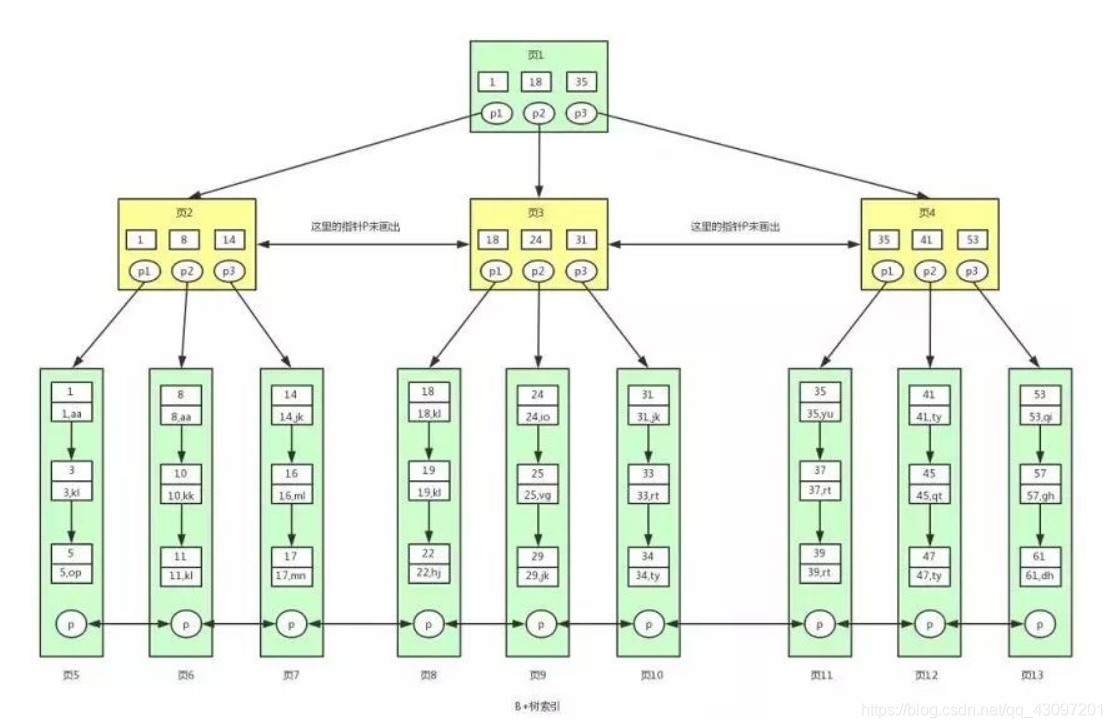
- 首先,根节点是常驻于内存的,并且读取数据的时候也是从根节点开始读取,此时读取页1,查找 [18 , 40] 范围的值,首先从页1中的18开始。此时刚好获取到页1中的指针p2,定位到页3。
- 此时我们拿着p2指针,在磁盘中读取到了页3。然后在磁盘中读到页3后将其放入内存,然后查找页中的数据,恰好找到键值18的数据,拿到页3中的指针p1,定位到页8。
- 此时页8恰好不在内存中,需要在磁盘中将页8读取到内存中,因为页中的数据是以链表进行连接的,而且键值是顺序排放的,此时可以用二分查找法定位到键值18,此时找到一条满足条件的数据,就是键值18对应的数据。
- 由于此处我们是进行范围查找的,而且所有的数据都是存储在叶子节点中的,我们可以在当前页8中,继续对键值进行遍历查找,获取范围内的有效键值数据对。因此在页8中我们一直找到键值为22的数据,页8中的所有数据取完了。此时,我们要继续用页8的指针去读取页9的数据。
- 由于页9不在内存中,页8的指针需要去磁盘中扫描页9的内容,并将其读取到内存中来,如此循环一直查找到页12,发现41大于40不满足条件,最终结束查询。具体的流程图如下:
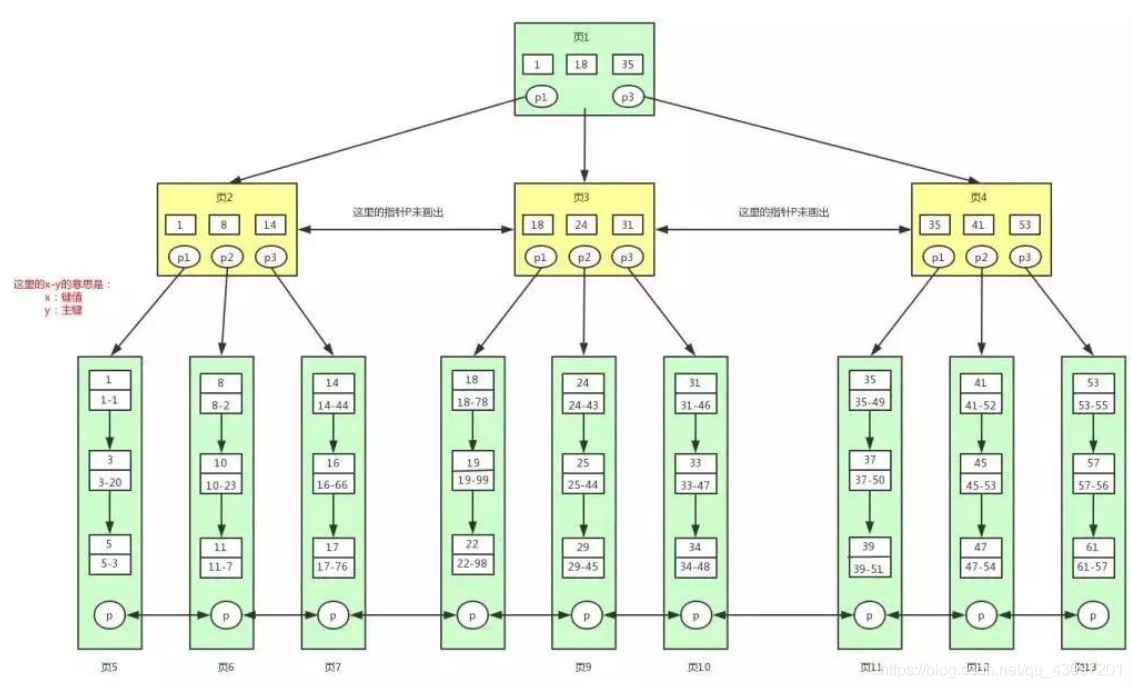
非聚簇索引
- 以主键外的键值索引所构建的B+树索引,则为非聚簇索引。
- 非聚簇索引和聚簇索引最大的区别是,非聚簇索引的叶子节点中并不存储数据内容,其存储的内容是主键值。因此查找数据的话,非聚簇索引还需要根据当前键值下,所存储的主键值去聚簇索引中查找数据,这个过程成为
回表。
非聚簇索引查找流程,在非聚簇索引中,不再存储数据了,而是存储
索引键值-主键的内容
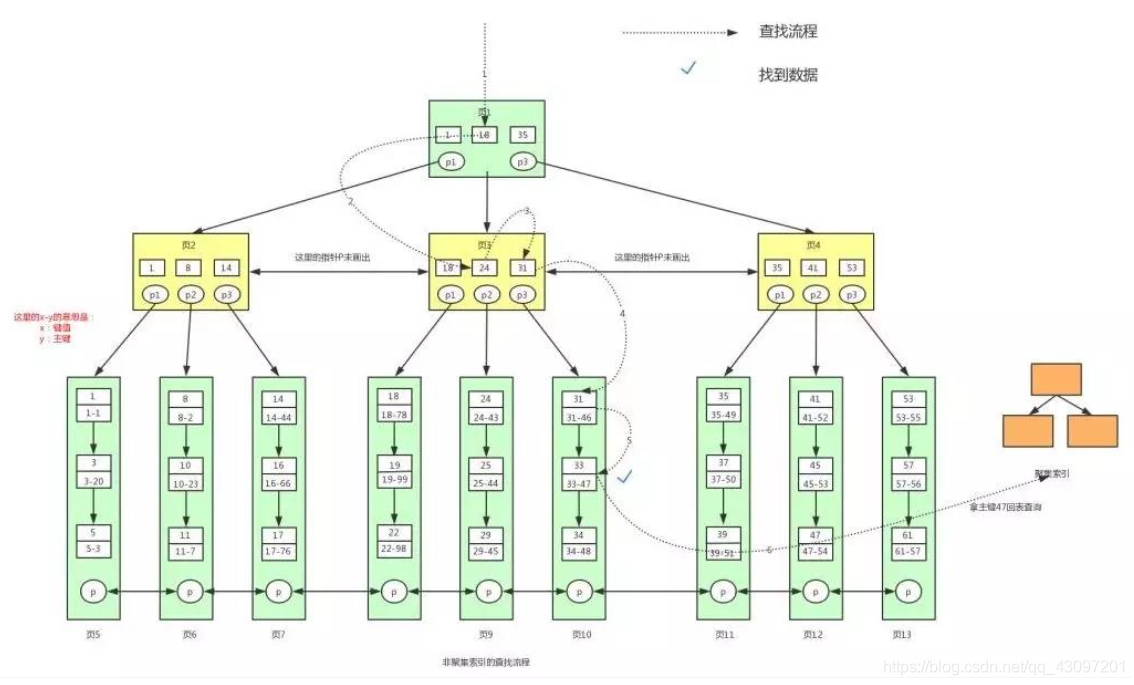
倘若查找索引值为33的数据,其流程图如下,其过程跟聚簇索引是一样的,只不过最后查询的
索引键值-主键需要用其主键到聚簇索引中进行查询。(由非聚簇索引定位到 索引值-主键 之后,就可以到聚簇索引中查找数据,这个过程叫回表)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









