




首先创建用于正则表达式练习的数据生成器
from random import randrange,choice
#randrange:在取值范围内按步长随机选择一个数(步长默认为1)
#choice:在序列中随机抽取一个元素
from string import ascii_lowercase as lc#字符串常量:小写字母’abcdefghijklmnopqrstuvwxyz’
from sys import maxsize
from time import ctime
import re
file = open('redata.txt','w')
tlds = ('com','edu','net','org','gov')
for i in range(randrange(5,11)):
dtint = randrange(maxsize)
dint = dtint//500000000
dtstr = ctime(dint)
llen = randrange(4,8)
login = ''.join(choice(lc) for i in range(llen))
dlen = randrange(llen,13)
dom = ''.join(choice(lc) for i in range(dlen))
new_str = dtstr + '::' + login + '@' + dom + '.' + choice(tlds) + '::' + str(dtint) + '-' + str(llen)+ '-' + str(dlen)
file.writelines(new_str + '\n')
file.close()生成的redata.txt文件如图所示:
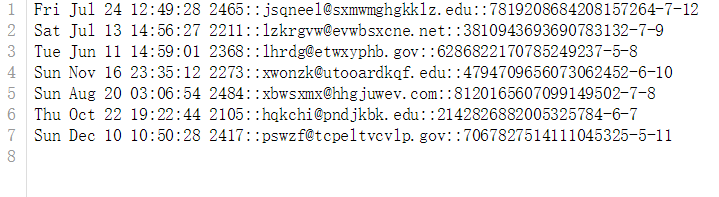
现在针对生成的数据进行正则表达式创建的练习:
1.提取每行中完整的时间戳
re_1 = '(\w{3}\s\w{3}\s\d{2}\s\d{2}\:\d{2}\:\d{2})'
file = open('redata.txt','r')
for i in file:
print(re.search(re_1,i).group())output:
Fri Jul 24 12:49:28
Sat Jul 13 14:56:27
Tue Jun 11 14:59:01
Sun Nov 16 23:35:12
Sun Aug 20 03:06:54
Thu Oct 22 19:22:44
Sun Dec 10 10:50:28
In [115]:
2.提取每行中完整的电子邮件地址
re_2 = '[A-Za-z]+\@[A-Za-z]+\.(?:(com)|(net)|(edu)|(org)|(gov))'
file = open('redata.txt','r')
for i in file:
print(re.search(re_2,i).group())output
jsqneel@sxmwmghgkklz.edu
lzkrgvw@evwbsxcne.net
lhrdg@etwxyphb.gov
xwonzk@utooardkqf.edu
xbwsxmx@hhgjuwev.com
hqkchi@pndjkbk.edu
pswzf@tcpeltvcvlp.gov
3.仅仅提取时间戳中的月份
re_3 = '\w{3}\s(\w{3})\s\d{2}'
file = open('redata.txt','r')
for i in file:
print(re.search(re_3,i).groups())output
('Jul',)
('Jul',)
('Jun',)
('Nov',)
('Aug',)
('Oct',)
('Dec',)
4.使用你的电子邮件地址替换每一行数据中的电子邮件地址
Way1
re_2 = '[A-Za-z]+\@[A-Za-z]+\.(?:(com)|(net)|(edu)|(org)|(gov))'
file = open('redata.txt','r')
email = []
for i in file:
search_ans = re.search(re_2,i).group()
begin = i.find(search_ans)
length = len(search_ans)
i = i[:begin]+'1137051592@qq.com'+i[begin+length:]Way2
pattern = re.compile(r'\w*@\w*\.\w{3}')
for i in file:
print(pattern.sub('1137051592@qq.com',i))output
Fri Jul 24 12:49:28 2465::1137051592@qq.com::7819208684208157264-7-12
Sat Jul 13 14:56:27 2211::1137051592@qq.com::3810943693690783132-7-9
Tue Jun 11 14:59:01 2368::1137051592@qq.com::6286822170785249237-5-8
Sun Nov 16 23:35:12 2273::1137051592@qq.com::4794709656073062452-6-10
Sun Aug 20 03:06:54 2484::1137051592@qq.com::8120165607099149502-7-8
Thu Oct 22 19:22:44 2105::1137051592@qq.com::2142826882005325784-6-7
Sun Dec 10 10:50:28 2417::1137051592@qq.com::7067827514111045325-5-11
5.提取并捕获html标签内容
html标签,例:
<a href = 'www.google.com'>Content</a>提取标签内容:
html = '<a href="www.google.com">Content</a>'
re_4 = '<(?:[^>]*)>([^<]+)</a>'
re.search(re_4,html).groups()output
('Content',)
其中,[^>]表示匹配除’>'以外所有字符,‘?:'表示匹配但不获取匹配结果
注意: 要注意区分’/‘和’\’,其中转义符为’\’

















 2330
2330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









