







概述
为什么要优化:
应用的吞吐量一般出现在数据库处理速度上
随着应用的使用数据量不断增多,数据库处理压力主键增大
关系型数据库的数据存储在磁盘上,读写数据较慢(与内存数据库比较)
优化手段:
- 第一步是表字段的设计,考虑更优的存储计算
- 利用好MySQL自身提供的功能,如 存储引擎的选择、索引等
- 横向扩展:MySQL读写分离
- SQL语句的优化(收效甚微)
字段设计
字段类型的选择,设计规范,范式,常见设计案例
在设计表字段建议,使用8字节的主键bigint,而不是直接使用int来做主键
varchar 不存的时候不占空间,存多长数据就占多少空间
尽量使用整型表示字符串,这样能根节省存储空间
存储ip的方式:
INET_ATON(str),address to number
INET_NTOA(number),number to address
数据库字段:定长和非定长数据类型的选择
decimal不会损失精度,存储空间会随数据的增大而增大。double占用固定空间,较大数的存储会损失精度。非定长的还有varchar、text
定点数decimal:price decimal(8,2)有2位小数的定点数,定点数支持很大的数(甚至是超过int,bigint存储范围的数)
小单位大数额避免出现小数:元->分
原则:尽可能选择小的数据类型和指定短的长度
尽可能使用 not null
非null字段的处理要比null字段的处理高效些!且不需要判断是否为null。
null在MySQL中,不好处理,存储需要额外空间,运算也需要特殊的运算符。如select null = null和select null <> null(<>为不等号)有着同样的结果,只能通过is null和is not null来判断字段是否为null。
如何存储?MySQL中每条记录都需要额外的存储空间,表示每个字段是否为null。因此通常使用特殊的数据进行占位,比如int not null default 0、string not null default ‘’
字段注释要完整,见名知意
单表字段不宜过多:二三十个就极限了
可以预留字段
在使用以上原则之前首先要满足业务需求
命名规则
表名:
1、要用前缀,但不要用无意义的前缀
2、下划线分隔
3、全小写
列名规则:
1、一般不用前缀(当和关键词冲突的可以考虑加前缀区别)
2、下划线分隔
3、全小写不管是表名设计还是列名设计,都不要使用拼音来命名,过一段时间就完全不记得了,就用英文,即使英语不好设计的时候也建议设置为英文。
符合三范式数据库表
1NF: 列不可分。每一列都是不可分割的基本数据项,如这样的设计就不合理,姓名(王五,wangwu)
2NF: 1NF的基础上面,非主属性完全依赖于主关键字,如学生姓名(非主属性)就是依赖于学号(主属性)的。目的是为了 消除对主键的部分依赖。
3NF: 属性不依赖于其它非主属性 , 消除传递依赖,如这样的设计就不合理,学号做主键,学生课程表(学号=课程),当学号修改,对应的课程表也需要修改,这就是属于传递依赖
BCNF: 符合3NF,每个表中只有一个候选键
4NF: 没有多值依赖
由于学号不能做主键,那用什么做主键?首先就有这样的规则:不要用业务规则来做主键,主键就应该和业务无关。
如经常用的的order_no(业务订单号),即使是唯一的,也不建议做主键的,容易产生传递依赖的问题,这样就不符合第三范式了。
存储引擎选择
关于存储引擎可以看这篇博客:mysql存储引擎
正常使用 InnoDB 就好了。主要是记住他们之间的差异
索引优化
关于索引可以直接看我这篇博客:索引使用详解
水平切分和垂直切分
水平分割:通过建立结构相同的几张表分别存储数据
垂直分割:将经常一起使用的字段放在一个单独的表中,分割后的表记录之间是一一对应关系。
分表原意
- 为数据库减压
- 分区算法局限
- 数据库支持不完善(5.1之后mysql才支持分区操作)
id重复的解决方案
- 借用第三方应用如
memcache、redis的id自增器 - 单独建一张只包含id一个字段的表,每次自增该字段作为数据记录的
id
MySql读写分类实现横向扩展
横向扩展:从根本上(单机的硬件处理能力有限)提升数据库性能 。由此而生的相关技术:读写分离、负载均衡
Centos7搭建mysql集群 读写分离 主从复制
springBoot 使用AOP完成多数据源配置。写用主库,读用从库
典型Sql
线上DDL
DDL(Database Definition Language)是指数据库表结构的定义(create table)和维护(alter table)的语言。在线上执行DDL,在低于MySQL5.6版本时会导致全表被独占锁定,此时表处于维护、不可操作状态,这会导致该期间对该表的所有访问无法响应。但是在MySQL5.6之后,支持Online DDL,大大缩短了锁定时间。
优化技巧是采用的维护表结构的DDL(比如增加一列,或者增加一个索引),是copy策略。思路:创建一个满足新结构的新表,将旧表数据逐条导入(复制)到新表中,以保证一次性锁定的内容少(锁定的是正在导入的数据),同时旧表上可以执行其他任务。导入的过程中,将对旧表的所有操作以日志的形式记录下来,导入完毕后,将更新日志在新表上再执行一遍(确保一致性)。最后,新表替换旧表(在应用程序中完成,或者是数据库的rename,视图完成)。
但随着MySQL的升级,这个问题几乎淡化了。
数据库多语句导入
在恢复数据时,可能会导入大量的数据。此时为了快速导入,需要掌握一些技巧:
1、导入的时候 先禁用索引和约束
alter table table-name disable keys
待数据导入完成之后,再开启索引和约束,一次性创建索引
alter table table-name enable keys
2、数据库如果使用的引擎是Innodb,那么它默认会给每条写指令加上事务(这也会消耗一定的时间),因此建议先手动开启事务,再执行一定量的批量导入,最后手动提交事务
START TRANSACTION;
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
...
COMMIT;
3、如果批量导入的SQL指令格式相同只是数据不同,那么你应该先prepare预编译一下,这样也能节省很多重复编译的时间。
limit offset,rows
尽量保证不要出现大的offset,比如limit 10000,10相当于对已查询出来的行数弃掉前10000行后再取10行,完全可以加一些条件过滤一下(完成筛选),而不应该使用limit跳过已查询到的数据。这是一个offset做无用功的问题。对应实际工程中,要避免出现大页码的情况,尽量引导用户做条件过滤。
select * 要少用
即尽量选择自己需要的字段select,但这个影响不是很大,因为网络传输多了几十上百字节也没多少延时,并且现在流行的ORM框架都是用的select *,只是我们在设计表的时候注意将大数据量的字段分离,比如商品详情可以单独抽离出一张商品详情表,这样在查看商品简略页面时的加载速度就不会有影响了。
order by rand()不要用
它的逻辑就是随机排序(为每条数据生成一个随机数,然后根据随机数大小进行排序)。如select * from student order by rand() limit 5的执行效率就很低,因为它为表中的每条数据都生成随机数并进行排序,而我们只要前5条。
解决思路:在应用程序中,将随机的主键生成好,去数据库中利用主键检索。
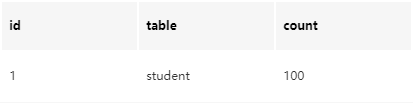
count(*)
在MyISAM存储引擎中,会自动记录表的行数,因此使用count(*)能够快速返回。而Innodb内部没有这样一个计数器,需要我们手动统计记录数量,解决思路就是单独使用一张表:
limit 1
如果可以确定仅仅检索一条,建议加上limit 1,其实ORM框架帮我们做到了这一点(查询单条的操作都会自动加上limit 1)。
Join语句使用
能不能使用join语句?
1、如果可以使用Index Nested-Loop Join算法,也就是说可以用上被驱动表上的索引,其实是没问题的;
2、如果使用Block Nested-Loop Join算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用。
所以你在判断要不要使用join语句时,就是看explain结果里面,Extra字段里面有没有出现“Block Nested Loop”字样。
如果要使用join,应该选择大表做驱动表还是选择小表做驱动表?
1、如果是Index Nested-Loop Join算法,应该选择小表做驱动表;
2、如果是Block Nested-Loop Join算法:
- 在join_buffer_size足够大的时候,是一样的;
- 在join_buffer_size不够大的时候(这种情况更常见),应该选择小表做驱动表。
所以,这个问题的结论就是,总是应该使用小表做驱动表。
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与join的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
典型的服务器配置
以下的配置全都取决于实际的运行环境
max_connections,最大客户端连接数
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
table_open_cache,表文件句柄缓存(表数据是存储在磁盘上的,缓存磁盘文件的句柄方便打开文件读取数据)
mysql> show variables like 'table_open_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| table_open_cache | 2000 |
+------------------+-------+
key_buffer_size,索引缓存大小(将从磁盘上读取的索引缓存到内存,可以设置大一些,有利于快速检索)
mysql> show variables like 'key_buffer_size';
+-----------------+---------+
| Variable_name | Value |
+-----------------+---------+
| key_buffer_size | 8388608 |
+-----------------+---------+
innodb_buffer_pool_size,Innodb存储引擎缓存池大小(对于Innodb来说最重要的一个配置,如果所有的表用的都是Innodb,那么甚至建议将该值设置到物理内存的80%,Innodb的很多性能提升如索引都是依靠这个)
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| innodb_buffer_pool_size | 8388608 |
+-------------------------+---------+
innodb_file_per_table(innodb中,表数据存放在.ibd文件中,如果将该配置项设置为ON,那么一个表对应一个ibd文件,否则所有innodb共享表空间)

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









