







 Spark通过Stage划分实现并行计算,依据宽依赖与窄依赖进行DAG拆分。窄依赖允许在同一Stage内并行执行,而宽依赖如shuffle则需等待前一阶段完成。Spark使用回溯算法从后往前划分Stage,遇到宽依赖断开,窄依赖加入当前Stage,以优化计算效率。参考论文《ResilientDistributedDatasets:AFault-TolerantAbstractionforIn-MemoryClusterComputing》了解更多详情。
Spark通过Stage划分实现并行计算,依据宽依赖与窄依赖进行DAG拆分。窄依赖允许在同一Stage内并行执行,而宽依赖如shuffle则需等待前一阶段完成。Spark使用回溯算法从后往前划分Stage,遇到宽依赖断开,窄依赖加入当前Stage,以优化计算效率。参考论文《ResilientDistributedDatasets:AFault-TolerantAbstractionforIn-MemoryClusterComputing》了解更多详情。
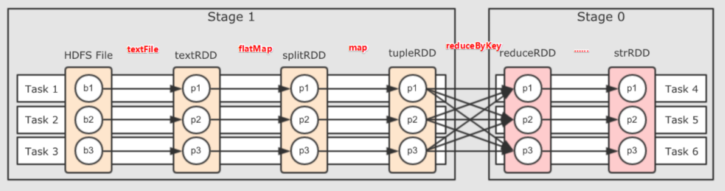
●为什么要划分Stage? --并行计算
一个复杂的业务逻辑如果有shuffle这一步,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照shuffle进行划分(也就是按照宽依赖就行划分),就可以将一个DAG划分成多个Stage/阶段,在同一个Stage中,会有多个算子操作,可以形成一个pipeline流水线,流水线内的多个平行的分区可以并行执行
●如何划分DAG的stage
首先得明白什么是宽窄依赖
请看:https://blog.youkuaiyun.com/qq_43055485/article/details/115180876
对于窄依赖,partition的转换处理在stage中完成计算,不划分(将窄依赖尽量放在在同一个stage中,可以实现流水线计算)
对于宽依赖,由于有shuffle的存在,只能在父RDD处理完成后,才能开始接下来的计算,也就是说需要要划分stage(出现宽依赖即拆分)
●总结
Spark会根据shuffle/宽依赖使用回溯算法来对DAG进行Stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的stage/阶段中
具体的划分算法请参见AMP实验室发表的论文
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》

















 9132
9132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









