




 博客参考特定地址,介绍了SQL中使用IN和EXISTS的执行结果,并阐述二者区别及应用场景。当子查询结果集记录少、主查询表大且有索引时用IN;主查询记录少、子查询表大且有索引时用EXISTS,还提到二者驱动顺序不同及IN不对NULL处理。
博客参考特定地址,介绍了SQL中使用IN和EXISTS的执行结果,并阐述二者区别及应用场景。当子查询结果集记录少、主查询表大且有索引时用IN;主查询记录少、子查询表大且有索引时用EXISTS,还提到二者驱动顺序不同及IN不对NULL处理。
参考地址:https://blog.youkuaiyun.com/Maxiao1204/article/details/120467106
sql如下;
第一条sql
SELECT
count(*)
FROM
hlms_toc_role tr
WHERE
tr.disabled = 0
AND tenant_id =540 and id in (
SELECT
ur.role_id
FROM
hlms_toc_user_role ur
WHERE
ur.tenant_id = 540 and ur.user_id =114202926759936 )
AND tr.role_code = 'administrator';
第二条sql
SELECT
count(*)
FROM
hlms_toc_role tr
WHERE
tr.disabled = 0
AND tenant_id =540 and EXISTS (
SELECT
ur.role_id
FROM
hlms_toc_user_role ur
WHERE
ur.tenant_id = 540 and ur.user_id =114202926759936 )
AND tr.role_code = 'administrator' ;
第三条 和第一条结果一致
SELECT
count(*)
FROM
hlms_toc_role tr
WHERE
tr.disabled = 0
AND tr.tenant_id =540 and EXISTS (
SELECT
ur.role_id
FROM
hlms_toc_user_role ur
WHERE
ur.tenant_id = 540 and ur.user_id =114202926759936 and tr.id=ur.role_id)
AND tr.role_code = 'administrator' ;
执行结果如下
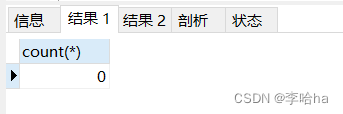
使用 in执行的结果
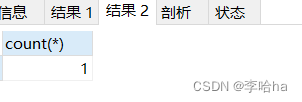
使用exists执行结果
区别及应用场景
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









