







作者 | gongyouliu
编辑 | gongyouliu
我们在上一篇文章中介绍了规则策略召回算法,这类方法非常简单,只需要利用一些业务经验和基础的统计计算就可以实现了。本节我们来讲解一些基础的召回算法,这类算法要么是非常经典的方法,要么是需要利用一些机器学习知识的,相比上一章的方法要更复杂一点,不过也不难,只要懂一些基础的机器学习和数学知识就可以很好地理解算法原理。
具体来说,本章我们会讲解关联规则召回、聚类召回、朴素贝叶斯召回、协同过滤召回、矩阵分解召回等5类召回算法。我们会讲清楚具体的算法原理及工程实现的核心思想,读者可以结合自己公司的业务情况思考一下这些算法怎么用到具体的业务中。
8.1 关联规则召回算法
关联规则是数据挖掘中最出名的方法之一,相信大家都听过啤酒与尿布的故事(不知道的读者可以百度搜索了解一下),下面我们给出关联规则的定义。
假设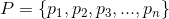 是所有物品的集合(对于家乐福超市来说,就是所有的商品集合)。关联规则一般表示为 的形式,其中是的子集,并且
是所有物品的集合(对于家乐福超市来说,就是所有的商品集合)。关联规则一般表示为 的形式,其中是的子集,并且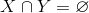 。关联规则表示如果在用户的购物篮(用户一次购买的物品的集合称为一个购物篮,通常用户购买的物品会放到一个篮子里,所以叫做购物篮)中,那么用户有很大概率同时购买了 。
。关联规则表示如果在用户的购物篮(用户一次购买的物品的集合称为一个购物篮,通常用户购买的物品会放到一个篮子里,所以叫做购物篮)中,那么用户有很大概率同时购买了 。
通过定义关联规则的度量指标,一些常用的关联规则算法(如Apriori)能够自动地发现所有关联规则。关联规则的度量指标主要有支持度(support)和置信度(confidence)两个,支持度是指所有的购物篮中包含的购物篮的比例(即同时出现在一次交易中的概率),而置信度是指包含的购物篮中同时也包含的比例(即在给定的情况下,出现的条件概率)。它们的计算公式如下:
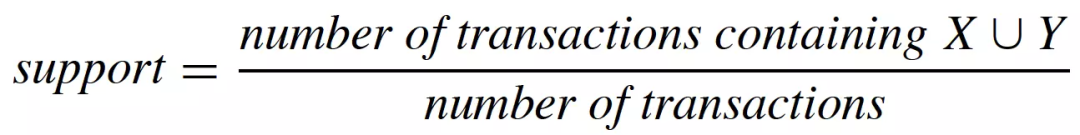
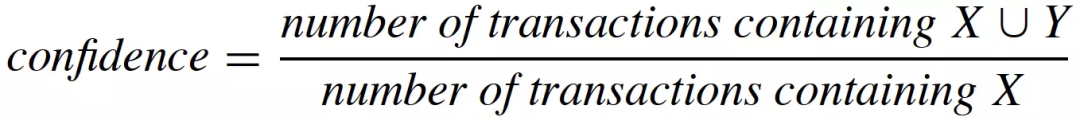
支持度越大,包含的交易样本越多,说明关联规则有更多的样本来支撑,“证据”更加充分。置信度越大,我们更有把握从包含的交易中推断出该交易也包含。关联规则挖掘中,我们需要挖掘出支持度和置信度大于某个阈值的关联规则,这样的关联规则才更可信,更有说服力,泛化能力也更强。
有了关联规则的定义,下面我们来讲解怎么将关联规则用于召回。对于推荐系统来说,一个购物篮即是用户操作过的所有物品的集合。关联规则表示的意思是:如果用户操作过中的所有物品,那么用户很可能喜欢中的物品。有了这些说明,那么利用关联规则为用户生成召回的算法流程如下(假设所有操作过的物品集合为):
挖掘出所有满足一定支持度和置信度(支持度和置信度大于某个常数)的关联规则;
从1中所有的关联规则中筛选出所有满足的关联规则;
为用户生成召回候选集,具体计算如下:
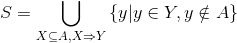
即将所有满足2的关联规则中的合并,并剔除掉用户已经操作过的物品,这些物品就是待召回给用户的。对于3中的候选推荐集,可以按照该物品所在关联规则的置信度的大小降序排列,对于多个关联规则生成同样的候选推荐物品的,可以用置信度最大的那个关联规则的置信度。除了可以采用置信度外,也可以用支持度和置信度的乘积作为排序依据。对于4中排序好的物品,可以取topN作为召回给用户的结果。
基于关联规则的召回算法思路非常简单朴素,算法也易于实现,Spark Mllib中有关联规则的两种分布式实现FP-Growth和PrefixSpan,大家在业务中可以直接使用。根据作者曾经的使用经验,要是物品数量太多、用户行为记录巨大,那么整个计算过程会非常慢,所以关联规则一般适合用户数和物品数不是特别大的场景。
8.2 聚类召回算法
机器学习中的聚类算法种类非常多,大家用得最多的还是k-means聚类,本节我们也只采用k-means聚类来说明怎么召回,在讲解之前我们简单介绍一下k-means聚类的算法原理,具体步骤如下:
k-means算法的步骤:
input:N个样本点,每个样本点是一个n维向量,每一维代表一个特征。最大迭代次数M。
(1)从N个样本点中随机选择k个点作为中心点,尽量保证这k个距离相对远一点
(2)针对每个非中心点,计算他们离k个中心点的距离(欧氏距离)并将该点归类到距离最近的中心点
(3)针对每个中心点,基于归类到该中心点的所有点,计算它们新的中心(可以用各个点的坐标轴的平均值来估计),进而获得k个新的中心点
(4)重复上述步骤(2)、(3),直到迭代次数达到M或者前后两次中心点变化不大(可以计算前后两次中心点变化的平均绝对误差,比如绝对误差小于某个很小的阈值就认为变化不大)
从上面的算法原理我们可以看到,k-means是一个迭代算法,原理非常简单,可操作性也很强,scikit-learn和Spark中都有k-means算法的实现,大家可以直接调用。
讲完了k-means聚类的算法原理,我们就可以基于用户或物品进行k-means召回了,这两类召回分别用在个性化召回和物品关联物品召回中,下面我们来分别说明这两种情况怎么用k-means进行召回。
8.2.1 基于用户聚类的召回
如果我们将所有用户聚类了,就可以将该用户所在类别的其他用户操作过的物品(但是该用户没有操作行为)作为该用户的召回。具体计算公式如下,其中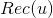 是给用户u的召回,是用户所在的聚类,
是给用户u的召回,是用户所在的聚类,![]() 、分别是用户、的操作历史集合。
、分别是用户、的操作历史集合。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9314
9314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











