







动机
当一个算法在训练集表现优秀,但在测试集表现不佳时,我们需要考虑如何改良算法。方法包括:
- 修改拟合函数的最高阶数
- 增加或者减少特征数
- 修改regularization参数λ
- 增加样本数,扩大数据集
该从何处下手?乱试是不行的,我们可以按照以下步骤来评估各种方法的效能。
在评估之前,我们先将数据集划分为{训练集,交叉验证集,测试集}三个子集,这三个子集可以分别占总集的60%,20%,20%,我们用训练集来训练模型,用交叉验证集来挑选模型参数,用测试集来测试模型的泛化能力。
挑选拟合函数
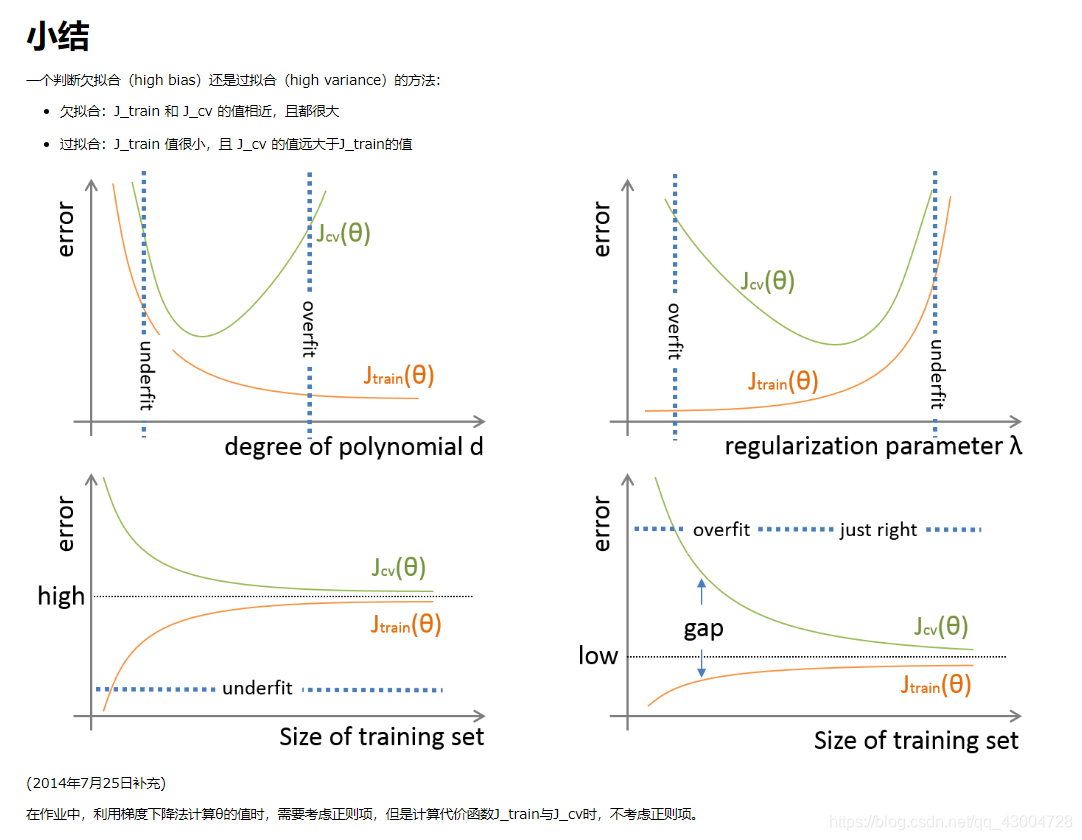
拟合函数的阶数太小的时候,拟合函数表现能力弱,太大时,表现能力加强。因此,拟合函数的阶数:
-
过小时,容易发生欠拟合
-
过大时,容易发生过拟合
对于神经网络,增加hidden layer相当于增加拟合函数的阶。增加hidden layer、多项式组合等,都是增加feature的个数的方法。
正则化参数
正则化参数用于限制学习得到的参数,使参数不会太大,以此来防止过拟合。 -
过小时,限制有限,容易发生过拟合
-
过大时,限制过度,容易发生欠拟合
数据集合大小
给定一个数据集合,如果我们学到一个欠拟合模型,那么: -
数据集很小时,训练集的误差代价比较小,但是交叉验证集的误差代价会很大
-
数据集很大时,训练集和交叉验证集的代价都会很大
反之,如果我们学到一个过拟合模型,那么: -
数据集很小时,训练集的误差代价比较小,但是交叉验证集的误差代价会很大(同上),二者之间存在较大的的gap
-
数据集很大时,模型的泛化能力变强,不再容易出现过拟合现象,训练集和交叉验证集的误差代价都会降下来

















 1849
1849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









