







 博客主要介绍了HashMap数据结构的定义和工作原理。正常存储先计算key的hash值,若未发生hash碰撞则为数组结构,实际会出现链表结构。采用双重判断机制,若key的hash值重复,会比较链上键值对的key的equals值,相同则覆盖。还提及后续学习方向。
博客主要介绍了HashMap数据结构的定义和工作原理。正常存储先计算key的hash值,若未发生hash碰撞则为数组结构,实际会出现链表结构。采用双重判断机制,若key的hash值重复,会比较链上键值对的key的equals值,相同则覆盖。还提及后续学习方向。
首先是关于HashMap数据结构的定义:
1--HashMap采用了数组和链表的数据结构,它存储的内容是键值对(key-value)映射
其次是关于HashMap的工作原理解读:
2--存储步骤:
2.1--是按照put(key,value)首先是对key进行hash算法计算
存储位置,如果当前位置为空,直接存储数据
2.2--如果计算key的hash值是相同,那么就是以链表的方式链接在后面
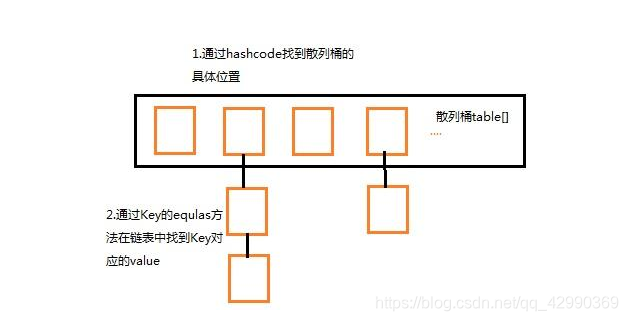
存储继续解析:
正常情况下会先进行key的hash计算,如果始终没有出现hash碰撞,那么就是只出现数组结构,但是又不现实,map存储不可能出现每一个数据的hash值不出现重复的,这就会出现链表结构,也就是说,HashMap实际上是数组以及链表结构
上面的图 横向就是数组结构模式,角标为1的数组,纵向延伸,出现这个情况是采用了双重判断机制
首先是计算key的hash值,如果出现重复,那么就会计算当前角标下所有链上的键值对,将其对key的equals的比较,如果不相同,存储,如果出现key的equals相同值,那么就是将其原来的旧键值对进行覆盖
// key值重写equals方法
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
再继续往下深入学习,感觉有点知识欠缺了,比如,存储时,链表出现空间饱和怎么处理, 又或者关于如果对其空间进行调整,对于hashmap自身影响有哪些,如何解决,都是以后学习的方向,此时,暂不做哔哔。。。

















 2686
2686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









