






哈喽,宝子们!距离上次发文,三月已过。
今天第一篇,先谈谈“JavaScript性能优化”。
这不是一篇“改个for循环更快”的小技巧合集,而是一份能在真实项目里复用的性能工程方法论与可运行示例。我们从“如何量化问题”“如何定位瓶颈”“如何设计优化顺序”“如何把优化变成团队惯性”四个层面,串起浏览器端与 Node.js 端的常见性能瓶颈与最佳实践。
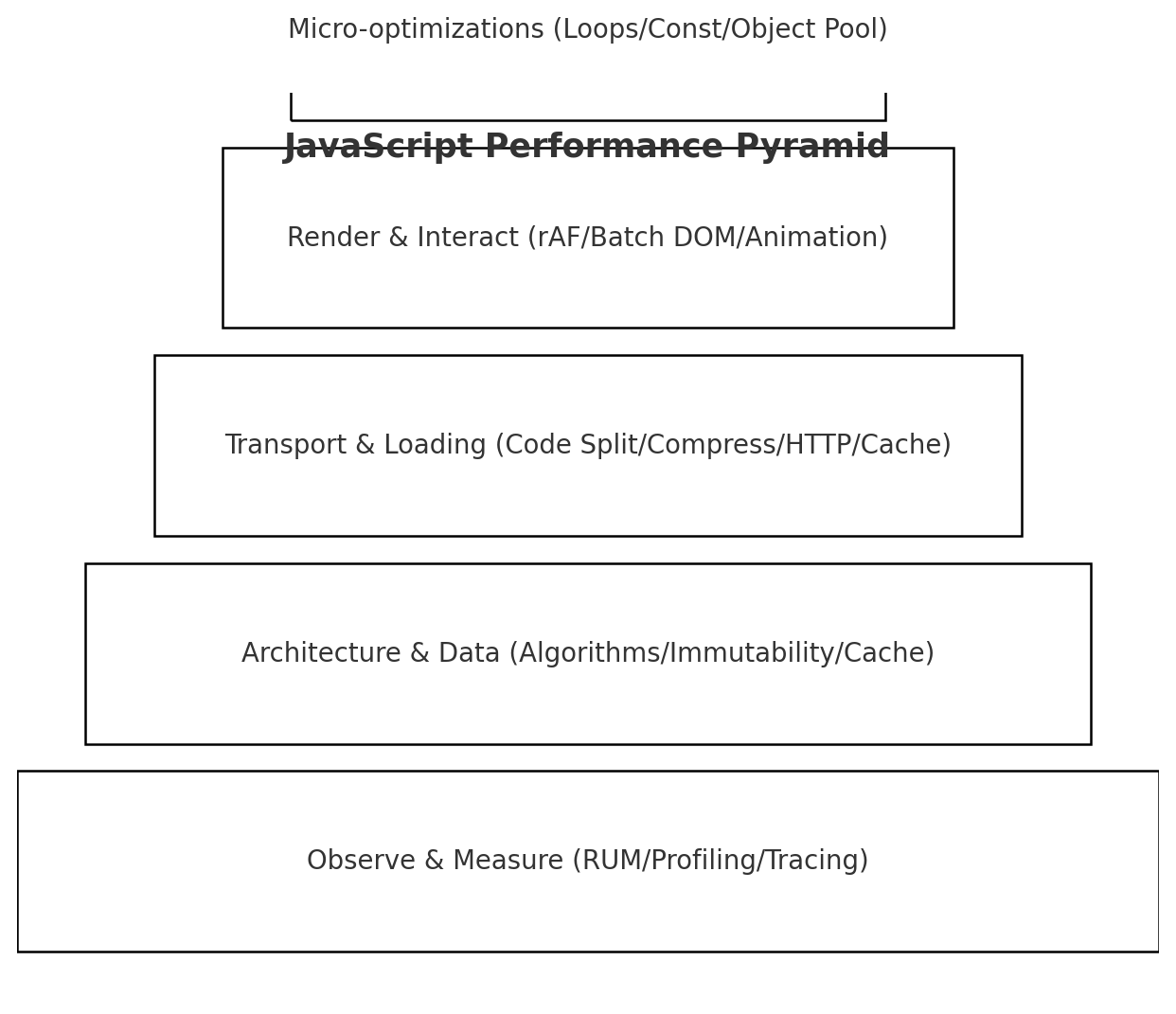 图1:JavaScript性能优化的分层金字塔模型
图1:JavaScript性能优化的分层金字塔模型
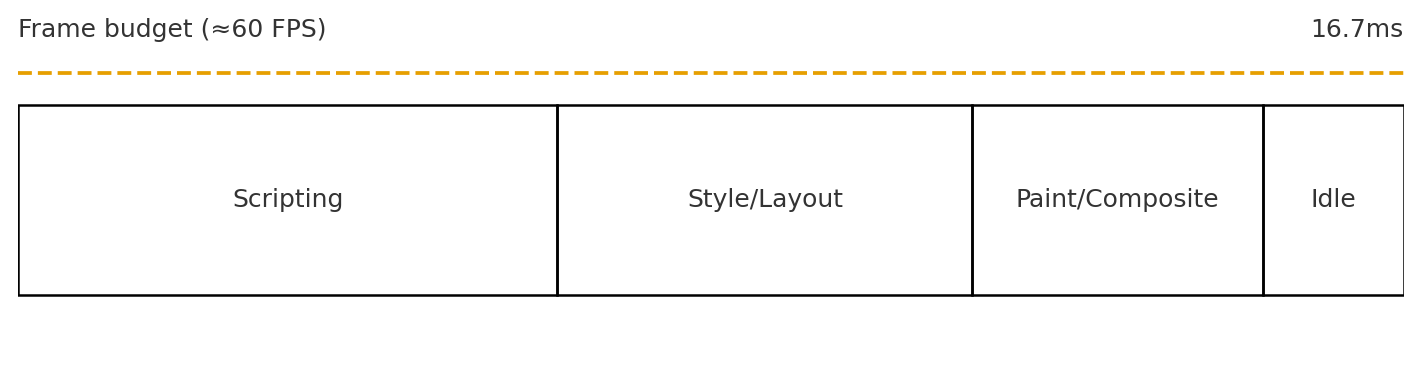
图2:帧预算(Frame Budget)
一、为何你的优化“有感觉没证据”?
性能是产品能力。当用户点击后 300ms 没有响应、滚动掉帧、输入卡顿,业务转化、留存都会被侵蚀。优化必须数据驱动,否则容易“改了很多,看不出变化”。
1)先定义指标,再谈优化
Web 侧建议以“用户感知”为核心建立指标体系:
-
加载类:TTFB、FCP、LCP(最大内容绘制)、TBT/TTI(可交互时间)、资源下载时长。
-
交互类:INP(交互到下个绘制)、点击/输入响应时延、滚动丢帧率、动画帧率(是否稳定 ≥ 60FPS)。
-
稳定性:CLS(累积布局偏移)、错误率、崩溃率。
-
内存/电量:堆占用、GC 频次、CPU 占用、发热。
Node.js 侧以吞吐与时延为主:
-
吞吐(RPS/QPS)、P95/P99 响应时间、事件循环延滞(event loop lag)、堆使用与 GC 时间、冷启动耗时等。
2)“金字塔”式优化顺序
图片里给出的“JS 性能优化金字塔”强调一个顺序:
-
观察/度量(RUM、Profiler、Tracing)
-
架构与数据结构(算法复杂度、不可变策略、缓存)
-
传输与加载(拆包、压缩、协议、缓存)
-
渲染与交互(批量 DOM、rAF、动画管线)
-
微优化(循环、常量折叠、对象池)
把最底层做扎实,顶层的“微调”才有意义。
二、定位瓶颈:用工具把时间“花在哪儿”量出来
浏览器端:
-
Performance 面板:记录一次交互或加载,查看 Main Thread 火焰图、长任务(>50ms)、Layout/Style、Paint、Composite 占比。
-
Performance Insights:更友好的瓶颈提示。
-
Memory 面板:堆快照、分配时间线,定位泄漏。
-
Web Vitals(RUM/SDK)与
PerformanceObserver:把 LCP/INP/CLS、长任务等打点到后端。
Node.js 端:
-
clinic.js/0x/—prof火焰图,定位 CPU 热点与阻塞。 -
事件循环延滞(
uv/async_hooks与外部采集)评估是否被同步计算/GC 阻塞。
可运行示例:采集长任务与 LCP/INP(浏览器)
<script>
// 1) 监控长任务(Long Tasks API)
try {
const longTaskObs = new PerformanceObserver((list) => {
for (const e of list.getEntries()) {
// e.duration > 50ms 即为长任务
console.log('[LongTask]', Math.round(e.duration), 'ms', e.name || '');
// 上报到你的日志端点
}
});
longTaskObs.observe({ entryTypes: ['longtask'] });
} catch {}
// 2) 采集 LCP
try {
let lcp;
const lcpObs = new PerformanceObserver((list) => {
const entries = list.getEntries();
lcp = entries[entries.length - 1];
});
lcpObs.observe({ type: 'largest-contentful-paint', buffered: true });
addEventListener('visibilitychange', () => {
if (document.visibilityState === 'hidden' && lcp) {
console.log('[LCP]', Math.round(lcp.renderTime || lcp.loadTime));
// 上报
}
});
} catch {}
// 3) 采集 INP(交互延迟)
try {
let maxInteraction = 0;
const inpObs = new PerformanceObserver((list) => {
for (const e of list.getEntries()) {
maxInteraction = Math.max(maxInteraction, e.duration);
}
});
inpObs.observe({ type: 'event', buffered: true, durationThreshold: 0 }); // 需要较新浏览器
window.addEventListener('beforeunload', () => {
console.log('[INP]', Math.round(maxInteraction));
// 上报
});
} catch {}
</script>
三、常见瓶颈与有效解法
(一)JavaScript 体积与阻塞
问题:bundle 过大、首屏同步执行太多、第三方脚本阻塞。 解法清单:
-
按路由/组件拆包 + 动态 import;预加载关键 chunk、预取后续 chunk。
-
打开 Tree Shaking/SideEffects,并用
babel/tsc保持module产物利于摇树。 -
仅在需要时注册第三方 SDK(懒加载),或用 Facade 降低全局可见性。
-
HTTP/2/3 连接复用、Gzip/Brotli 压缩、ETag/Cache-Control、S-MaxAge/CDN。
-
图片占大头?用 AVIF/WebP、
srcset/sizes与 占位骨架避免 CLS。
动态 import 示例 + 预取
<link rel="prefetch" href="/charts.chunk.js" as="script">
<script type="module">
document.getElementById('open-report').addEventListener('click', async () => {
const { renderChart } = await import('./charts.js'); // 按需加载
renderChart(document.querySelector('#mount'));
});
</script>
(二)主线程被占满:一帧只有 16.7ms
慢到可感知的卡顿,常见缘由:长任务、布局抖动、一次渲染做太多。
解法清单:
-
将重计算移出主线程:Web Worker/Workerize;图像处理用 OffscreenCanvas。
-
rAF 批量 DOM:读写分离(先读布局,再写样式),
DocumentFragment一次性插入。 -
节流/防抖:滚动、鼠标移动、窗口 resize。
-
CSS 优先动画:能用
transform/opacity就别改top/left/width/height。 -
避免布局抖动:不要在循环里交替
getBoundingClientRect()和写样式。
rAF 批量更新示例
const queue = [];
function batchUpdate(fn) {
queue.push(fn);
if (queue.length === 1) {
requestAnimationFrame(() => {
// 读
const rect = document.body.getBoundingClientRect();
// 写(合并)
queue.splice(0).forEach(f => f(rect));
});
}
}
// 使用
batchUpdate((rect) => {
const el = document.getElementById('box');
el.style.transform = `translateX(${rect.width / 10}px)`;
});
Worker 迁移 CPU 密集任务
// worker.js
self.onmessage = (e) => {
const arr = e.data; // 假设是 Float64Array 的 buffer
let sum = 0;
for (let i = 0; i < arr.length; i++) sum += Math.sqrt(arr[i] + i);
self.postMessage(sum);
};
// main.js
const worker = new Worker('worker.js', { type: 'module' });
const data = new Float64Array(1e6).map((_, i) => i);
worker.postMessage(data, [data.buffer]); // 转移所有权零拷贝
worker.onmessage = (e) => {
console.log('sum =', e.data);
};
(三)事件风暴:滚动/输入导致回调过载
节流与防抖(支持 rAF 与 idle)
export const debounce = (fn, wait = 150) => {
let t = 0;
return (...args) => {
clearTimeout(t);
t = setTimeout(() => fn.apply(null, args), wait);
};
};
export const throttle = (fn, wait = 100) => {
let last = 0;
let timer = null;
return (...args) => {
const now = Date.now();
if (now - last >= wait) {
last = now;
fn.apply(null, args);
} else if (!timer) {
const remaining = wait - (now - last);
timer = setTimeout(() => {
last = Date.now(); timer = null; fn.apply(null, args);
}, remaining);
}
};
};
// rAF 优先级的节流(适合滚动绘制)
export const throttleRaf = (fn) => {
let ticking = false;
return (...args) => {
if (!ticking) {
requestAnimationFrame(() => { fn(...args); ticking = false; });
ticking = true;
}
};
};
// requestIdleCallback(有 fallback)
export const idle = (fn, timeout = 300) => {
const ric = window.requestIdleCallback || ((cb) => setTimeout(() => cb({ timeRemaining: () => 0 }), timeout));
return (...args) => ric(() => fn(...args), { timeout });
};
事件委托:在滚动大列表或密集节点上,把监听挂到父容器,用 event.target 判断命中,能有效降低监听器数量与回调分发成本。
(四)DOM 与样式系统:把“读写”分开
避免布局抖动(Layout Thrashing)
多次交替的读写会强制同步布局,代价高。
// BAD:循环中交替读写
for (const el of items) {
const h = el.offsetHeight; // 读
el.style.height = h + 10 + 'px'; // 写
}
// GOOD:先读后写
const heights = items.map(el => el.offsetHeight);
items.forEach((el, i) => el.style.height = (heights[i] + 10) + 'px');
批量插入
const frag = document.createDocumentFragment();
for (let i = 0; i < 1000; i++) {
const li = document.createElement('li');
li.textContent = `Row ${i}`;
frag.appendChild(li);
}
list.appendChild(frag); // 一次性插入
动画走 GPU:使用 transform: translateZ(0) 或 will-change: transform;(谨慎使用,避免长期占用内存)。
(五)数据结构与算法:把 O(n²) 变成 O(n log n)
-
去重/查找优先用
Set/Map;链式查找避免indexOf的 O(n) 级多次遍历。 -
复杂列表过滤/排序,考虑 惰性序列/迭代器、合并多步映射减少中间数组。
-
频繁创建对象时可用对象池;热路径函数内联关键常量减少解构。
// 高频去重:Set 更快更省心
const unique = arr => [...new Set(arr)];
// 合并映射 + 过滤,避免中间数组
const result = [];
for (let i = 0; i < raw.length; i++) {
const v = raw[i] * 2;
if (v % 3 === 0) result.push(v);
}
(六)内存与 GC:泄漏与瞬时高峰
-
解绑事件、清理定时器;闭包持有 DOM/大对象要谨慎。
-
大对象使用
WeakRef/FinalizationRegistry管理缓存(仅在确有必要、理解其语义的前提下)。 -
流式处理替代一次性加载大文件:
ReadableStream/fetch流读,Node 侧stream.pipeline。 -
避免在热路径创建临时对象(如用重用型 buffer)。
四、传输与缓存:让“下载到执行”整条链都更短
静态资源策略
-
HTTP Caching:静态资源指纹化(
app.abcd123.js)+Cache-Control: max-age=31536000, immutable;HTMLno-store。 -
Service Worker:让“离线可用 + 预缓存 + SWR”成为默认。
最小可运行 SW:预缓存 + SWR
// sw.js
const CACHE = 'app-v1';
const PRECACHE = ['/', '/index.html', '/styles.css', '/app.js'];
self.addEventListener('install', (e) => {
e.waitUntil(caches.open(CACHE).then(c => c.addAll(PRECACHE)));
});
self.addEventListener('fetch', (e) => {
const req = e.request;
e.respondWith((async () => {
const cache = await caches.open(CACHE);
const cached = await cache.match(req);
const fetchPromise = fetch(req).then((res) => {
cache.put(req, res.clone());
return res;
}).catch(() => cached);
return cached || fetchPromise;
})());
});
图片与视频
-
srcset/sizes自动选择合适尺寸;明确width/height或占位骨架避免 CLS。 -
WebP/AVIF,海量缩略图场景可做 Sprite 或 HTTP/2 多路复用分发。
<img src="hero-800.avif" srcset="hero-400.avif 400w, hero-800.avif 800w, hero-1200.avif 1200w" sizes="(max-width: 600px) 400px, 800px" width="800" height="400" alt="hero">
五、UI 流畅性:稳住 60FPS 的几个硬招
帧预算示意如图所示:一帧 ≈ 16.7ms(60FPS)。 要想稳住:
-
Scripting:重计算移 Worker;热路径避免 try/catch 与多态混淆;必要时“分块执行”(小批次
setTimeout(0)/rAF切片)。 -
Style/Layout:减少重排来源(字体加载、无尺寸图片、动态内容插入)。
-
Paint/Composite:只变
transform/opacity;有规律的层合成。 -
Idle:把非关键工作通过
requestIdleCallback后移。
切片执行(大任务拆分)
function chunked(list, fn, size = 500) {
let i = 0;
function run() {
const end = Math.min(i + size, list.length);
for (; i < end; i++) fn(list[i], i);
if (i < list.length) requestAnimationFrame(run); // 或 setTimeout(run, 0)
}
run();
}
// 用法:chunked(bigArray, processItem);
六、长列表实战:从“卡得离谱”到“稳 60FPS”
场景:5 万条记录的订单列表,支持搜索、排序、勾选。 常见问题:一次性渲染全部节点、滚动事件回调密集、DOM 读写交替、图片未懒加载。 落地方案:
-
可视区域虚拟化:只渲染 viewport 附近 1~2 屏元素(缓冲区),滚动时替换内容而非新增 DOM。
-
图片懒加载:
loading="lazy"或IntersectionObserver。 -
统一事件委托 + rAF 节流:滚动与 hover 走
throttleRaf。 -
样式稳定:行高固定、单元格宽度固定或使用骨架,避免 CLS。
-
后台计算(排序/筛选)丢给 Worker,主线程只负责渲染。
极简虚拟化骨架(可运行)
<div id="list" style="position:relative; height:400px; overflow:auto; border:1px solid #ddd"></div>
<script>
(function(){
const total = 50000;
const rowH = 32;
const viewport = document.getElementById('list');
const content = document.createElement('div');
content.style.height = (total * rowH) + 'px';
viewport.appendChild(content);
const pool = []; // 复用 DOM
const buffer = 10;
function ensurePool(n) {
while (pool.length < n) {
const el = document.createElement('div');
el.style.position = 'absolute';
el.style.left = '0'; el.style.right = '0';
el.style.height = rowH + 'px';
el.style.borderBottom = '1px solid #f0f0f0';
content.appendChild(el);
pool.push(el);
}
}
const render = (() => {
let ticking = false;
return () => {
if (ticking) return;
requestAnimationFrame(() => {
const top = viewport.scrollTop;
const start = Math.max(0, Math.floor(top / rowH) - buffer);
const visible = Math.ceil(viewport.clientHeight / rowH) + 2*buffer;
ensurePool(visible);
for (let i = 0; i < visible; i++) {
const idx = start + i;
const el = pool[i];
if (idx >= total) { el.style.display = 'none'; continue; }
el.style.display = 'block';
el.style.transform = `translateY(${idx * rowH}px)`; // 只用 transform
el.textContent = `#${idx} 订单金额:${(Math.sin(idx)*1000+1000).toFixed(2)}`;
}
ticking = false;
});
ticking = true;
};
})();
viewport.addEventListener('scroll', render);
render();
})();
</script>
七、Node.js 侧的配合:SSR / API 的“慢”也会传染到前端
-
事件循环阻塞:CPU 密集或同步 I/O 放大尾延迟;迁移到 Worker Threads/子进程或 C++ 插件。
-
冷启动与包体:SSR 框架与依赖初始化是隐形成本;拆分路由、延迟加载、复用连接池。
-
Cache 与幂等:热点接口加层缓存(内存+外部),命中率 > 80% 能显著降时延。
-
流式 SSR/Streaming:首字节快(TTFB ↓),首屏可更早呈现。
八、把优化变成“机制”,而不是“一次性项目”
-
性能预算(Performance Budget):为 LCP、JS 体积、关键路径资源数、INP/CLS 设置红线;CI 超线即失败。
-
RUM + 告警:真实用户数据接入 BI;P75/P95 波动触发报警与回溯快照。
-
预设模板:提交 PR 时自动生成 Bundle 分析、Lighthouse 报告 diff。
-
“性能设计评审”:新特性过评审需提供性能影响评估与降级方案。
-
灰度与回滚:每一次优化都有灰度开关与回滚预案,防止“优化成事故”。
九、Checklist(落地自查清单)
- RUM 指标齐全(LCP/INP/CLS/LongTask/错误率),能按版本与区域分层追踪
- CI 中有 Bundle 体积与依赖变化的 红线阈值
- 路由级 动态 import,关键路径 preload,后续资源 prefetch
- 图片采用 AVIF/WebP + srcset/sizes,声明尺寸或骨架
- 交互热点使用 节流/防抖/idle/rAF,滚动等场景统一 事件委托
- DOM 读写分离、rAF 批量更新、大插入走 DocumentFragment
- CPU 密集任务迁移 Web Worker / Node Worker Threads
- Service Worker 具备 离线 + 预缓存 + SWR 能力
- 大列表采用 虚拟化,只渲染可见窗口
- 内存泄漏回归检查(堆快照、监听解绑、弱引用缓存)
十、与你互动:三个“实战挑战”
-
把你业务首页的 LCP 从 3.5s 拉到 2.5s:贴上你的“关键渲染路径”草图,咱们一起算账:资源体积、并发、关键 CSS、字体加载、首屏数据。
-
交互卡顿排查:给我一次 DevTools Performance 录制(含火焰图),我帮你找出 >50ms 长任务并给改造建议。
-
长列表专项:把你现有列表的 DOM 数与滚动回调贴出来,我给一版虚拟化和 Worker 分工方案。
结语
“性能优化”不是玄学,也不是偶发灵感;它是一套从指标到设计、从代码到流程的工程化能力。当你用可观测性串起链路,用架构与数据结构解决大头,再用网络与渲染把关键路径打通,最后才去做微优化,你会发现:用户更快、团队更稳、版本更敢发。(嗯……代码测试过,但难免遗漏或者错误,敬请指正、欢迎交流。谢谢宝子们!!!)

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









