






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档

问题
有时候我们做一些需求经常会需要大量往mysql中插入数据,或者修改以往mysql中的数据。
接下来举两个例子:
1.数据库中某些字段不符合当前产品需求需要回刷以前mysql中的数据
2.通过job定期去拉es/其他表数据组装大量写入新mysql表中
一般来说一个互联网公司每次对数据库批量操作的数据量可能高达百万千万级别,那么执行效率就很重要了。
如何提高插入/修改批量数据的效率就显得尤为重要。
结论
批处理和foreach效率都很不错,可以配合多线程以及在不同机器上分段执行插入/修改提高效率
准备
本次例子中我们以插入数据库为例。
1.mysql
mysql表用于演示表比较简单
表结构
CREATE TABLE `user_info_batch` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_name` varchar(100) NOT NULL COMMENT '账户名称',
`pass_word` varchar(100) NOT NULL COMMENT '登录密码',
`nick_name` varchar(30) NOT NULL COMMENT '昵称',
`mobile` varchar(30) NOT NULL COMMENT '手机号',
`email` varchar(100) DEFAULT NULL COMMENT '邮箱地址',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=603335 DEFAULT CHARSET=utf8mb3 ROW_FORMAT=DYNAMIC COMMENT='Mybatis Batch'
2.springboot-mybatis
我提供git仓库代码欢迎大家下载:https://gitee.com/llbnk/inserts-sql.git
其中如何搭建mybatis与springboot项目我就不在赘述(相信小伙伴们比我更牛逼)。
项目结构非常简单
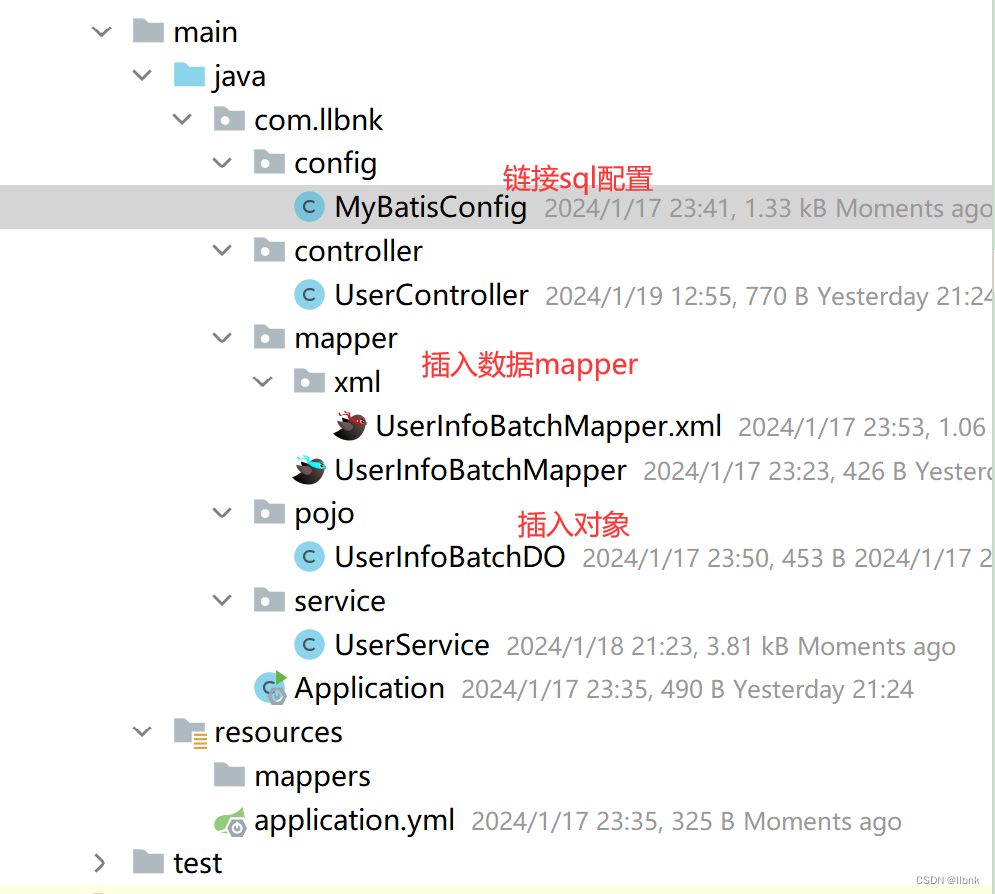
准备数据方法
准备数据
private List<UserInfoBatchDO> list = new ArrayList<>();
private List<UserInfoBatchDO> lessList = new ArrayList<>();
private List<UserInfoBatchDO> lageList = new ArrayList<>();
private List<UserInfoBatchDO> warmList = new ArrayList<>();
// 计数工具
private StopWatch sw = new StopWatch();
private List<UserInfoBatchDO> assemblyData(int count){
List<UserInfoBatchDO> list = new ArrayList<>();
UserInfoBatchDO userInfoDO;
for (int i = 0;i < count;i++){
userInfoDO = new UserInfoBatchDO()
.setUserName("llbnk")
.setNickName("llbnk")
.setMobile("139*******1")
.setPassWord("password")
;
list.add(userInfoDO);
}
return list;
}
@PostConstruct
public void assemblyData() {
list = assemblyData(200000);
lessList = assemblyData(2000);
lageList = assemblyData(1000000);
warmList = assemblyData(5);
}
一、简单插入
我们在批量插入数据的时候能想到最常见的方法就是循环一条条插入数据。
简单插入代码
public void insert() {
log.info("【程序热身】");
for (UserInfoBatchDO userInfoBatchDO : warmList) {
userInfoBatchMapper.insert(userInfoBatchDO);
}
log.info("【热身结束】");
sw.start("反复执行单条插入语句");
// 这里插入 20w 条太慢了,所以我只插入了 2000 条
for (UserInfoBatchDO userInfoBatchDO : lessList) {
userInfoBatchMapper.insert(userInfoBatchDO);
}
sw.stop();
log.info("all cost info:{}",sw.prettyPrint());
}
通过postman去调用
curl
curl --location --request GET 'localhost:8080/test/insert'
可以看到仅仅插入了2000条时间却很长。
结果

二、foreach插入
我们在进行插入数据的时候不可能仅满足2000条数据上w条在正常不过。
我们可以采用mapper的foreach插入.
这种方法需要注意
1.需要考虑分批数
2.MySQL对于单条SQL的字节大小有限制,默认为 1MB
后端代码
Userservice
public void batchInsert() {
log.info("【程序热身】");
for (UserInfoBatchDO userInfoBatchDO : warmList) {
userInfoBatchMapper.insert(userInfoBatchDO);
}
log.info("【热身结束】");
sw.start("foreach 拼接 sql");
userInfoBatchMapper.batchInsert(list);
sw.stop();
log.info("all cost info:{}",sw.prettyPrint());
}
后端代码
UserInfoBatchMapper.XML
<insert id="batchInsert">
insert into user_info_batch (user_name, pass_word, nick_name, mobile, email)
values
<foreach collection="list" item="item" separator=",">
(#{item.userName,jdbcType=VARCHAR},
#{item.passWord,jdbcType=VARCHAR},
#{item.nickName,jdbcType=VARCHAR},
#{item.mobile,jdbcType=VARCHAR},
#{item.email,jdbcType=VARCHAR})
</foreach>
</insert>
通过postman去调用
curl
curl --location --request GET 'localhost:8080/test/batch/insert'
结果
可看到foreach插入20w的数据和单条插入2k的数据效率竟然差不多

三、batch批处理
我们能看到在连接mysql的时候设置的url
jdbc:mysql://127.0.0.1:3306/insert-mysql-test?useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true
这个url携带rewriteBatchedStatements参数。
rewriteBatchedStatements参数介绍
MySql的JDBC连接的url中要加rewriteBatchedStatements参数,并保证5.1.13以上版本的驱动,才能实现高性能的批量插入。MySql JDBC驱动在默认情况下会无视executeBatch()语句,把我们期望批量执行的一组sql语句拆散,一条一条地发给MySql数据库,批量插入实际上是单条插入,直接造成较低的性能。只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL。这个选项对INSERT/UPDATE/DELETE都有效。
这种方法需要做到两点
1.需要更改后端连接数据库的参数,“rewriteBatchedStatements”: “true”
2.需要手动管理 sqlSession 的commit
后端代码
UserService
public void processInsert() {
log.info("【程序热身】");
for (UserInfoBatchDO userInfoBatchDO : warmList) {
userInfoBatchMapper.insert(userInfoBatchDO);
}
log.info("【热身结束】");
sw.start("批处理执行 插入");
// 打开批处理
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserInfoBatchMapper mapper = session.getMapper(UserInfoBatchMapper.class);
for (int i = 0,length = list.size(); i < length; i++) {
mapper.insert(list.get(i));
//每20000条提交一次防止内存溢出
if(i%20000==19999){
session.commit();
session.clearCache();
}
}
session.commit();
session.clearCache();
sw.stop();
log.info("all cost info:{}",sw.prettyPrint());
}
通过postman去调用
curl
curl --location --request GET 'localhost:8080/test/process/insert'
结果
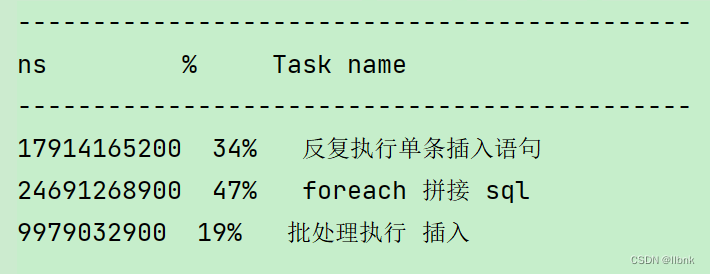
可看到批处理插入20w的数据的效率远远高于foreach更不用说单条插入了
探究批处理
为什么需要做到
1.需要更改后端连接数据库的参数,“rewriteBatchedStatements”: “true”
2.需要手动管理 sqlSession 的commit
这两点呢?
1.探究参数
我们点开commit代码
DefaultSqlSession.class
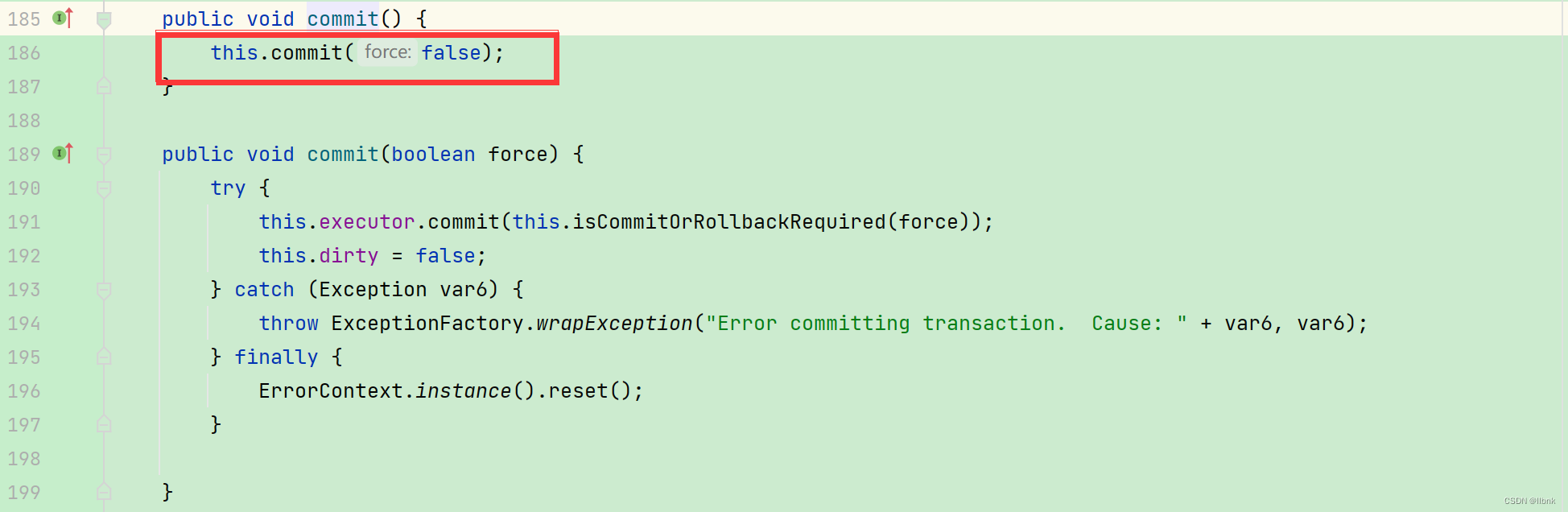
继续往下走,可以看到commit是Executor.class的接口,而实现这个接口的基类是BaseExecutor
BaseExecutor.class
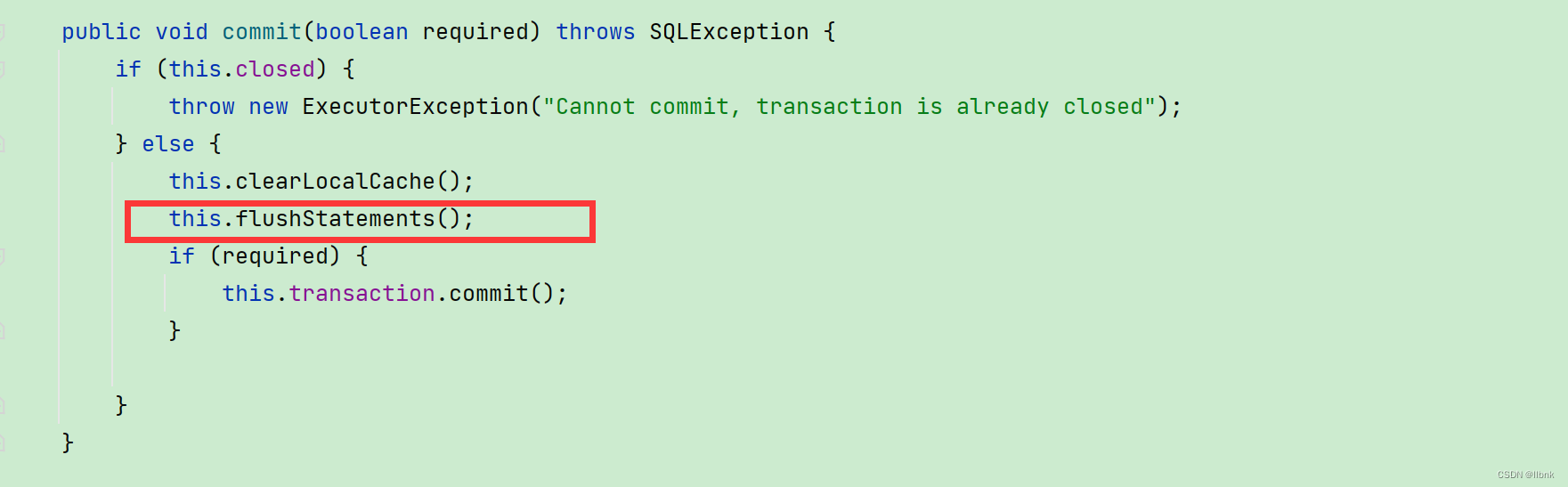
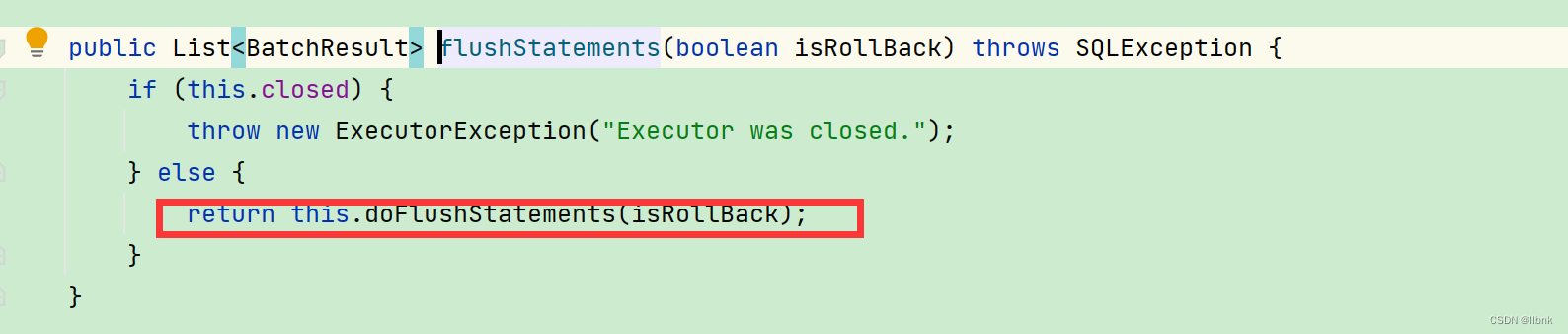
继续往下走,可以看到doFlushStatements是BaseExecutor.class的接口,而实现这个接口的基类是BatchExecutor.class
BatchExecutor.class
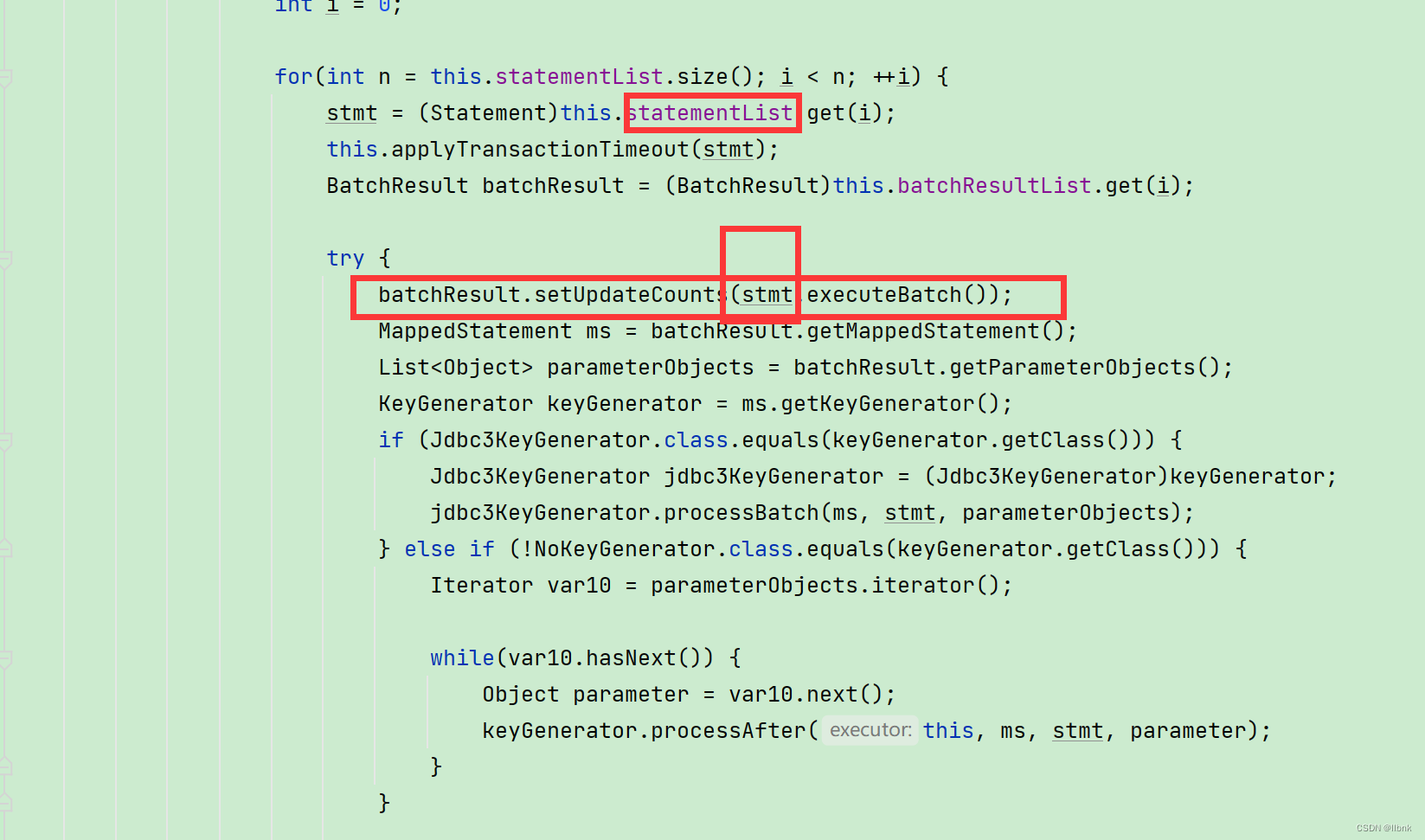
可以看到statementList去提供这个batch批处理的方法,而statementList就是一个statement的集合。现在我们看看mybtis中谁实现了statement,我们继续探究。
Statement.java
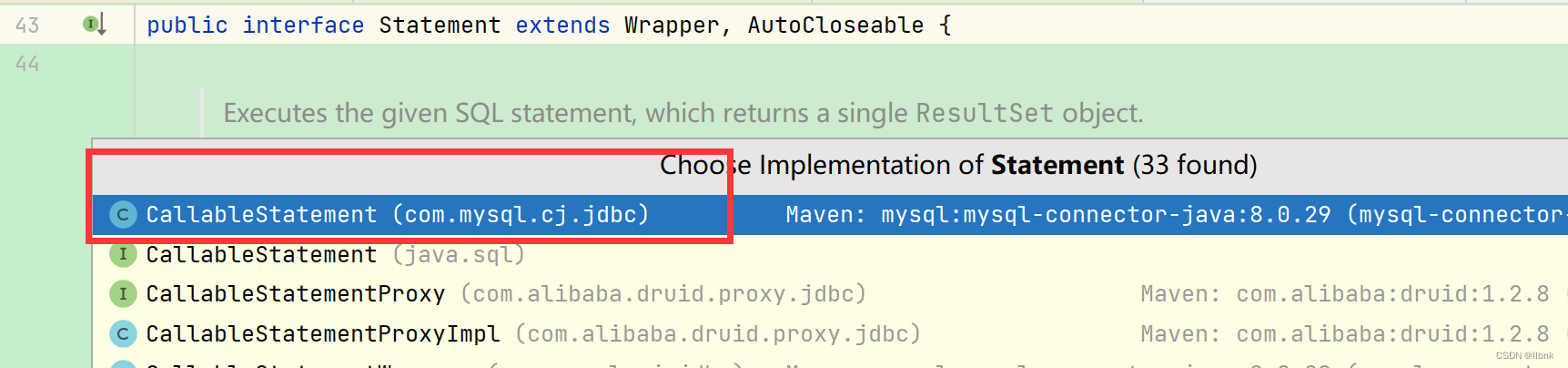
CallableStatement.class
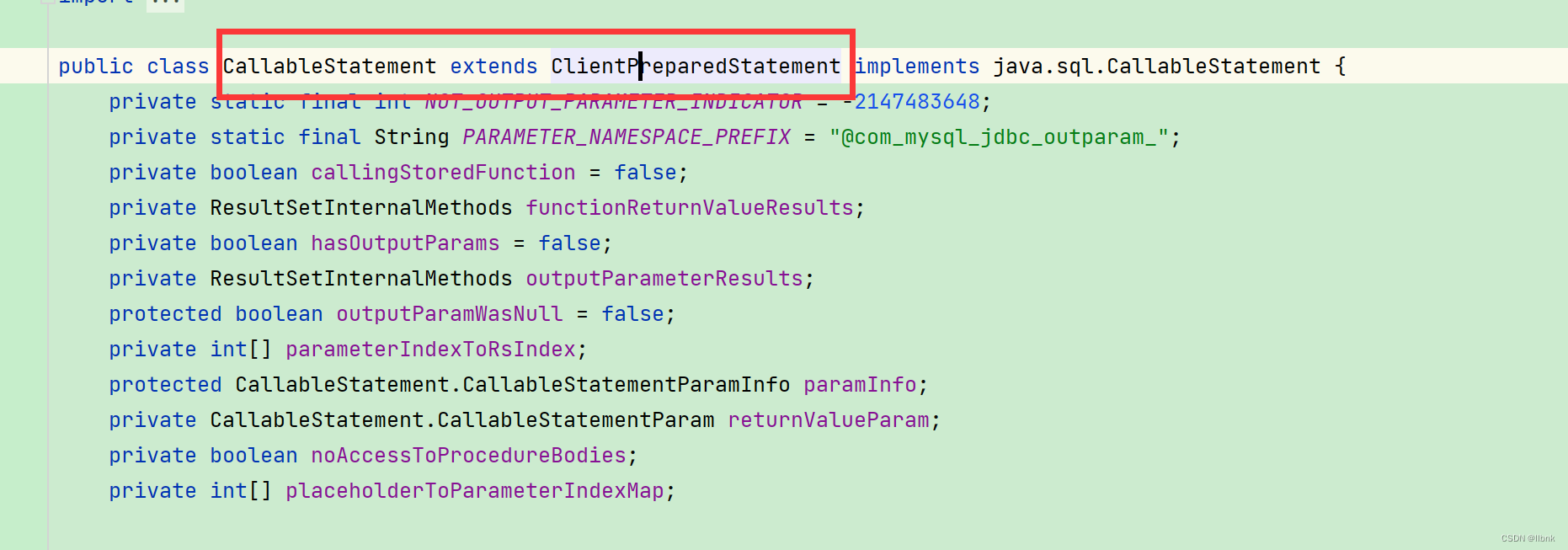
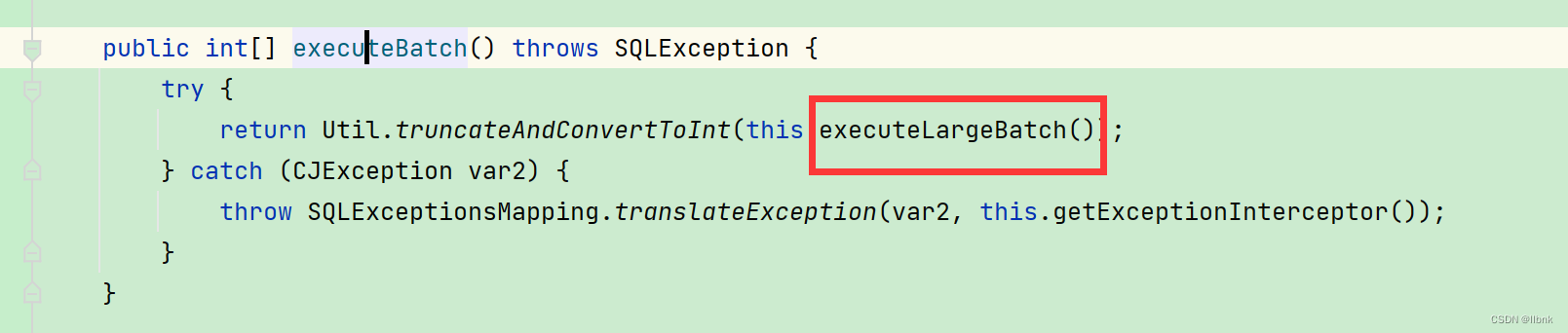
可以看到在CallableStatement.class中继承了ClientPreparedStatement。现在我们再来看executeBatch()方法。
CallableStatement.class
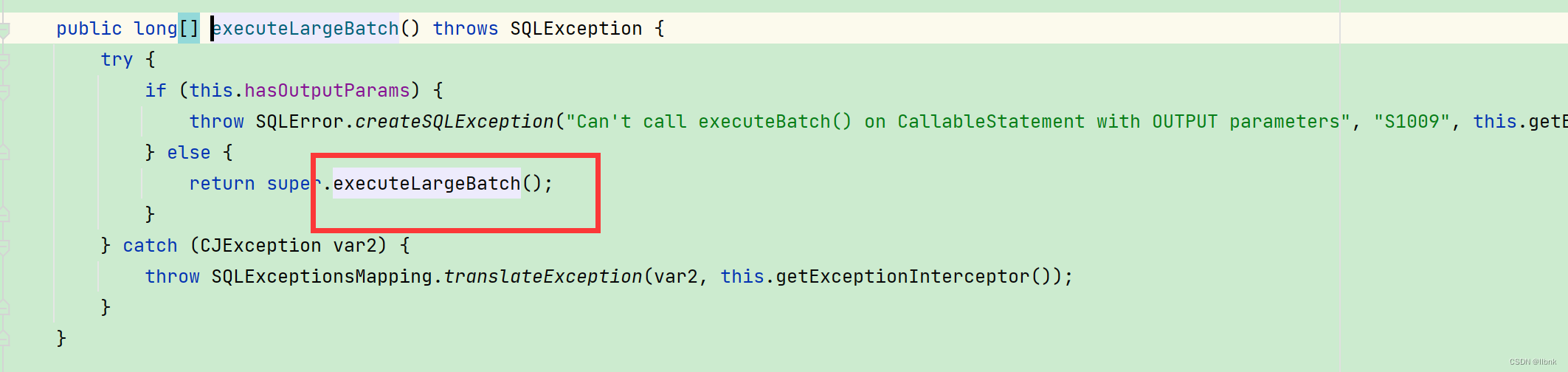
StatementImpl.class
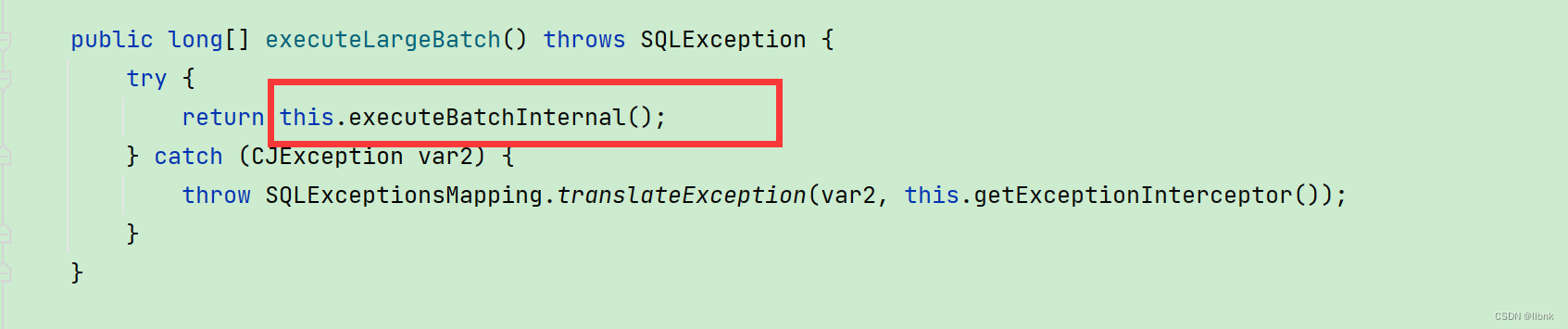


ClientPreparedStatement.class
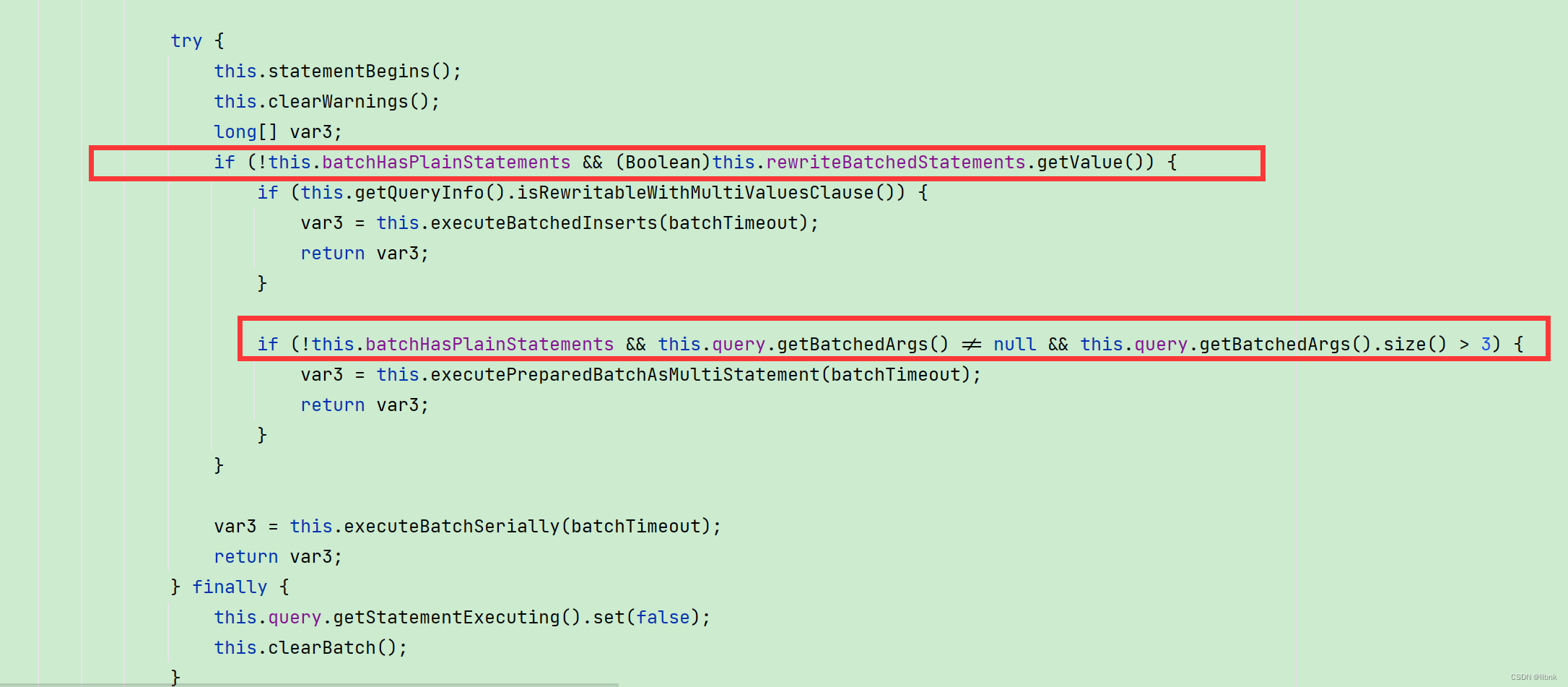
也就是说插入会走上面的方法,而修改等会走下面的方法(还需要mysql版本>=4.1.0,并且batch的数量>3)。
2.探究手动管理 commit
mybatis是非spring自己管理的事务,会强制提交单条sql语句 ,换句话来说mybatis-spring模块强制把这个commit置为true。所以需要我们手动去commit
总结(其他提效方法)
批处理效率最高其次是foreach处理,按理来说应该都用批处理,但是往往我们也会采用foreach。
虽然批处理和foreach高效但是我们还有其他方法去提高大量数据库插入的方法。
插入:
如多开几个线程去执行批量sql操作(结合线程池)
修改:
查出主键id,将批量操作按id去分段,通过不同的服务机器去调用。
参考:
[1]https://blog.youkuaiyun.com/wangwei19871103/article/details/103686121
[2]https://mp.weixin.qq.com/s/TjzXuq1M_uzpSHZgzm2u3Q
[3]https://blog.youkuaiyun.com/weixin_45143924/article/details/122397913?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-122397913-blog-103686121.235v40pc_relevant_anti_t3&spm=1001.2101.3001.4242.1&utm_relevant_index=3
[4]https://www.jb51.net/article/278324.htm


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









