







[CVPR 2022] General Facial Representation Learning in a Visual-Linguistic Manner
引言
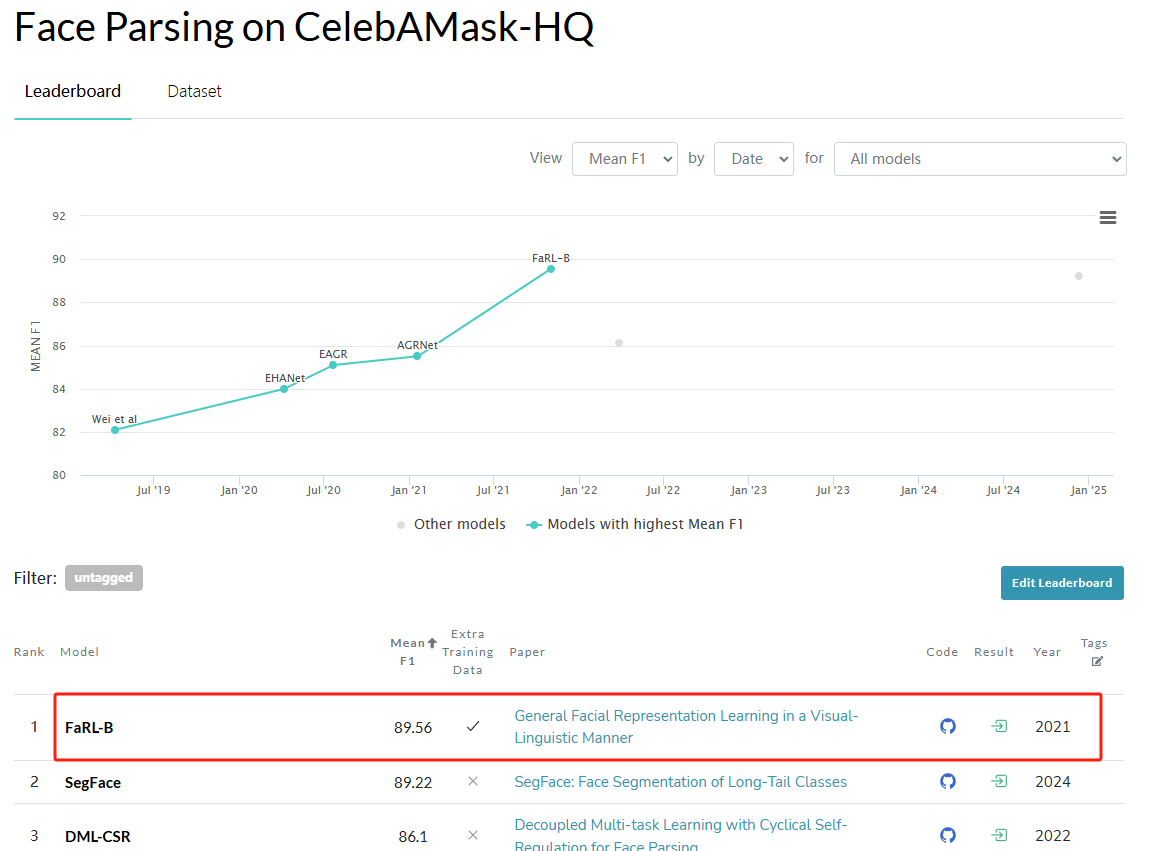
FaRL标题如上,虽然是22年的工作,但仍是CelebAMask-HQ数据集上的SOTA(如下图)。FaRL是一个类似CLIP的文本-图像匹配模型,可以理解为Face领域的CLIP。可以广泛应用于人脸图像处理的一些下游任务,例如面部解析,面部对齐,面部属性识别等。本文分享其在面部解析,也就是人脸语义分割的下游任务上的模型推理接口,有需要的同学可一键调用。
演示
原仓库(Facer)给的demo很难用,而且有各种bug(见issues),不信的同学可以去试试,踩踩坑。这里我直接用底层封装的net模型,跳过了一些无用的面部关键点识别和特征对齐以及转换的操作,实测分割精度更高,并且没有旋转和分割后的图片不完整的问题。解决了github中很多同学提到的问题。然后各个类别对应的颜色以及标签注释我放代码里面了,需要自取。
| 输入 | 输出 | 真值 |
|---|---|---|
 |  |  |
代码
pip install torch pyfacer==0.0.4
import torch
import facer
import numpy as np
from PIL import Image
def save_result(mask, output_path):
palette = np.array(
[
[0, 0, 0], # "background"
[255, 153, 51], # "neck"
[204, 0, 0], # "face"
[0, 204, 0], # "cloth"
[102, 51, 0], # "rr"
[255, 0, 0], # "lr"
[0, 255, 255], # "rb"
[255, 204, 204], # "lb"
[51, 51, 255], # "re"
[204, 0, 204], # "le"
[76, 153, 0], # "nose"
[102, 204, 0], # "imouth"
[0, 0, 153], # "llip"
[255, 255, 0], # "ulip"
[0, 0, 204], # "hair"
[204, 204, 0], # "eyeg"
[255, 51, 153], # "hat"
[0, 204, 204], # "earr"
[0, 51, 0], # "neck_l"
],
dtype=np.uint8,
)
mask = mask.squeeze(0).cpu().byte().numpy()
mask = Image.fromarray(mask, mode="P")
mask.putpalette(palette.flatten())
mask.save(output_path)
def inference(input_path, output_path):
device = "cuda" if torch.cuda.is_available() else "cpu"
image = facer.hwc2bchw(facer.read_hwc(input_path)).to(
device
) # image: 1 x 3 x h x w
model = facer.face_parser(
"farl/celebm/448",
device,
model_path="https://github.com/FacePerceiver/facer/releases/download/models-v1/face_parsing.farl.celebm.main_ema_181500_jit.pt",
)
with torch.inference_mode():
logits, _ = model.net(image / 255.0)
mask = logits.argmax(dim=1)
save_result(mask, output_path)
if __name__ == "__main__":
inference("input.jpg", "output.png")


















 1618
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











