







 本文介绍了在Ubuntu系统中,利用Python3和PaddlePaddle库,通过paddlehub模块实现中文OCR功能的详细步骤,包括安装必要的依赖库和创建一个基于gradio的接口,展示了如何运行并获取识别结果。
本文介绍了在Ubuntu系统中,利用Python3和PaddlePaddle库,通过paddlehub模块实现中文OCR功能的详细步骤,包括安装必要的依赖库和创建一个基于gradio的接口,展示了如何运行并获取识别结果。
一、前置条件
1、ubuntu系统
2、python3、pip已经安装完毕
3、paddlepaddle、paddlehub、cv2、gradio 、matplotlib 安装完毕
二、实现代码 ocr.py
import paddlehub as hub
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import gradio as gr
import cv2
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
def fn(input_img):
np_images =[cv2.imread(input_img)]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=True, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.5) # 识别中文文本置信度的阈值;
out = ""
for element in results[0]['data']:
out += element['text']
out += "\n"
return out
with gr.Blocks(title="OCR") as demo:
gr.Markdown("# OCR")
gr.Interface(fn, gr.Image(type = "filepath"), "text")
demo.launch(server_name="0.0.0.0", server_port=6789)
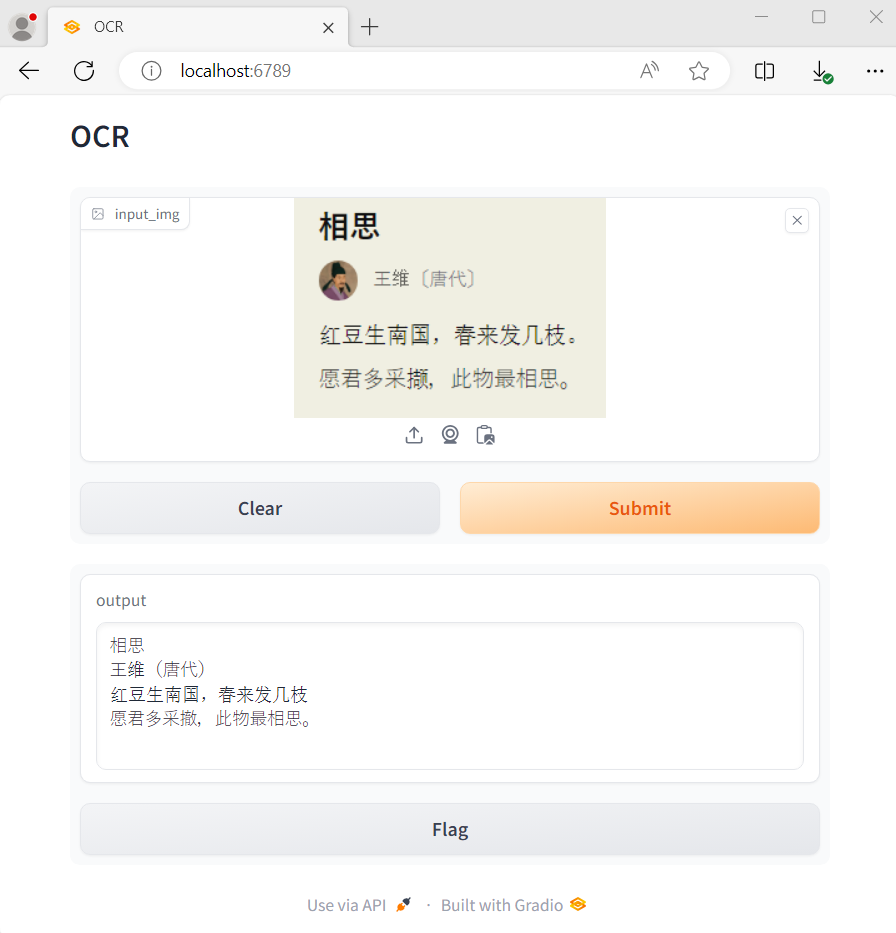
三、运行效果
python3 ocr.py


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









