




图解 Transformer
高层视角
我们首先从将模型看作一个整体的黑箱开始。在机器翻译的应用中,Transformer 接受一种语言的句子作为输入,并输出翻译后的另一种语言的句子。

展开 Transformer 后,我们可以看到它由编码器和解码器两个部分组成,并通过它们之间的连接相互通信。
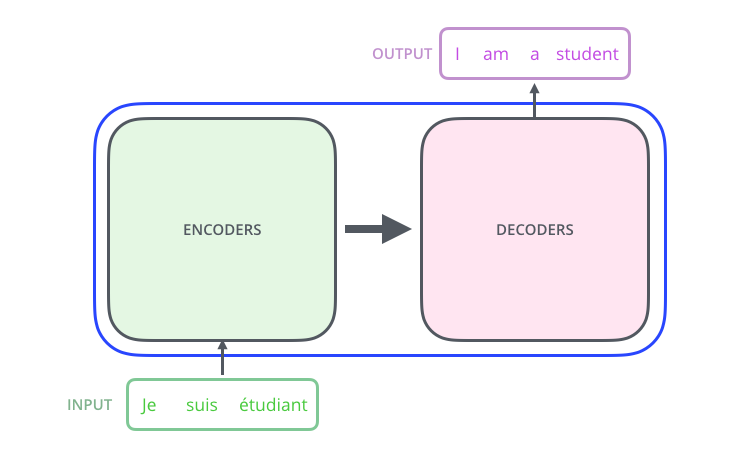
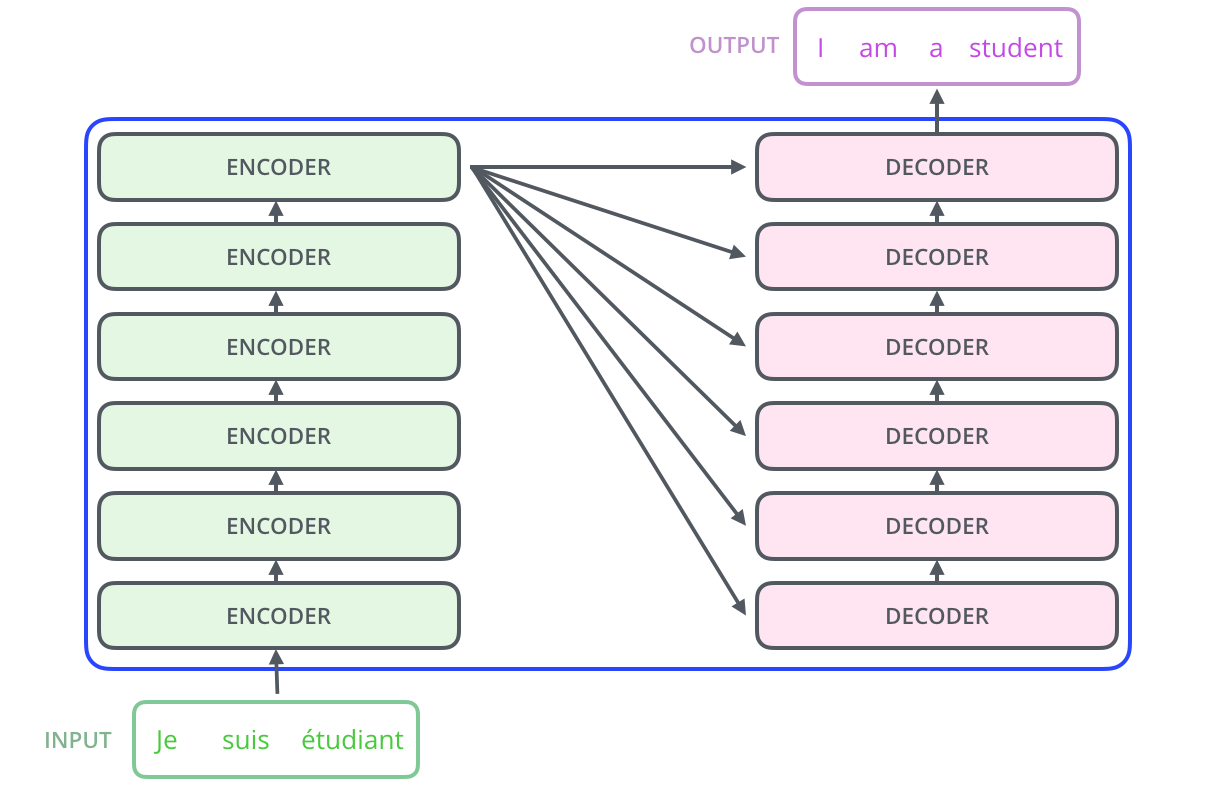
编码器部分由一系列编码器单元堆叠而成(论文中提到的版本使用了六个,但六这个数值并非特别,其他数量的堆叠也可以尝试)。解码器部分也是由相同数量的解码器单元堆叠组成。
每个编码器的结构相同(但它们并不共享权重)。每个编码器由两个子层组成:
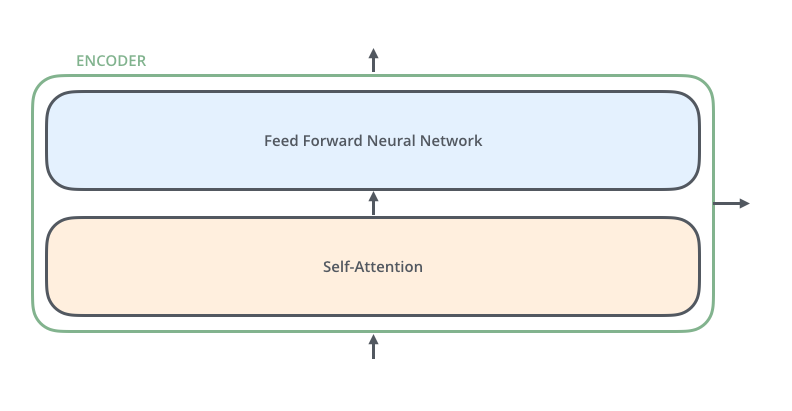
编码器的输入首先通过一个自注意力层,这个层帮助编码器在编码某个特定词时关注输入句子中的其他词。我们将在后面详细讨论自注意力机制的细节。
接着,自注意力层的输出会传递给一个前馈神经网络。同样的前馈网络独立地作用于每个位置。
解码器的结构与编码器类似,但在其中增加了一个额外的注意力层,使解码器能够聚焦于输入句子的相关部分,这类似于序列到序列模型中的注意力机制。
张量的流动过程
在了解了 Transformer 的整体结构后,我们来探索输入向量/张量是如何在各个组件之间流动的,从而将训练数据中的输入转换为输出。
与许多自然语言处理应用相似,我们首先将每个输入词转化为向量表示(通常是通过嵌入算法实现)。

嵌入操作只发生在最底层的编码器中。所有的编码器共有的抽象概念是它们接受一个向量列表,每个向量的维度为 512。在最底层的编码器中,这些向量是词嵌入,而在其他编码器中,它们是下方编码器输出的结果。向量列表的长度是一个超参数,通常与我们训练数据中最长句子的长度相等。
在对输入句子的词语进行嵌入之后,它们会依次通过编码器的各个层。
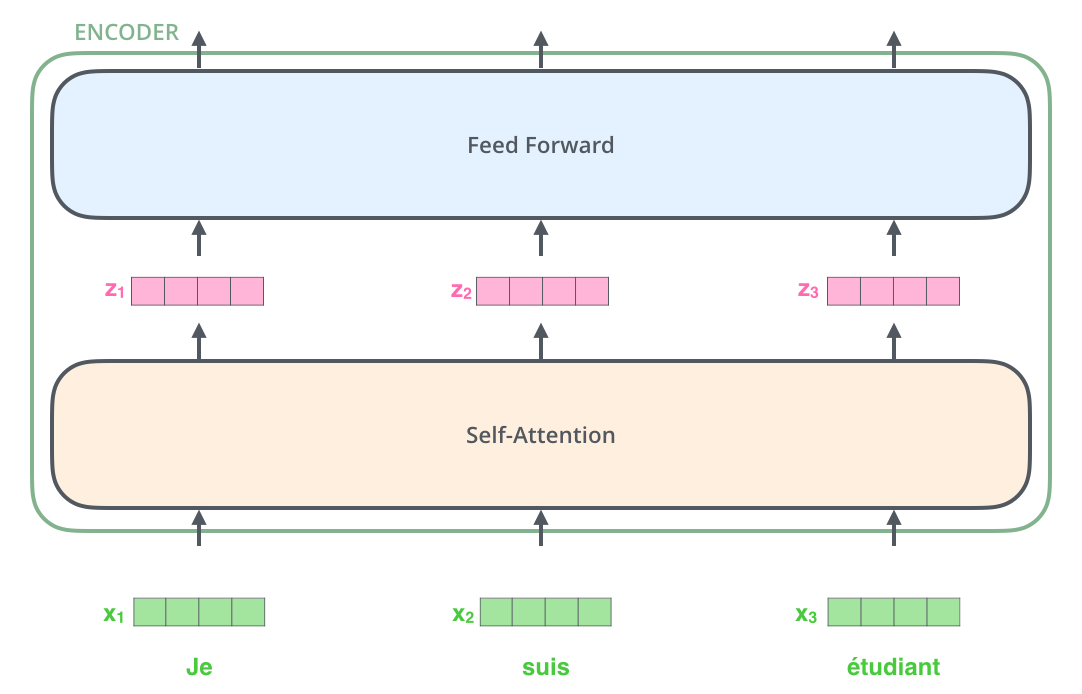
这里展示了 Transformer 的一个关键特性:每个词在编码器中的流动路径是独立的。自注意力层中,多个位置的向量之间存在依赖关系,而在前馈神经网络中则没有这种依赖,因此可以并行处理每个向量。
接下来,我们将用一个更短的句子举例,看看编码器的各个子层如何处理它。
编码过程
正如前面提到的,编码器接受一组向量作为输入。它通过将这些向量传递给自注意力层,然后传递给前馈神经网络,并将输出传递到下一个编码器,来处理这组向量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2428
2428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









