









上一章,我们部署了prometheus服务,但是点开页面发现基本都是空白的>︿<
这是因为没有添加要监控的对象是什么,我们来简单的操作一下
一. 监控prometheus本身
#我们先访问一下当前主机的http
http://192.168.1.20:9090/metrics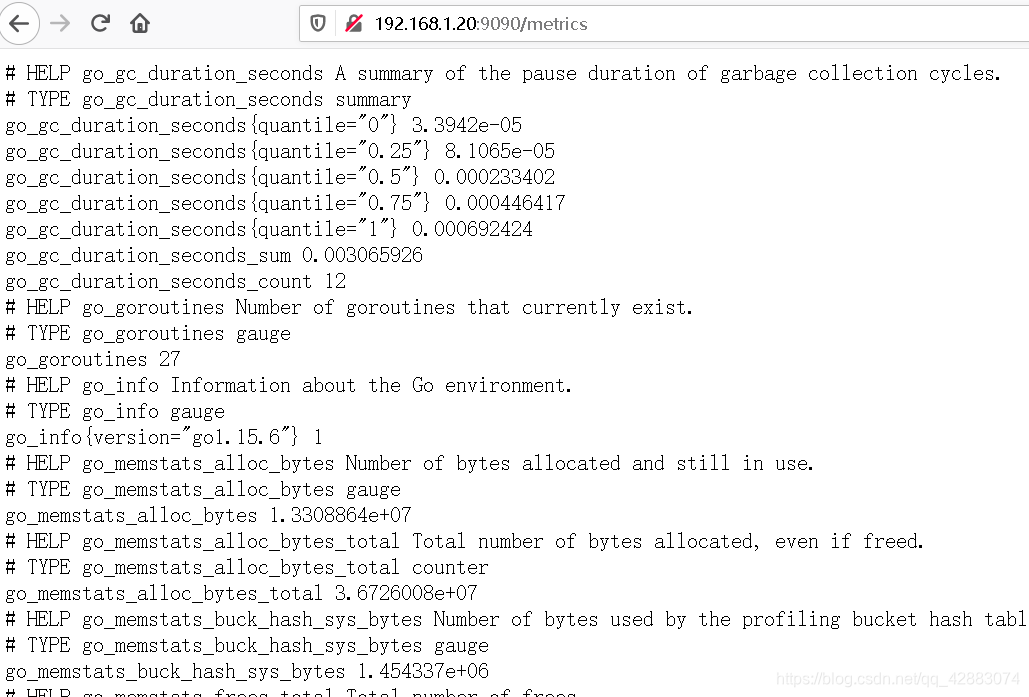
prometheus使用http请求,获取节点上的暴露的指标的同时,也会暴露自身的指标
因此我们是可以去通过prometheus去监控自身,或由其他的prometheus-server端去获取他的指标
(我们上面看到的是由客户端收集并暴露的指标,并非是已经存储在prometheus的数据)
1. 添加配置
vi /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s #全局的抓取间隔时间,优先级低于子配置中的相同配置
scrape_configs: #抓取操作
- job_name: 'prometheus'
metrics_path: /metrics #抓取对象的路径,默认/metrics 可不写
scrape_interval: 5s #抓取间隔时间,优先级比全局高
static_configs: #静态抓取目标
- targets: ['localhost:9090']
重载配置
#需要保证prometheus中有--web.enable-lifecycle
#启用远程热加载配置文件 后才可使用
curl -X POST http://192.168.1.20:9090/-/reload
3. 查看监控目标 (status-targets)
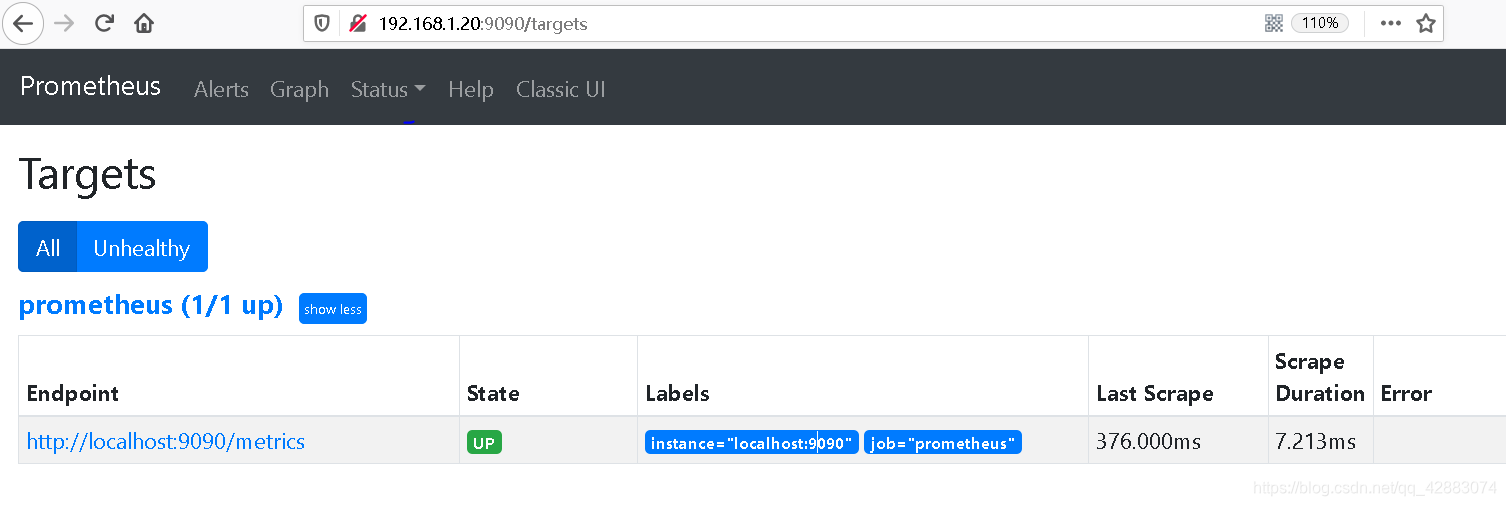
这样我们就可以收集到prometheus本身的指标数据
4. 查看指标数据
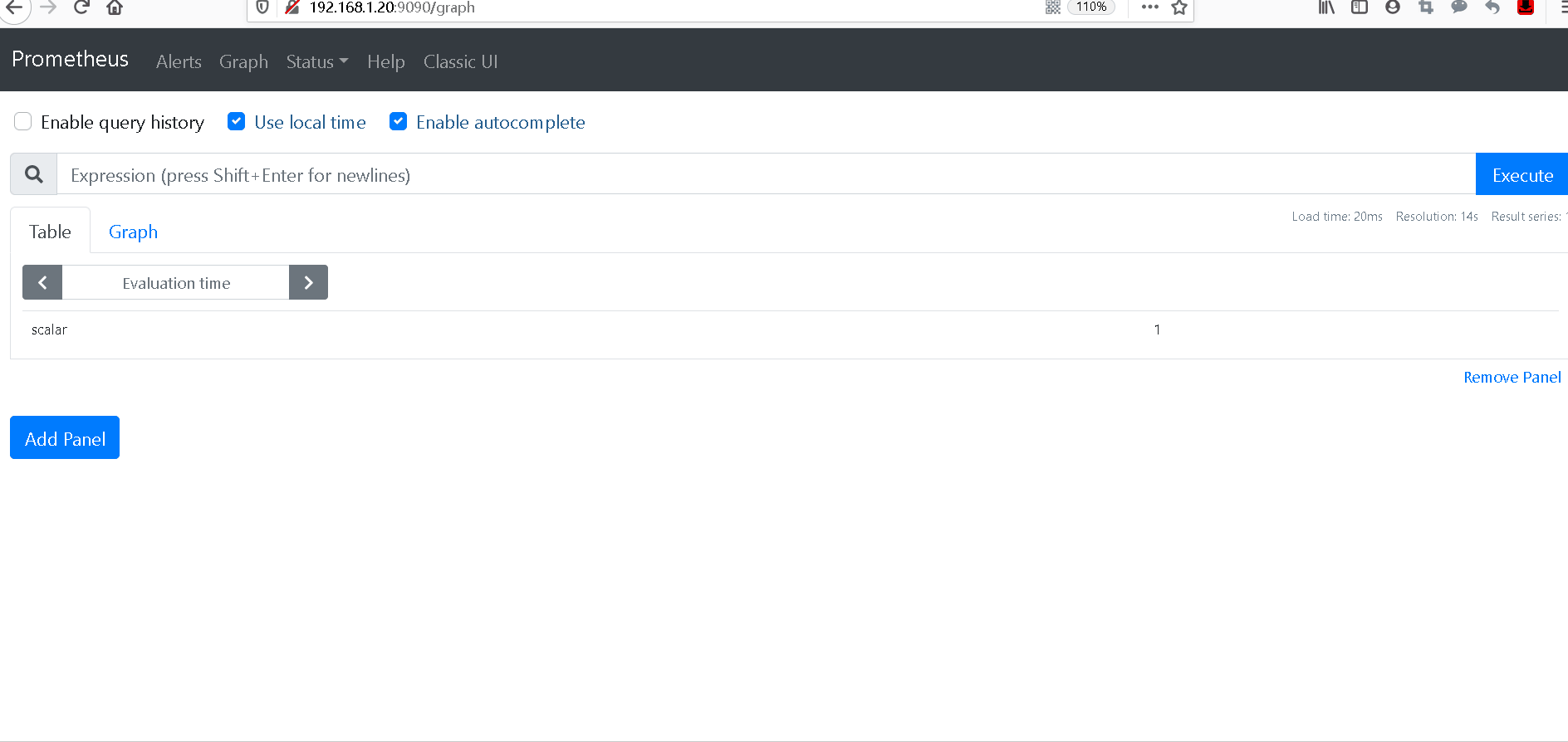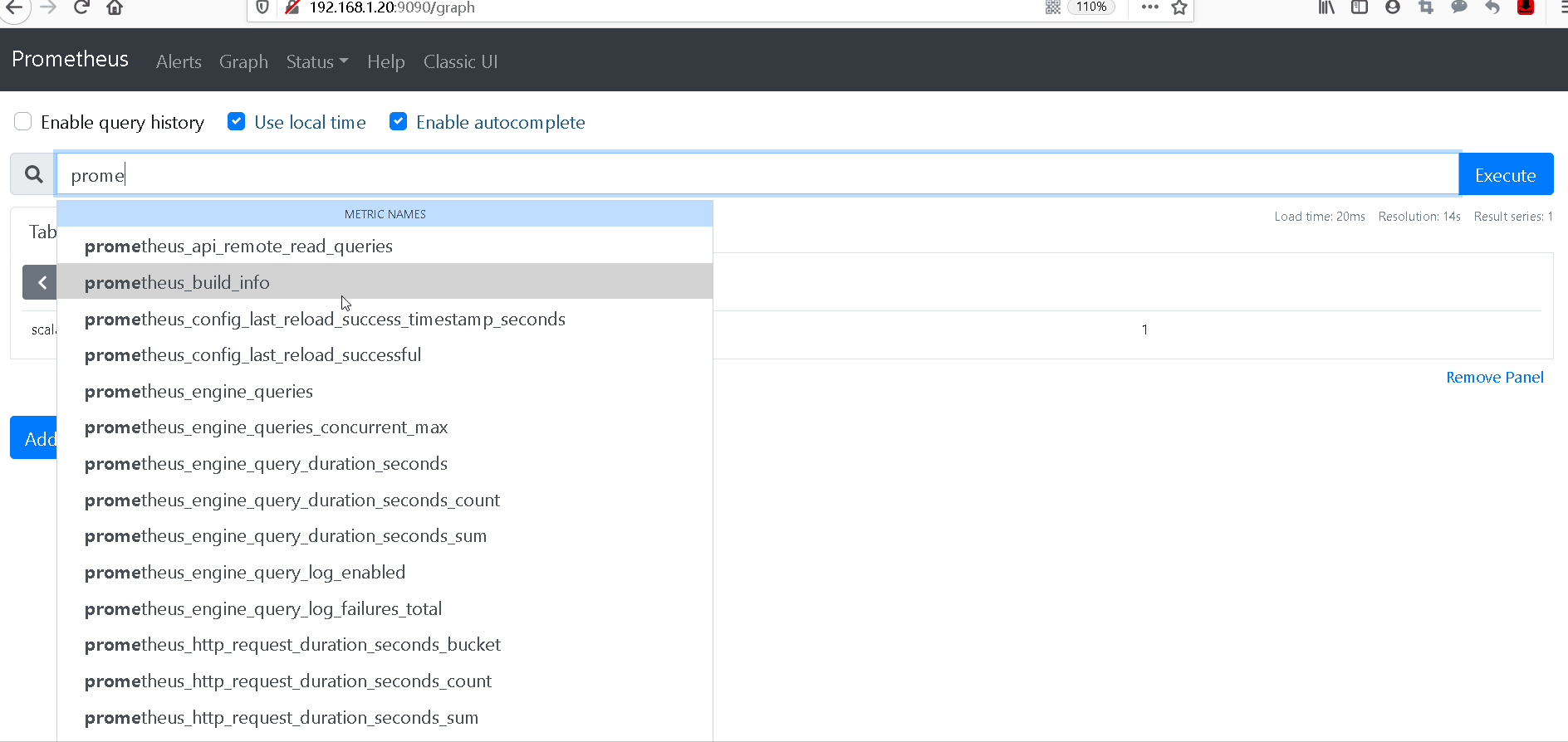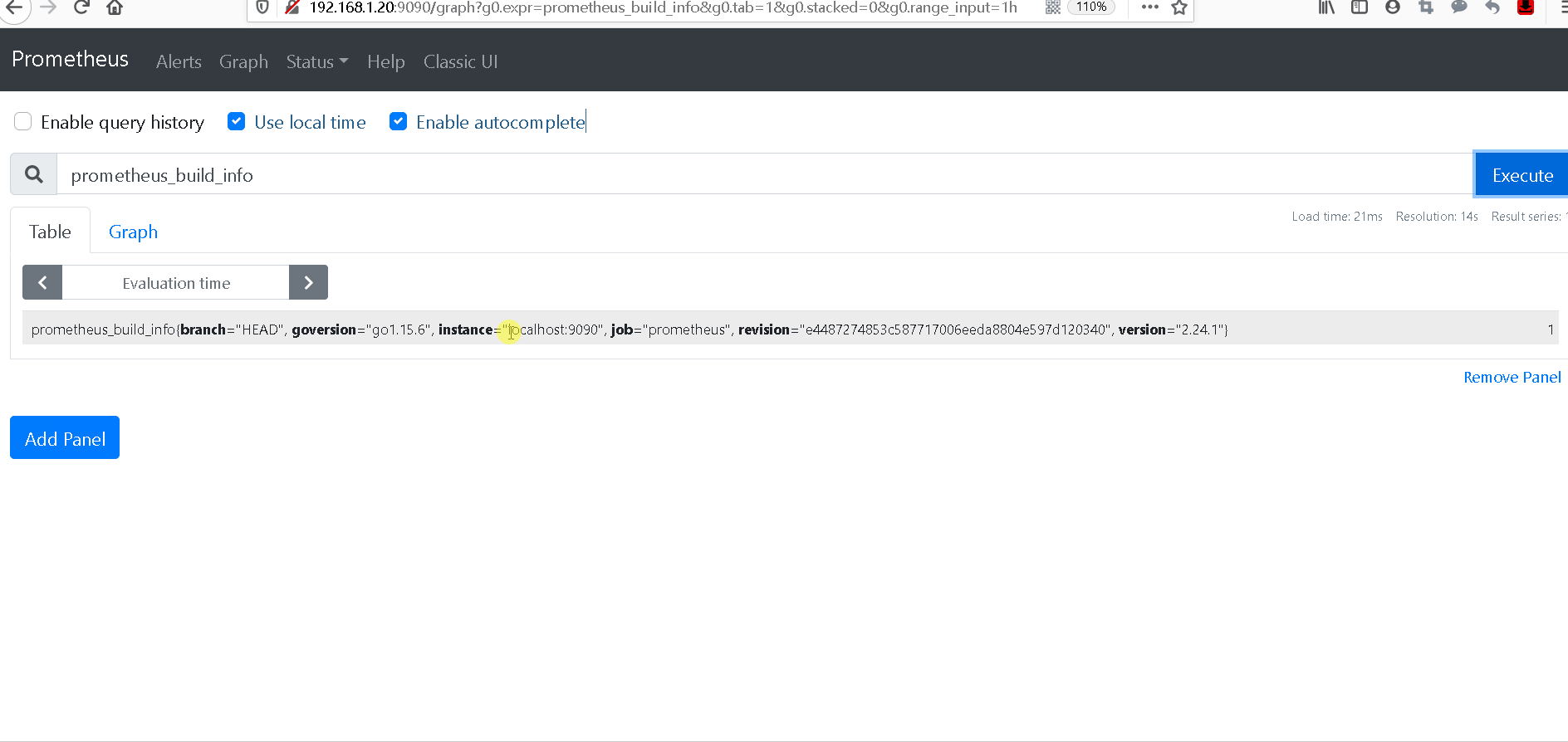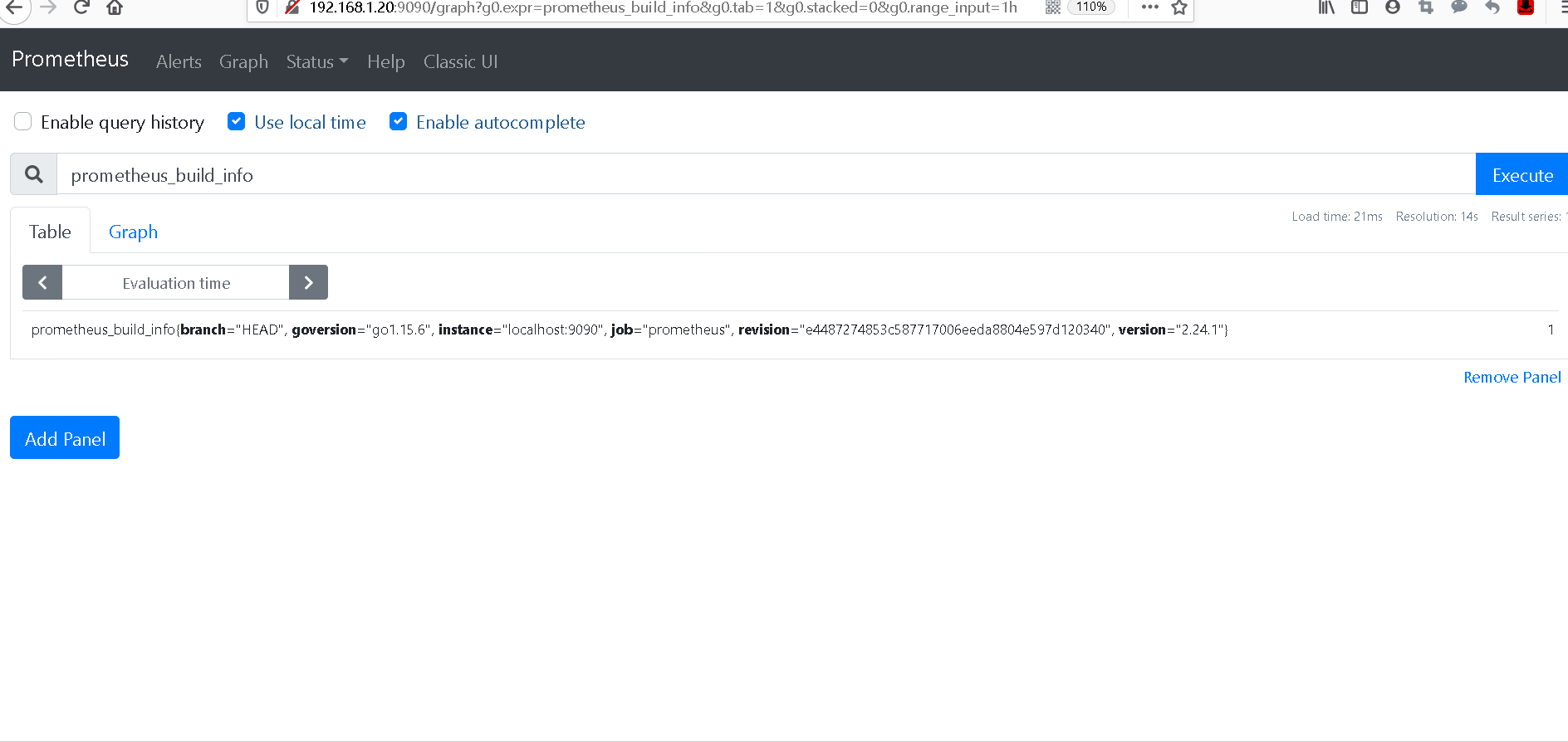
二 监控其他节点主机(node-exporter)
#换一台节点部署
#获取软件包
wget https://github.com/prometheus/node_exporter/releases/download/v1.1.0/node_exporter-1.1.0.linux-amd64.tar.gz
#这个下的很快,应该不用我的,不过还是放上来吧
#https://download.youkuaiyun.com/download/qq_42883074/15702149
#解压缩并移动文件
tar -zxvf node_exporter-1.1.0.linux-amd64.tar.gz
cp node_exporter-1.1.0.linux-amd64/node_exporter /usr/bin/1. 添加服务文件
cat > /usr/lib/systemd/system/node-exporter.service <<EOF
[Unit]
Description=Node Exporter
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
User=root
ExecStart=/usr/bin/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
#说明,如果想修改监听端口或访问路径,通过下面的参数即可
--web.listen-adress=":9100" #默认127.0.0.1 9100
--web.telemetry-path="/metrics" #默认/metrics2. 启动服务
systemctl daemon-reload
systemctl enable node-exporter
systemctl restart node-exporter
systemctl status node-exporter
3. 查看指标
http://192.168.1.21:9100/metrics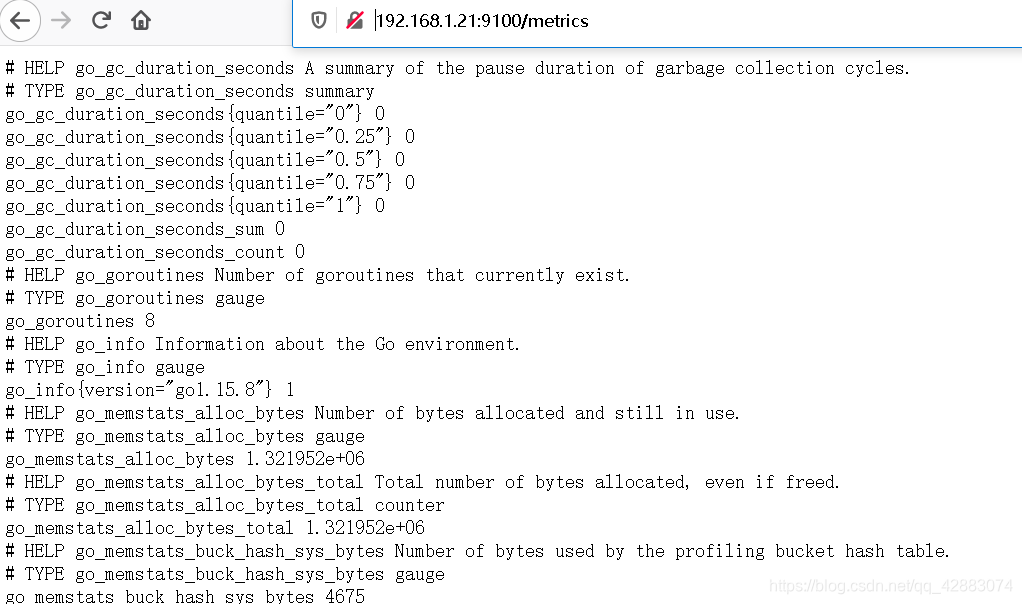
上述指标的含义
#我们随便摘一段
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
#HELP
用于解释当前指标的含义,上面案例中node_cpu的注释表示当前指标是cpu0上idle进程占用cpu的总时间
(CPU占用时间是⼀个只增不减的度量指标)
#TYPE
说明当前指标的类型
从类型中也可以看出node_cpu的数据类型是计数器(counter)
#node-exporter还可能会收集到的指标
node_boot_time #系统启动时间
node_cpu #系统CPU使⽤量
nodedisk* #磁盘IO
nodefilesystem* #⽂件系统⽤量
node_load1 #系统负载
nodememeory* #内存使⽤量
nodenetwork* #⽹络带宽
node_time #当前系统时间
go_* #node exporter中go相关指标
process_* #node exporter⾃身进程相关运⾏指标4. prometheus添加监控配置
vi /etc/prometheus/prometheus.yml
#添加
- job_name: 'node'
static_configs:
- targets: ['192.168.1.21:9100'] #主机ip + node-exporter暴露的端口
重载配置
curl -X POST http://192.168.1.20:9090/-/reload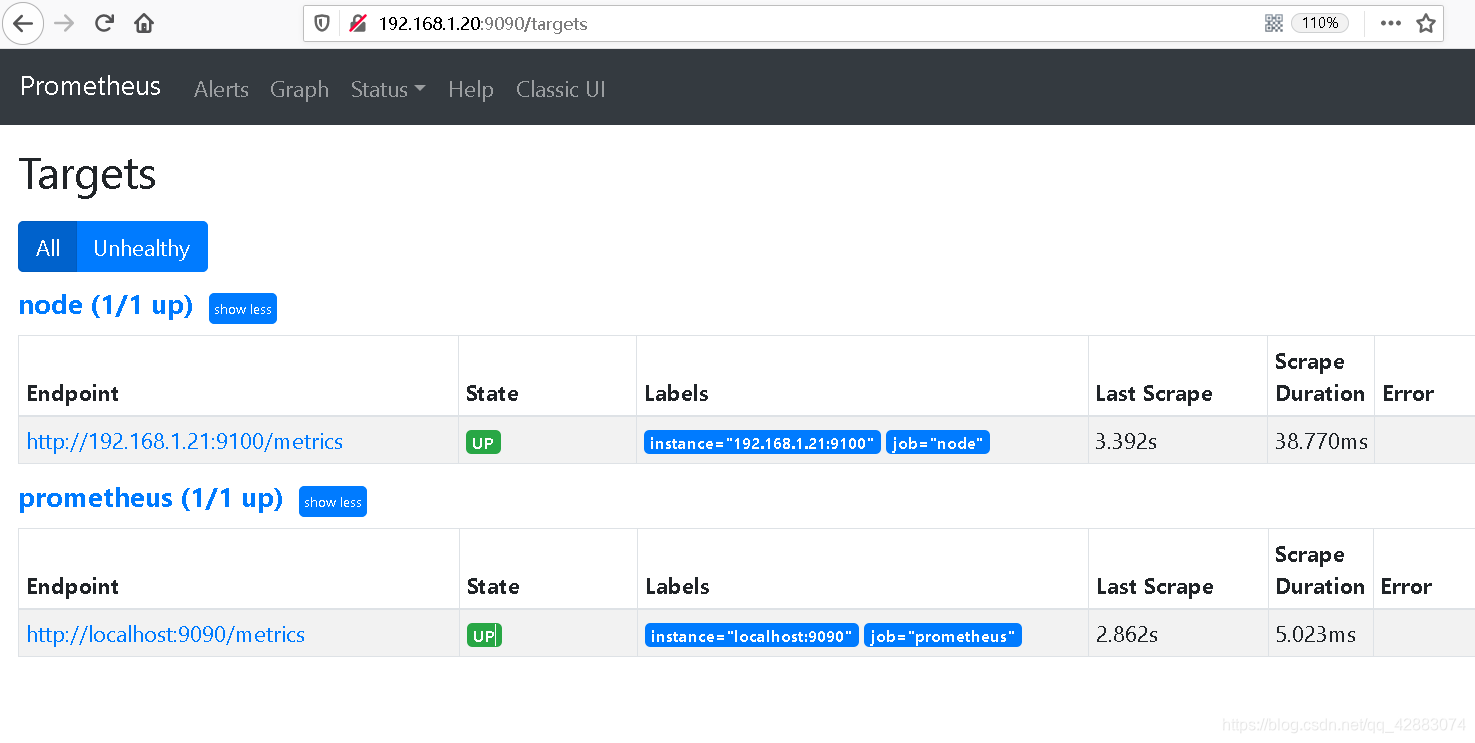
5. 查看node节点资源信息
我们这里看一下cpu的指标 (node_cpu_seconds_total)
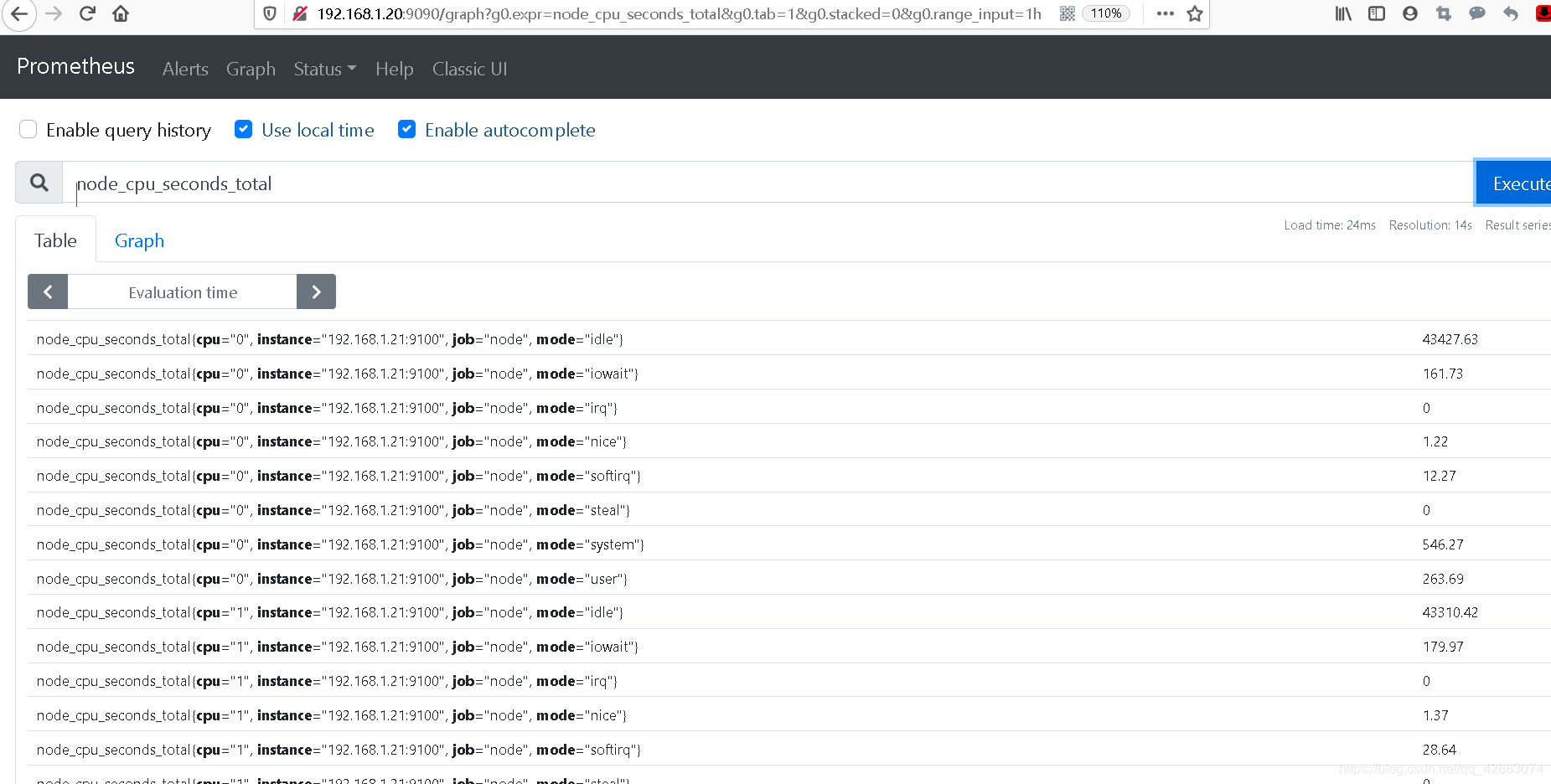
node_cpu_seconds_total{cpu="0", instance="192.168.1.21:9100", job="node", mode="idle"}
在服务器上cpu的数量也是从0开始的,0代表第一颗CPU
后面的标签,标注主机地址,job名称、模式等
node-exporter默认会收集大量的系统资源,感兴趣的去官网看吧
三. 自定义收集指标(textfile收集器)
#收集器是通过扫描指定的目录的文件,提取所有格式为prometheus指标的字符串,然后暴露出来
#在获取自定义指标时特别有用,这些自定义指标可能是批处理或corn作业等无法抓取的,
#也可能是没有exporter的源,甚至是为主机提供上下文的静态指标
#创建自定义指标规则
mkdir -p /var/lib/node_exporter/textfile_collector
#创建
echo 'metadata{role="docker_server",datacenter="SH"} 1' > /var/lib/node_exporter/textfile_collector/metadata.promvi /usr/lib/systemd/system/node-exporter.service
[Unit]
Description=Node Exporter
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
User=root
ExecStart=/usr/bin/node_exporter \
--collector.textfile.directory /var/lib/node_exporter/textfile_collector #换行添加
Restart=on-failure
[Install]
WantedBy=multi-user.target
重启服务
systemctl daemon-reload
systemctl restart node-exporter
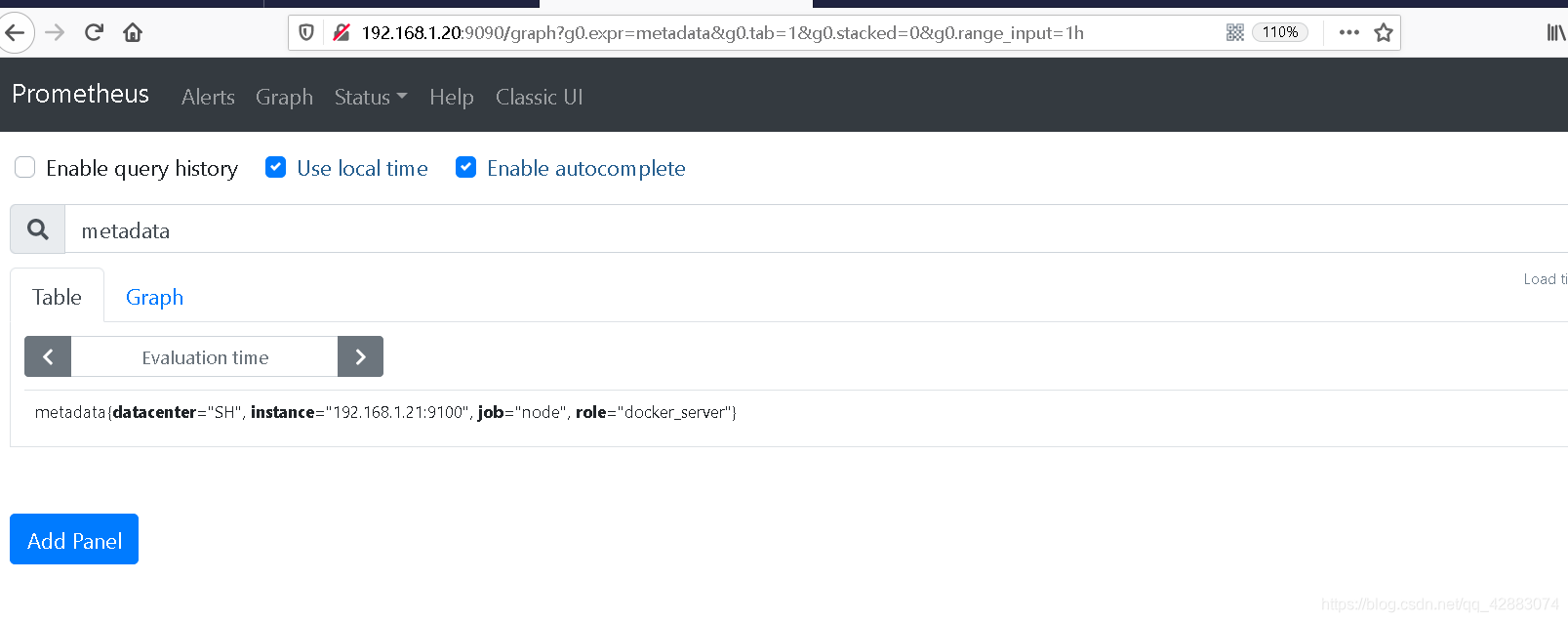
四 服务指标收集(systemd收集器)
systemd收集器默认收集了众多指标,如果只想收集某些服务的话,则添加
--collector.systemd 即可
vi /usr/lib/systemd/system/node-exporter.service
[Unit]
Description=Node Exporter
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
User=root
ExecStart=/usr/bin/node_exporter \
--collector.textfile.directory /var/lib/node_exporter/textfile_collector \
--collector.systemd #换行添加
Restart=on-failure
[Install]
WantedBy=multi-user.target
重启服务
systemctl daemon-reload
systemctl restart node-exporter我们这里以查看docker服务为例 node_systemd_unit_state{name="docker.service"}
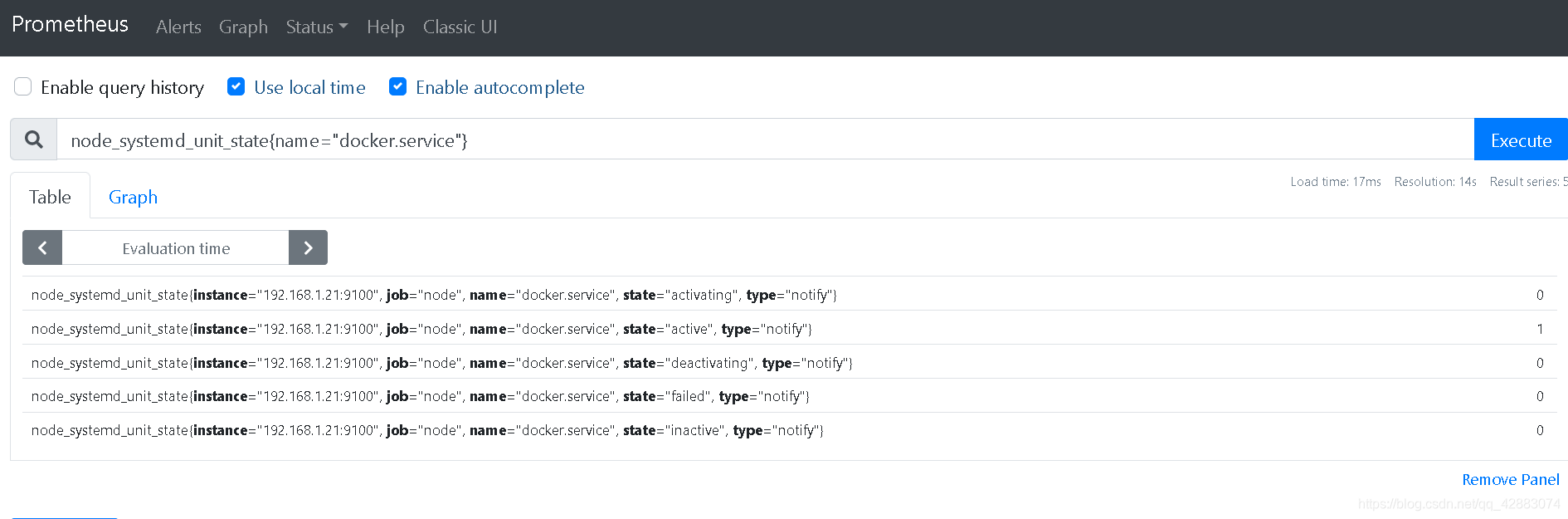
可以看到在状态state="active"的结尾处,数值等于1 表示这是正常运行的
通常我们做报警经常会用到这种状态值 ~( ̄▽ ̄)~*
五 过滤器
默认node-exporter会提供数十种类型的指标进行收集,但是并不是所有的指标都需要监控
我们可以通过过滤来筛选我们要收集那种类型的指标数据,来减少各种资源的消耗
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
metrics_path: /metrics
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.1.21:9100']
params: #添加以下配置
collect[]:
- cpu
- meminfo
- diskstats
- netdev
- systemd
重载配置
curl -X POST http://192.168.1.20:9090/-/reload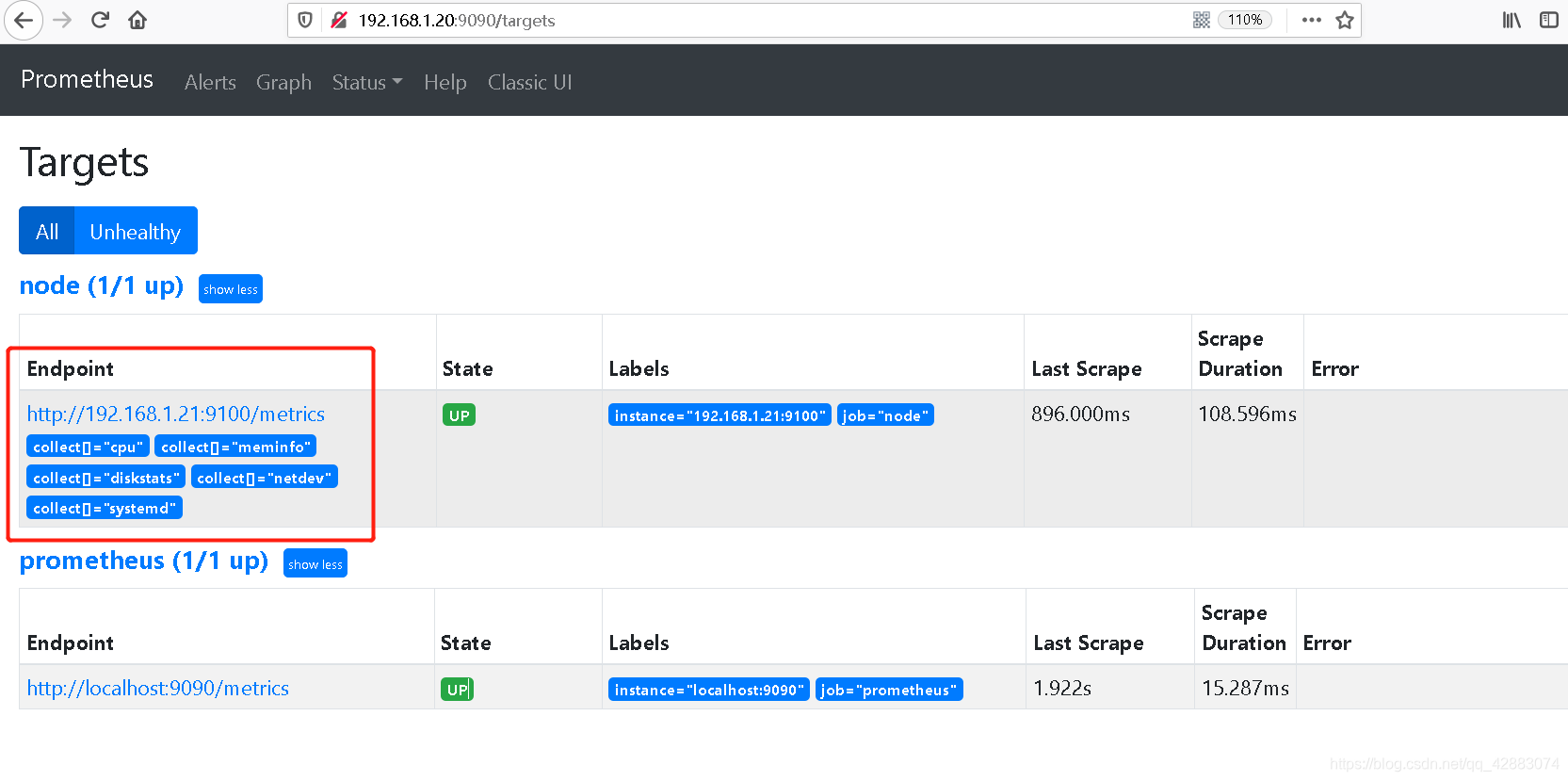
六. 监控docker容器(cadvisor)
cadvisor是一个暴露docker容器指标的工具。通常作为一个容器部署。从容器守护进程和Linux cgroups收集数据
部署
docker run --publish=8081:8080 --detach=true --name cadvisor google/cadvisor访问页面
192.168.1.20:8081

查看指标收集
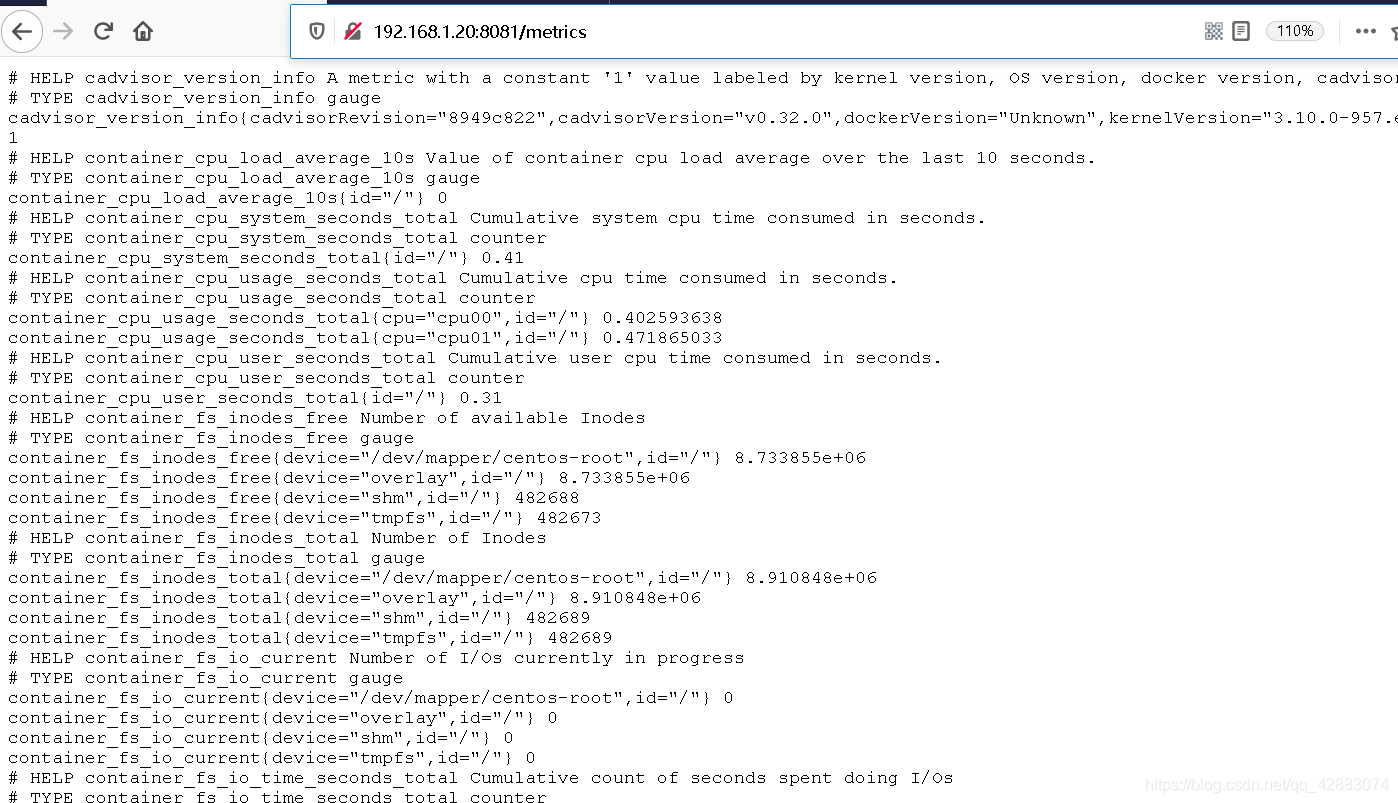
配置prometheus采集
vi /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
metrics_path: /metrics
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.1.21:9100']
params:
collect[]:
- cpu
- meminfo
- diskstats
- netdev
- systemd
- job_name: 'docker' #添加
static_configs:
- targets: ['192.168.1.20:8081']
重载配置
curl -X POST http://192.168.1.20:9090/-/reload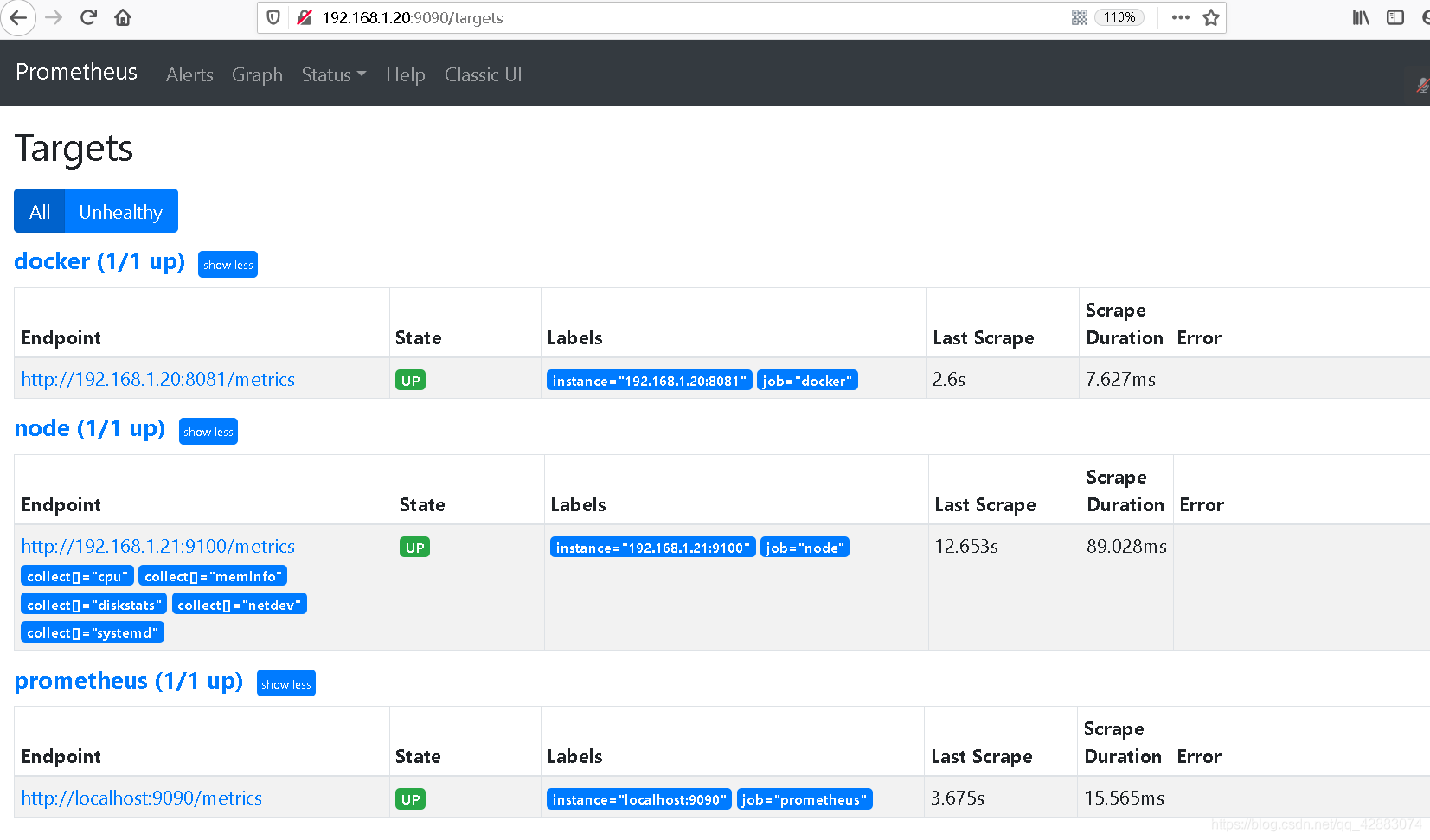
小技巧
我们在写配置文件的时候容易串行,为了方便检查提供了一个工具promtool
promtool check configs /etc/prometheus/prometheus.yml

















 8783
8783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









