







 本文介绍了Python爬虫中如何使用MongoDB和Redis进行数据管理。MongoDB用于存储大量数据,而Redis作为缓存和队列保存临时数据。通过PyMongo和Redis-py库,详细讲解了如何进行数据的插入、查找、更新、删除、排序、去重以及优化建议。同时,给出了实际的爬虫实践案例,涉及如何将小说章节链接存入Redis,然后爬取内容并存储到MongoDB。
本文介绍了Python爬虫中如何使用MongoDB和Redis进行数据管理。MongoDB用于存储大量数据,而Redis作为缓存和队列保存临时数据。通过PyMongo和Redis-py库,详细讲解了如何进行数据的插入、查找、更新、删除、排序、去重以及优化建议。同时,给出了实际的爬虫实践案例,涉及如何将小说章节链接存入Redis,然后爬取内容并存储到MongoDB。
爬虫学习[4]
原书《Python爬虫开发:从入门到实战(微课版)》
Python与数据库
■ 使用爬虫可以在短时间内积累大量数据。在本书的前面章节中,数据是通过文本文件来存放的。这种方式存放少量数据没有问题,但是一旦数据量太大,就会变得难以检索,难以管理。因此,我们有必要学习使用数据库来保存、管理和检索数据。
主要使用MongoDB和Redis这两个数据库。其中MongoDB用来保存大量数据,Redis用于作为缓存和队列保存临时数据。
MongoDB
MongoDB基本情况
MongoDB是一款基于C++开发的开源文档数据库,数据在MongoDB中以Key-Value的形式存储,就像是Python中的字典一样。使用MongoDB管理软件RoboMongo,可以看到数据在MongoDB中的存储方式如图6-1所示。需要注意的是,RoboMongo已经被Studio 3T所在的3T Software Labs收购,因此RoboMongo的后续版本改名为Robo 3T。Robo 3T与RoboMongo除了名字不一样以外,其他地方都是一样的。
ubuntu安装MangoDB比较简单,直接使用
sudo apt-get install mongodb
参考资料
在Ubuntu下,默认设置MongoDB是随Ubuntu启动自动启动的
输入以下命令查看是否启动成功:
pgrep mongo -l
启动与关闭
service mongodb start
service mongodb stop
就像mysql可以使用shell进行管理,也可以使用Navicat for MySQL图形化工具进行管理一样,mongoDB也存在图形化管理工具—RoboMongo

RoboMongo是一个跨平台的MongoDB管理工具,可以在图形界面中查询或者修改MongoDB
windos用户安装
ubuntu用户安装
由于帖子时间比较久远,与帖子上的安装过程有所差异,下载解压后是一个sh文件,执行它就可以完成安装了。
在Ubuntu上安装完成的结果
 了解RoboMongo的使用请戳我
了解RoboMongo的使用请戳我
数据在MongoDB中是按照“库(Database)”—“集合(Collections)”—“文档(Document)”的层级关系来存储的。如果使用Python的数据结构来做类比的话,文档相当于一个字典,集合相当于一个包含了很多字典的列表,库相当于一个大字典,大字典里面的每一个键值对都对应了一个集合,Key为集合的名字,Value就是一个集合。
既然MongoDB和Python的关系那么近,那么Python里面的数据是否可以非常方便地插入到MongoDB呢?MongoDB中的数据又能否非常方便地读到Python中呢?答案是能。这就需要用到PyMongo这个第三方库来实现了。
其安装非常简单,使用一行命令即可
pip install pymongo
PyMongo的使用
(1)使用PyMongo初始化数据库
要使用PyMongo操作MongoDB,首先需要初始化数据库连接。如果MongoDB运行在本地计算机上,而且也没有修改端口或者添加用户名及密码,那么初始化MongoClient的实例的时候就不需要带参数,直接写为:
from pymongo import MongoClient
client=MongoClient()
而如果MongoDB运行在其他服务器上面的,那么就需要使用“URI(UniformResource Identifier,统一资源标志符)”来指定连接地址。MongoDB URI的格式为:
'mongodb://ID:Password@IP:port'
如果服务器没有ID与密码那么可以省略,URL化为
'mongodb://@IP:port'
完整的部分如下
from pymongo import MongoClient
client=MongoClient('mongodb://ID:Password@IP:port')
PyMongo初始化数据库与集合有两种方式。
方法一:
from pymongo import MongoClient
client=MongoClient()
database=client['Chapter6']#库名即为Chapter6
collection=database['spider']#集合名即为spider
方法二
from pymongo import MongoClient
client=MongoClient()
db_name='Chapter6'
col_name='spider'
database=client[db_name]
collection=database[col_name]
这两种方法效果是一样的,但第二种方法普适性更好,当需要批量操作数据库的时候,可以使用循环操作。
默认情况下,MongoDB只允许本机访问数据库。这是因为MongoDB默认没有访问密码,出于安全性的考虑,不允许外网访问。若需要从外网访问数据库,那么需要修改安装MongoDB时用到的配置文件mongod.conf。建议在非必要情况下不允许外网访问MongoDB。
如果实在有必要开放外网访问戳我
(2)插入数据
MongoDB的插入操作非常简单。用到的方法为insert(参数),插入的参数就是Python的字典。
from pymongo import MongoClient
client=MongoClient()
db_name='Chapter6'
col_name='spider'
database=client[db_name]
collection=database[col_name]
data={'id':100,'name':'apple','age':20}
collection.insert(data)
插入结果
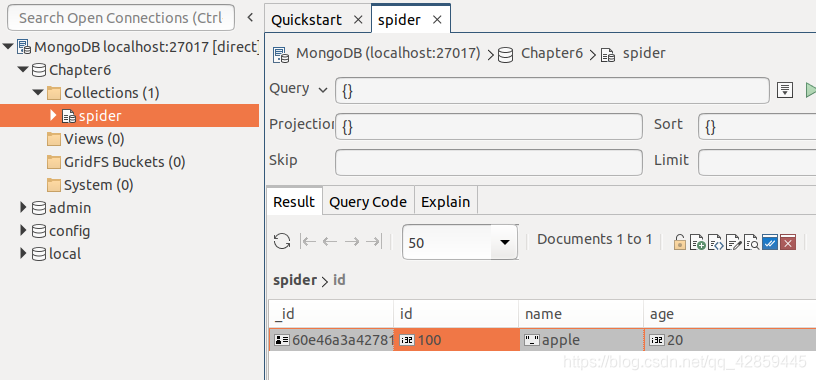 MongoDB会自动添加一列“_id”,这一列里面的数据叫作ObjectId, ObjectId是在数据被插入MongoDB的瞬间,通过一定的算法计算出来的。因此,_id这一列就代表了数据插入的时间,它不重复,而且始终递增。通过一定的算法,可以把ObjectId反向恢复为时间。
MongoDB会自动添加一列“_id”,这一列里面的数据叫作ObjectId, ObjectId是在数据被插入MongoDB的瞬间,通过一定的算法计算出来的。因此,_id这一列就代表了数据插入的时间,它不重复,而且始终递增。通过一定的算法,可以把ObjectId反向恢复为时间。
将多个字典放入列表中,并将列表作为insert()方法的参数,即可实现批量插入数据,如:
from pymongo import MongoClient
client=MongoClient()
db_name='Chapter6'
col_name='spider'
database=client[db_name]
collection=database[col_name]
data={'id':100,'name':'apple','age':20}
more_data=[
{'id':101,'name':'banana','age':30},
{'id':102,'name':'cat','age':40},
{'id':103,'name':'dog','age':50},
{'id':104,'name':'egg','age':60}
]
# collection.insert(data)
collection.insert(more_data)
插入结果:
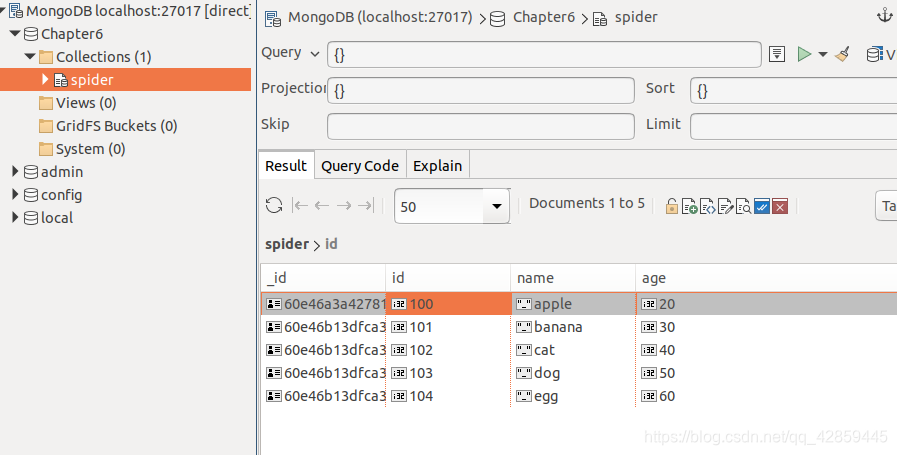 在爬虫开发中,主要用MongoDB来存储数据。所以爬虫主要用到的MongoDB方法就是这个insert()方法。
在爬虫开发中,主要用MongoDB来存储数据。所以爬虫主要用到的MongoDB方法就是这个insert()方法。
(3)普通查找
MongoDB的查找功能对应的方法是:
find(查询条件,返回子段)
find()方法的第1个参数设定查询条件
find()方法的第2个参数指定返回内容。这个参数是一个字典,Key就是字段的名称,Value是0或者1,0表示不返回这个字段,1表示返回这个字段。其中_id比较特殊,必须人工指定它的值为0,这样才不会返回。而对于其他数据,应该统一使用返回,或者统一使用不返回。只有_id是一个例外,必须要指定“’_id’: 0”,才不会返回,否则默认都要返回。
示例如下:
content=[x for x in collection.find()] #查找数据库当前集合下所有数据
content=[x for x in collection.find({'age':40})] #查找数据库当前集合下,满足‘age’=40的数据
content=[x for x in collection.find({'age':40},{'_id':0,'name':1})]#查找数据库当前集合下,满足‘age’=40的数据,并只返回name的值
(4)逻辑查询
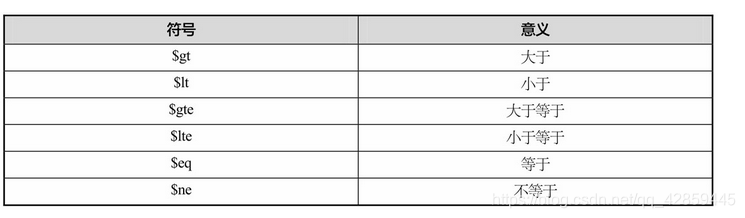
PyMongo也支持大于、小于、大于等于、小于等于、等于、不等于这类逻辑查询。它们对应的关键词如表所示
 用法示例:
用法示例:
content=[x for x in collection.find({'age':{'$gt':20}})]#查询所有age>20的记录
content=[x for x in collection.find({'age':{'$gte':20,'$lte':40}})]#查询所有20<=age<=40的记录
content=[x for x in collection.find({'age':{'$ne':20}})]#查询所有age!=20的记录
(5)对查询结果排序
MongoDB支持对查询到的结果进行排序。排序的方法为sort()。它的格式为:
collection.find().sort('列名',1或-1)
sort()方法接收两个参数:第1个参数指明需要以哪一项进行排序;第2个参数-1表示降序,1表示升序。
(6)更新记录
更新可使用update_one()和update_many()方法。它们的格式为:
collection.update_one(参数1,参数2)
collection.update_many(参数1,参数2)
前者只更新一条信息,后者更新所有符合要求的信息。这里的参数1和参数2都是字典,都不能省略。参数1用来寻找需要更新的记录,参数2用来更新记录的内容。请看代码:
collection.update_one({'age':20},{'$set':{'name':'cai'}})
collection.update_many({'age':20},{'$set':{'name':'cai'}})
第1行代码的作用是,将第1个年龄为20岁的人的名字改为cai。
第2行代码的作用是,将所有年龄为20岁的人的年龄全部改为cai。
(7)删除记录
删除可使用delete_one()和delete_many()方法。它们的格式为:
collection.delete_one(参数)
collection.delete_many(参数)
第1行代码的作用是,删除第一条满足条件的记录
第2行代码的作用是,删除所有满足条件的记录
(8)对查询结果去重
去重使用distinct()方法,其格式为:
collection.distinct('列名')
比如我们想统计当前集合里面的人有哪些不同的年龄,我们可以使用
collection.distinct('age')
MongoDB的优化建议
1.少读少写少更新
虽然MongoDB相比于MySQL来说,速度快了很多,但是频繁读写MongoDB还是会严重拖慢程序的执行速度。
建议把要插入到MongoDB中的数据先统一放到一个列表中,等积累到一定量再一次性插入。对于读数据,在内存允许的情况下,应该一次性把数据读入内存,尽量减少对MongoDB的读取操作
如果需要批量更新,首先将数据读入内存,更新之后,写入一个新的集合,将需要进行更新的集合删除,再将新的集合改名为需要进行跟新的集合的名字。
2.能用Redis就不用MongoDB
在什么情况下可以使用Redis来代替MongoDB呢?举一个最常见的例子:判断重复。例如爬取百度贴吧,在帖子列表页可以爬到每个帖子的标题和详情页的网址。如果对某一个帖子有兴趣,就从详情页网址爬进去抓取这个帖子的详细信息。由于需要节省资源,提高抓取速度,因此决定每天只爬新增加的帖子,已经爬过的帖子就不再重复爬取。
解决这个问题,其实要实现的功能很简单。在保存数据的时候,把每个帖子的网址也保存到数据库中。爬虫在爬详情页之前,先去MongoDB中查看这个URL是否已经存在。如果已经存在就不爬详情页;如果不存在,就继续爬这个帖子的详情页。这种办法当然可以实现这个需求,但是由于在前面已经说了,频繁读/写MongoDB是非常浪费时间的,因此这种办法效率并不高。
为了提高效率,就需要引入Redis。由于Redis是基于内存的数据库,因此即使频繁对其读/写,对性能的影响也远远小于频繁读/写MongoDB。在Redis中创建一个集合“crawled_url”,爬虫在爬一个网址之前,先把这个网址sadd到这个集合中。如果返回为1,那么表示这个网址之前没有爬过,爬虫需要去爬取详情页。如果返回0,表示这个网址之前已经爬过了,就不需要再爬了。示例代码片段如下:
Redis
Redis基本情况
Redis是一个基于内存的数据库,它的速度远远快过MongoDB,而且Redis比MongoDB还要简单。
安装教程
与MongoDB不一样,要使用Redis的各种简单功能,只需要使用Redis自带的交互环境即可,没有必要安装一个第三方的客户端。在安装了Redis以后,先启动Redis-Server,接着启动Redis的交互环境。对于使用Homebrew安装Redis的Mac OS,进入Redis交互环境非常简单,打开终端输入redis-cli,并按Enter键即可。对于Ubuntu和Windows,需要先在终端或者CMD下进入Redis的安装文件夹,然后在里面运行命令redis-cli来启动Redis的交互环境。
在Redis中有多种不同的数据类型。不同的数据类型有不同的操作方法。在爬虫开发的过程中主要会用到Redis的列表与集合,因此本小节讲解这两种数据类型不同的操作方式。Redis的列表是一个可读可写的双向队列,可以把数据从左侧或者右侧插入到列表中,也可以从左侧或者右侧读出数据,还可以查看列表的长度。从左侧写数据到列表中,使用的关键字为“lpush”,这里的“l”为英文“left”(左)的首字母。使用方法为:
(1)列表
lpush key value1 value2 ..
如果想从列表左侧读出数据,使用的关键字为“lpop”,这里的“l”也是“left”的首字母。例如:
lpop key
如果想查看一个列表的长度,可使用关键字为“llen”。这个关键字的第1个“l”对应的是英文“list”(列表)的首字母
lpop一次只会读最左侧的一个数据,并且在返回数据的时候会把这个数据从列表中删除。这一点和Python列表的pop是一样的。
如果不删除列表中的数据,又要把数据读出来,就需要使用关键字“lrange”,这里的“l”对应的是英文“list”的首字母。”lrange”的使用格式为:
lrange key start end
需要特别注意的是,在Python中,切片是左闭右开区间,例如,test[0:3]表示读列表的第0、1、2个共3个值。但是lrange的参数是一个闭区间,包括开始,也包括结束。
(2)集合
Redis的集合与Python的集合一样,没有顺序,值不重复。往集合中添加数据,使用的关键字为“sadd”。这里的“s”对应的是英文单词“set”(集合)。使用格式为:
sadd key value1 value2 ..
集合中读数据,使用的关键字为spop,使用方法为
spop key count
其中,count表示需要读多少个值出来。如果省略count,表示读一个值。
spop也会在读了数据以后将数据从集合中删除。在爬虫的开发过程中,Redis的集合一般用于去重的操作,因此很少会把数据从里面读出来。要判断一个网址是否已经被爬虫爬过,只需要把这个网址sadd到集合中,如果返回1,表示这个网址还没有被爬过,如果返回0,表示这个网址已经被爬过了。
如果需要查看集合中有多少个值,可以使用关键字scard。它的使用格式为
scard key
Redis-py的使用
在Python中使用Redis-py,只需要简单的两步:连接Redis,操作Redis。
(1)连接Redis
在Python中连接Redis,只需要两行代码。
import redis
client=redis.StrictRedis()
如果不是连接到本地而是连接到服务器,需要声明ip port并提供password
(2)操作Redis
操作Redis所用到的方法、单词拼写和Redis交互环境完全一致。例如,要往Redis的列表左侧添加一个数字,只需要写如下的代码:
将123添加到列表的左侧
import redis
client=redis.StrictRedis()
client.lpush('列表',123)
总结
MongoDB主要用来存放爬虫爬到的各种需要持久化保存的数据,而Redis则用来存放各种中间数据。通过减少频繁读/写MongoDB,并使用Redis来弥补MongoDB的一些不足,可以显著提高爬虫的运行效率。
实践
声明:本次实践仅仅是为了练习爬虫技术,请支持正版书籍
目标网站:http://book.sbkk8.com/waiguo/dongyeguiwu/baiyexing/
目标内容:小说《白夜行》正文内容。
任务要求:编写两个爬虫,爬虫1从目标网站获取小说《白夜行》第一章到第十三章的网址,并将网址添加到Redis里名为url_queue的列表中。爬虫2从Redis里名为url_queue的列表中读出网址,进入网址爬取每一章的具体内容,再将内容保存到MongoDB中。
首先查看网站的源代码:
 所有的链接都在"mulu"下,而"mulu"下又有很多"mululist",每个"mululist"都有一个链接。
所有的链接都在"mulu"下,而"mulu"下又有很多"mululist",每个"mululist"都有一个链接。
整体的结构如图:

使用XPath获取每一章的网址,再将它们添加到Redis中。其代码如下:
def get_toc(html_cin):
'''
获取每一章的链接并保存进redis之中
:param html:目录页的源代码
:return:每一章节的链接
'''
home_url = "http://book.sbkk8.com"
selector=lxml.html.fromstring(html_cin)
toc_block1=selector.xpath("//div[@class='mulu']/ul/li/a/@href")
for i in toc_block1:
charpter_url=home_url+i
redis_client.lpush('url_queue',charpter_url)
print("Redis finishes work!")
打开redis客户端,发现数据已经存入。
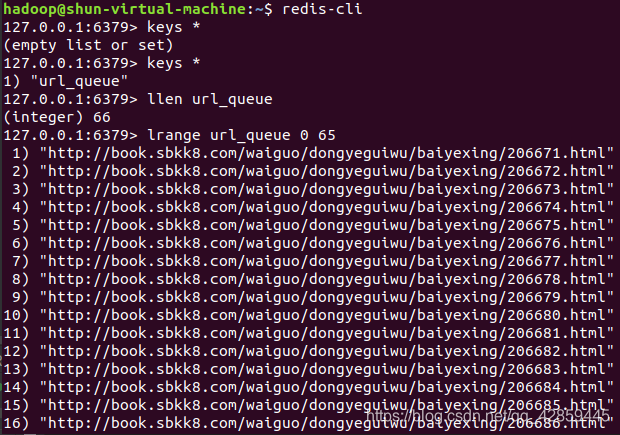 对于爬取正文的爬虫,只要发现Redis里的url_queue这个列表不为空,就要从里面读出网址,并爬取数据。因此,其代码如下
对于爬取正文的爬虫,只要发现Redis里的url_queue这个列表不为空,就要从里面读出网址,并爬取数据。因此,其代码如下
def get_and_save():
"""
获取每一章的章节名和正文名并保存进MongoDB之中
:param html:正文的源码
:return:章节名,正文
"""
content_list=[]
while redis_client.llen('url_queue')>0:
charpter_url = redis_client.rpop('url_queue').decode()
source=requests.get(charpter_url).content.decode('GBK')
selector=lxml.html.fromstring(source)
charpter_name=selector.xpath("//div[@id='maincontent']/h1[@class='articleH1']/text()")[0]
content=selector.xpath("//div[@id='content']/p/text()")
content=''.join(content)
content_list.append({'title':charpter_name,'content':content})
print(charpter_name)
collection.insert(content_list)
print("MongoDB Done!")
这时redis中列表被清除,而mongoDB会保存小说内容
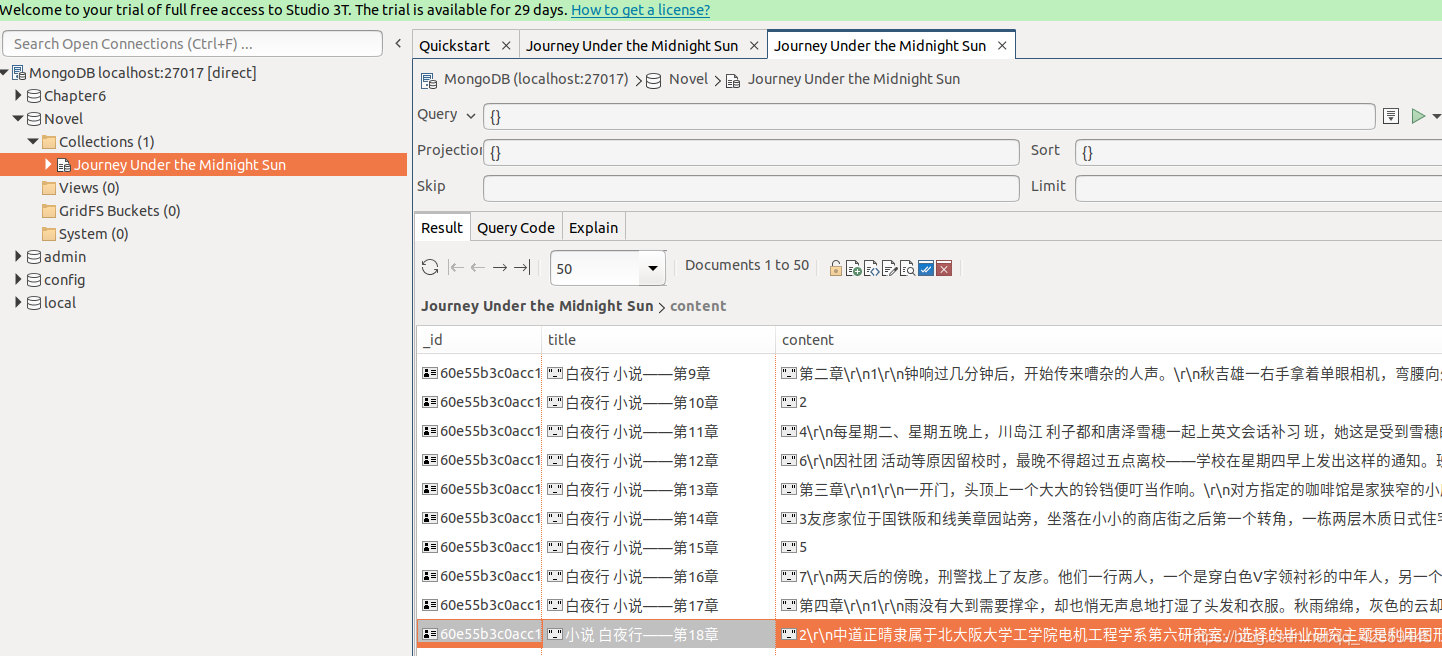 其中:
其中:
白夜行 小说——第15章 存在问题,查看源代码后发现这一章的格式与其他章节不同:
其他章节:
 十五章:
十五章:
 比较特殊,可以单独对其处理。
比较特殊,可以单独对其处理。
此外,这次书写的时候出现了Max retries exceeded with url 的报错,查询后,这要么是http连接太多没有关闭导致的要么是访问次数频繁,被禁止访问。
解决方法
尝试后发现问题是http没有及时关闭。
完整代码如下:
import lxml.html
import requests
import redis
from pymongo import MongoClient
import time
start_url="http://book.sbkk8.com/waiguo/dongyeguiwu/baiyexing/"
def get_toc(html_cin):
'''
获取每一章的链接并保存进redis之中
:param html:目录页的源代码
:return:每一章节的链接
'''
home_url = "http://book.sbkk8.com"
selector=lxml.html.fromstring(html_cin)
toc_block1=selector.xpath("//div[@class='mulu']/ul/li/a/@href")
for i in toc_block1:
charpter_url=home_url+i
redis_client.lpush('url_queue',charpter_url)
print("Redis finishes work!")
def get_and_save():
"""
获取每一章的章节名和正文名并保存进MongoDB之中
:param html:正文的源码
:return:章节名,正文
"""
content_list=[]
while redis_client.llen('url_queue')>0:
charpter_url = redis_client.rpop('url_queue').decode()
source=requests.get(charpter_url).content.decode('GBK')
selector=lxml.html.fromstring(source)
charpter_name=selector.xpath("//div[@id='maincontent']/h1[@class='articleH1']/text()")[0]
content=selector.xpath("//div[@id='content']/p/text()")
content=''.join(content)
content_list.append({'title':charpter_name,'content':content})
print(charpter_name)
collection.insert(content_list)
print("MongoDB Done!")
if __name__ == "__main__":
mongo_client = MongoClient()
redis_client = redis.StrictRedis()
db_name='Novel'
col_name='Journey Under the Midnight Sun'
database=mongo_client[db_name]
collection=database[col_name]
requests.DEFAULT_RETRIES = 5 # 增加重试连接次数
s = requests.session()
s.keep_alive = False # 关闭多余连接
mulu=requests.get(start_url).content.decode('GBK')
get_toc(mulu)
get_and_save()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









