







 本文围绕XML解析展开,介绍了JAXP相关知识,包括其组成和获取解析器对象的方法。详细阐述了SAX和DOM两种解析方式的原理、特点及操作步骤,还提及了Dom4j库,说明了其优势、获取Document对象的方式及开发时导入jar包的方法,可完成XML文件的增删改查。
本文围绕XML解析展开,介绍了JAXP相关知识,包括其组成和获取解析器对象的方法。详细阐述了SAX和DOM两种解析方式的原理、特点及操作步骤,还提及了Dom4j库,说明了其优势、获取Document对象的方式及开发时导入jar包的方法,可完成XML文件的增删改查。
※ XML学习 W3CSchool.chm文件
※ XML解析器
JAXP介绍(Java API for XMLProcessing)
JAXP 是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成.
在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
(一)SAX解析
SAX:基于事件处理的机制
sax解析xml文件时,
遇到开始标签,结束标签,
开始解析文件,文件解析结束,字符内容,
空白字符等都会触发各自的方法。
优点:
适合解析大文件,对内存要求不高
轻量级的解析数据方式,效率更高
缺点:
不能随机解析
不能修改XML文件,只能进行查询
(二)DOM解析:
采用dom解析,会将xml文档全部载入到内存当中,然后将xml文档
中的所有内容转换为tree上的节点(对象)。
优点:
可以随机解析
可以修改文件
可以创建xml文件
缺点:
适合解析小文件,对内存要求高
获得JAXP中的DOM解析器步骤
1调用 DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。
2调用工厂对象的 newDocumentBuilder方法得到 DOM 解析器对象。
3调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进行可以利用DOM特性对整个XML文档进行操作了。
JAXP的dom解析
例如:
//获得生产DocumentBuilder对象的工厂实例
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//设置是否支持名称空间 默认是不支持
factory.setNamespaceAware(true);
//通过工厂获得一个DocumentBuilder对象
DocumentBuilder builder = factory.newDocumentBuilder();
//获得Document对象,可以表示一个xml文档
Document document = builder.parse(fileName);
//获得根元素
//注意Document和Element都是Node的子接口
Element root = document.getDocumentElement();
//获得根元素下面的所有子元素
//注意回车换行也算是一个节点(文本节点)
//xml文件中主要是文本节点和元素节点
//元素节点中还包含属性节点
//我们要解析的值就在这些节点中
//这一步之后就是循环解析节点中的数据
NodeList rootChildNodes = root.getChildNodes();在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构建代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,严重情况下可能还会导致内存溢出。
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。
sax解析器在发现xml文档中的内容时就会调用你重新之后的方法. 如何处理这些内容,由程序员自己决定。
在基于sax 的程序中,有五个最常用sax事件
startDocument() —> 解析器发现了文档的开始标签
endDocument() —> 解析器发现了文档结束标签
startElement() —> 解析器发现了一个起始标签
character() —> 解析器发现了标签里面的文本值
endElement() —> 解析器发现了一个结束标签
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
使用SAXParserFactory创建SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
通过SAX解析工厂得到解析器对象
SAXParser sp = spf.newSAXParser();
将解析对象和事件处理器对象关联
sp.parse(“src/class.xml”, new DefaultHandler(){…});
Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXP也用了Dom4j。
使用Dom4j开发,需下载dom4j相应的jar文件。
DOM4j中,获得Document对象的方式有三种:
开发dom4j要加入新jar包,并且在倒包时要导入dom4j的包
1.读取XML文件,获得document对象
SAXReader reader = new SAXReader();
Document document = reader.read(new File(“src/input.xml"));2.解析XML形式的文本,得到document对象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);3.主动创建document对象.
Document document = DocumentHelper.createDocument();
//创建根节点
Element root = document.addElement("members");※ 解析器原理
xml文件中储存的是对象类中构建对象的数据,怎样对xml文件中数据进行增删改查呢?为了获得xml文件的信息,建立解析器。
<!--stu.xml文件-->
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<students>
<student id="1">
<name>tom</name>
<age>33</age>
</student>
<student id="2">
<name>jake</name>
<age>23</age>
</student>
<student id="3">
<name>lili</name>
<age>65</age>
</student>
</students>
//对应的Java对象类
package com.xml.dom;
public class Student {
private long id;
private String name;
private int age;
public Student() {
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ", age=" + age + "]";
}
public Student(long id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
//原理解析
//类似数组查询先找到要的信息,在进行修改
package com.xml.dom;
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
//构建一个数组
String str="id=\"23\"";
// 判断数组是否包含id
// System.out.println(str.contains("id"));
//以引号分割字符串,\转移字符
String[] strs=str.split("\"");
System.out.println(Arrays.toString(strs));//[id=, 23]
}
}
※ DOM解析器构建,完成XML文件增、删、改、查
※ 将XML文件信息分析成“树”
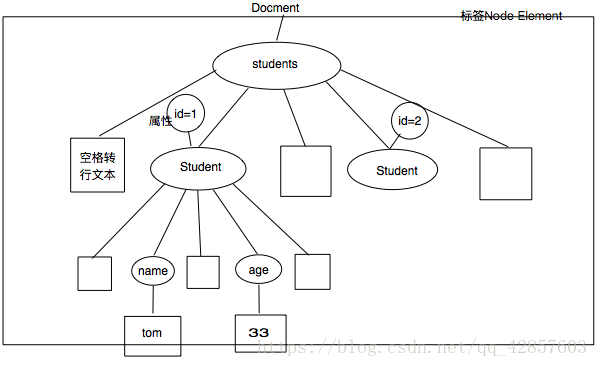
package com.xml.dom;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomParseTest {
//主方法
public static void main(String[] args) {
//List<Student> list=new DomParseTest().getAllStudent();
//for(Student s:list){
//System.out.println(s);
//}
//new DomParseTest().addStudent(
//new Student(4, "wangwu", 67));
new DomParseTest().deleteStudent(4);
}
/*
*构建解析器并获得XML文件整个“树”
*/
public List<Student> getAllStudent(){
List<Student> stus=new ArrayList<>();
//构建产生解析器的工厂
DocumentBuilderFactory dbf=
DocumentBuilderFactory.newInstance();
//构建解析器
try {
DocumentBuilder builder=
dbf.newDocumentBuilder();
//解析器读取文件,把xml文件内容装载到内存转化为tree
// builder.parse(new File(""));
// builder.parse(new FileInputStream(""))
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
//获取一级标签(根标签)
Element root=doc.getDocumentElement();
// System.out.println(root);
//获取标签的名字
// System.out.println(root.getNodeName());
//获取二级标签
NodeList list=root.getChildNodes();
//获取集合中节点的的个数
//System.out.println(list.getLength());
//基于角标获取集合中的节点
// System.out.println(list.item(0));
// System.out.println(list.item(1));
// System.out.println(list.item(2));
// System.out.println(list.item(3));
// System.out.println(list.item(4));
for(int i=0;i<list.getLength();i++){
Node node=list.item(i);
//node.getNodeType()获取单前节点的类型
//ELEMENT_NODE表示元素节点(标签)
//ATTRIBUTE_NODE属性节点
//TEXT_NODE文本节点
if(node.getNodeType()==Node.ELEMENT_NODE){
Student stu=new Student();
//获取标签中的所有的属性
NamedNodeMap map=node.getAttributes();
//基于属性名字获取特定的属性
Node attrnode=map.getNamedItem("id");
setStu(attrnode, stu);
// System.out.println(
// attrnode.getNodeName()+"="+attrnode.getNodeValue());
//获取三级标签
NodeList sanList=node.getChildNodes();
for(int j=0;j<sanList.getLength();j++){
Node san=sanList.item(j);
if(san.getNodeType()==Node.ELEMENT_NODE){
setStu(san, stu);
}
}
stus.add(stu);
}
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return stus;
}
/*
*设置对象的属性(查询)
*/
public void setStu(Node node,Student stu){
if(node.getNodeType()==Node.ATTRIBUTE_NODE){
//取属性节点的值
String id=node.getNodeValue();
stu.setId(Long.parseLong(id));
}else if(node.getNodeName().equals("name")){
//获取文本节点内容
String name=node.getTextContent();
stu.setName(name);
}else if(node.getNodeName().equals("age")){
String age=node.getTextContent();
stu.setAge(Integer.parseInt(age));
}
}
/*
*增加对象方法
*/
public void addStudent(Student stu){
DocumentBuilderFactory dbf=
DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=
dbf.newDocumentBuilder();
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
Element root=doc.getDocumentElement();
//构建元素节点
Element stunode=doc.createElement("student");
//给元素设置属性
stunode.setAttribute("id", stu.getId()+"");
Element namenode=doc.createElement("name");
namenode.setTextContent(stu.getName());
Element agenode=doc.createElement("age");
agenode.setTextContent(stu.getAge()+"");
//节点的挂载
stunode.appendChild(namenode);
stunode.appendChild(agenode);
root.appendChild(stunode);
//把内存中的树转化为流写入文件
/*
*转换器的作用就是把新生成的“树”转化为XML文件保存
*/
//构建转换器工厂
TransformerFactory tff=
TransformerFactory.newInstance();
//构建转换器
Transformer tf=tff.newTransformer();
//设置流写入文件的编码
tf.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//设置回车换行
tf.setOutputProperty(OutputKeys.INDENT, "yes");
//将dom以流的方式转入文件
tf.transform(new DOMSource(doc),
new StreamResult("src/com/xml/dom/stu.xml"));
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
*删除对象方法
*/
public void deleteStudent(long id){
DocumentBuilderFactory dbf=
DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=
dbf.newDocumentBuilder();
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
//基于标签名获取所有叫该名字的标签节点
NodeList stulist=
doc.getElementsByTagName("student");
for(int i=0;i<stulist.getLength();i++){
Node stun=stulist.item(i);
NamedNodeMap map=stun.getAttributes();
Node attr=map.getNamedItem("id");
String ids=attr.getNodeValue();
if(id==Long.parseLong(ids)){
//获取父节点
Node parent=stun.getParentNode();
parent.removeChild(stun);
}
}
//构建转换器工厂
TransformerFactory tff=
TransformerFactory.newInstance();
//构建转换器
Transformer tf=tff.newTransformer();
//设置流写入文件的编码
tf.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//设置回车换行
tf.setOutputProperty(OutputKeys.INDENT, "yes");
//将dom以流的方式转入文件
tf.transform(new DOMSource(doc),
new StreamResult("src/com/xml/dom/stu.xml"));
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
*更新对象方法
*/
public void updateStudent(Student stu){
DocumentBuilderFactory factory=
DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=
factory.newDocumentBuilder();
Document doc=
builder.parse("src/com/xml/dom/stu.xml");
NodeList list=
doc.getElementsByTagName("student");
for(int i=0;i<list.getLength();i++){
Node node=list.item(i);
NamedNodeMap map=node.getAttributes();
Node attr=map.getNamedItem("id");
String idv=attr.getNodeValue();
if(stu.getId()==Long.parseLong(idv)){
NodeList na=node.getChildNodes();
for(int j=0;j<na.getLength();j++){
Node nav=na.item(j);
if(nav.getNodeType()==Node.ELEMENT_NODE){
// System.out.println(nav.getChildNodes().item(0));//node
// System.out.println(nav.getFirstChild());//node
//System.out.println(nav.getFirstChild().getNodeValue());
if(nav.getNodeName().equals("name")){
//nav.setTextContent(stu.getName());
nav.getFirstChild().setNodeValue(stu.getName());
}else{
//nav.setTextContent(stu.getAge()+"");
nav.getChildNodes().item(0).setNodeValue(stu.getAge()+"");
}
}
}
}
}
TransformerFactory tff=
TransformerFactory.newInstance();
Transformer tf=tff.newTransformer();
tf.transform(new DOMSource(doc),
new StreamResult("src/com/xml/dom/stu.xml"));
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}※ SAX解析器构建,完成XML文件增、删、改、查
※ SAX解析原理图:
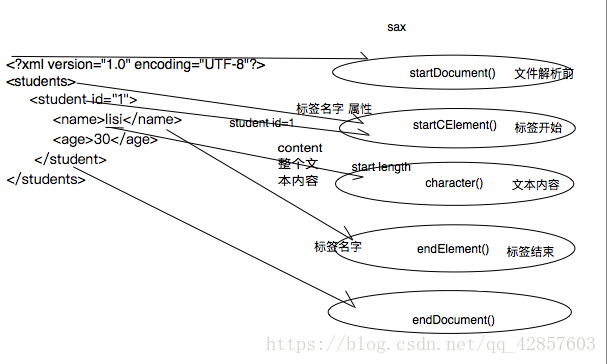
//SAX解析器遍历xml文件
package com.xml.sax;
import java.io.IOException;
import java.util.Arrays;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxparserT {
public void ParseXML(){
//构建解析器工厂
SAXParserFactory factory=
SAXParserFactory.newInstance();
//开启命名空间
factory.setNamespaceAware(true);
try {
SAXParser sax=factory.newSAXParser();
//读取文件,同时绑定事件处理器
sax.parse("src/com/xml/dom/stu.xml",
new DefaultHandler(){
//事件处理器的相关方法
//当开始读取xml文档对象的时候触发(一次)
public void startDocument ()
throws SAXException{
System.out.println("文档开始");
}
//当读取完根标签结束标签之后触发的方法
public void endDocument ()
throws SAXException{
System.out.println("文档结束");
}
//该方法处理的是空白文本及标签中间内容文本
//第一个表示整个文档内容
//第二个参数表示文本开始的角标
//第二个参数表示文本的长度
public void characters (char ch[], int start, int length)
throws SAXException{
//System.out.println("内容:"+new String(ch,start,length));
// System.out.println(new String(ch));
// System.out.println("内容:"+new String(ch,start,length)+
// "开始位置:"+start+"---长度"+length);
}
//当读取开始标签的时候触发
//命名空间生效的情况下
//uri 命名空间的内容
//localName 去掉前缀之后的标签名
//qName 标签的完整的名字(前缀+标签)
//命名空间不生效的情况
//uri和localName为空
//qName表示标签的名字
public void startElement (String uri, String localName,
String qName, Attributes attributes)
throws SAXException{
// System.out.println("uri:"+uri+
// " localName:"+localName
// +" qName:"+qName);
}
//当读取到结束标签的时候触发
public void endElement (String uri, String localName, String qName)
throws SAXException{
System.out.println("uri:"+uri+
" localName:"+localName
+" qName:"+qName);
}
});
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
new SaxparserT().ParseXML();
}
}
//SAX解析器添加对象
package com.xml.sax;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import com.xml.dom.Student;
public class SaxparserT1 {
public void ParseXML(){
//构建解析器工厂
SAXParserFactory factory=
SAXParserFactory.newInstance();
try {
SAXParser sax=factory.newSAXParser();
final List<Student> list=new ArrayList<>();
//读取文件,同时绑定事件处理器
sax.parse("src/com/xml/dom/stu.xml",
new DefaultHandler(){
private Student stu;
private boolean nameF;
private boolean ageF;
public void characters (char ch[], int start, int length)
throws SAXException{
if(nameF){
stu.setName(new String(ch,start,length));
}
if(ageF){
stu.setAge(Integer.parseInt(new String(ch,start,length)));
}
}
public void startElement (String uri, String localName,
String qName, Attributes attributes)
throws SAXException{
if(qName.equals("student")){
stu=new Student();
String id=attributes.getValue("id");
stu.setId(Long.parseLong(id));
}else if(qName.equals("name")){
nameF=true;
}else if(qName.equals("age")){
ageF=true;
}
}
public void endElement (String uri, String localName, String qName)
throws SAXException{
if(qName.equals("student")){
list.add(stu);
}else if(qName.equals("name")){
nameF=false;
}else if(qName.equals("age")){
ageF=false;
}
}
});
for(Student s:list){
System.out.println(s);
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
new SaxparserT1().ParseXML();
}
}※ DOM4F解析器构建,完成XML文件增、删、改、查
※ DOM4F的原理与DOM原理相同。都是构建“树”模型。
需要导入jar包(先在项目内建立一个名为jar的Folder文件夹。直接把jar:(dom4j-1.6.1.jar)粘贴进去。然后右击jar文件,找到Build-Path中的Add-to-Build-Path,发现JRE中多了个牛奶瓶子,说明导入成功。(jar包不能重复导入)
package com.xml.dom4j;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import com.xml.dom.Student;
public class Dom4JTest {
public List<Student> getAllStudent(){
List<Student> list=new ArrayList<>();
//构建解析器
SAXReader dom=new SAXReader();
try {
Document doc=
dom.read("src/com/xml/dom/stu.xml");
//获取根标签
Element root=doc.getRootElement();
//获取二级标签,只获取元素标签,忽略掉空白的
//文本
List<Element> ers=root.elements();
for(Element er:ers){
Student stu=new Student();
//获取名字
// String name=er.getName();
// System.out.println(name);
//获取所有的属性
// List<Attribute> attrs=er.attributes();
//获取属性的值
// System.out.println(attrs.get(0).getValue());
//获取单个属性
String id=er.attributeValue("id");
stu.setId(Long.parseLong(id));
List<Element> sans=er.elements();
for(Element san:sans){
if(san.getName().equals("name")){
// san.getText();
// san.getTextTrim();
// Object obj=san.getData();
stu.setName(san.getText());
}else if(san.getName().equals("age")){
stu.setAge(Integer.parseInt((String) san.getData()));
}
}
list.add(stu);
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
}
/*
*添加对象方法
*/
public void addStudent(Student stu){
SAXReader sax=new SAXReader();
try {
Document doc=
sax.read("src/com/xml/dom/stu.xml");
Element root=doc.getRootElement();
//添加元素的同时返回当前元素
Element stuE=root.addElement("student");
//设置元素属性
stuE.addAttribute("id", stu.getId()+"");
Element nameE=stuE.addElement("name");
//设置文本内容
nameE.setText(stu.getName());
Element ageE=stuE.addElement("age");
ageE.setText(stu.getAge()+"");
//移除元素
//root.remove(stuE);
//第一个参数表示路径,
//第二个参数表示格式
//不写格式输出的时候,新增加的内容直接一行插入
// XMLWriter writer=
// new XMLWriter(
// new FileOutputStream(
// "src/com/xml/dom/stu.xml"));
//OutputFormat format=OutputFormat.createPrettyPrint();
//docment中的tree全部转化为一行内入写入
OutputFormat format=OutputFormat.createCompactFormat();
XMLWriter writer=
new XMLWriter(
new FileOutputStream(
"src/com/xml/dom/stu.xml"),format);
writer.write(doc);
writer.flush();
writer.close();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
*删除对象方法
*/
public void remove(long id){
SAXReader sax=new SAXReader();
try {
Document doc=
sax.read("src/com/xml/dom/stu.xml");
Element root=doc.getRootElement();
List<Element> ers=root.elements();
for(Element er:ers){
String ids=er.attributeValue("id");
if(id==Long.parseLong(ids)){
er.getParent().remove(er);
break;
}
}
OutputFormat format=
OutputFormat.createPrettyPrint();
XMLWriter writer=
new XMLWriter(
new FileOutputStream(
"src/com/xml/dom/stu.xml"),format);
writer.write(doc);
writer.flush();
writer.close();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
new Dom4JTest().remove(3);
// new Dom4JTest().addStudent(
// new Student(3,"briup",55));
// List<Student> list=new Dom4JTest().getAllStudent();
// for(Student s:list){
// System.out.println(s);
// }
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









