






2024 ICLR
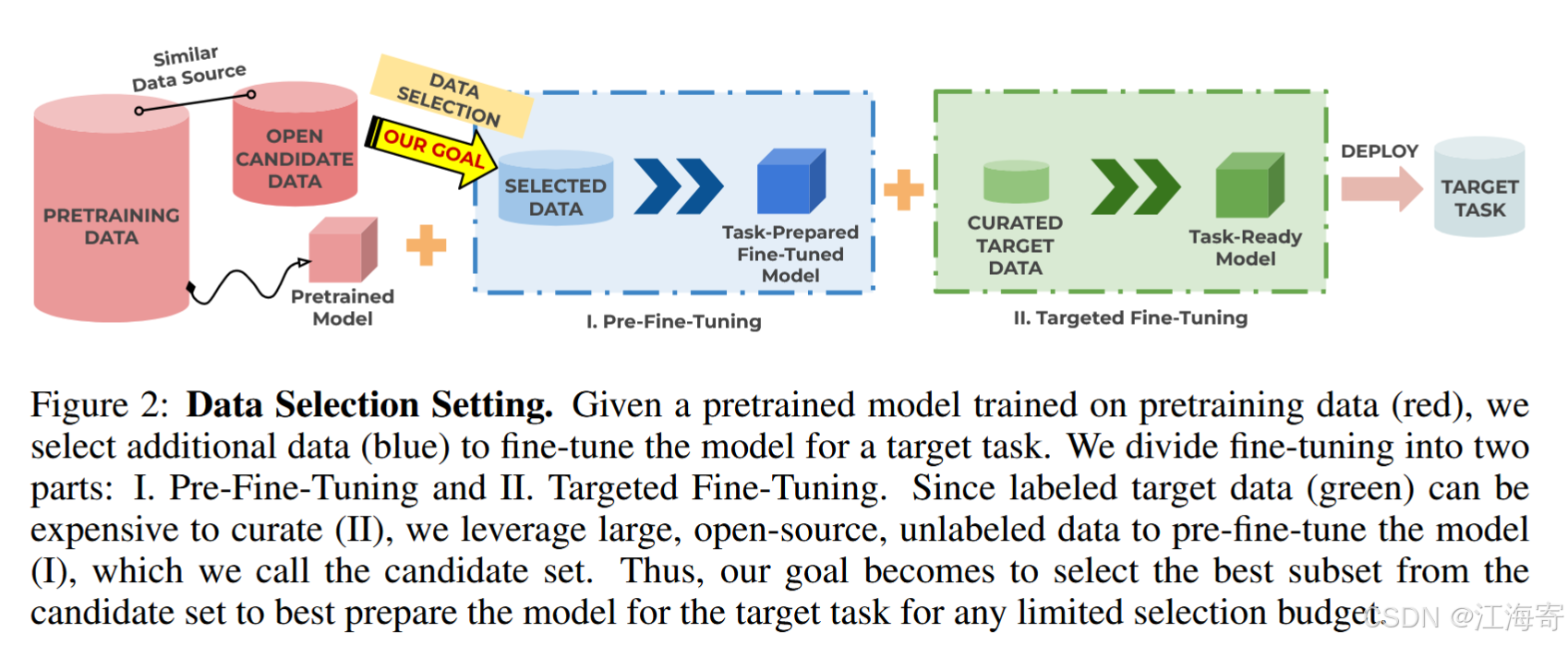
给定一个基于预训练数据训练的预训练模型(红色),我们选择其他数据(蓝色)来为目标任务微调模型。我们将微调分为两部分:I. 预微调和 II.有针对性的微调。由于标记的目标数据 (绿色) 的管理成本可能很高 (II),因此我们利用大型开源、未标记的数据来预先微调模型 (I),我们称之为候选集。因此,我们的目标是从候选集中选择最佳子集,以便为任何有限的选择预算的目标任务准备模型
好的!我将从论文的摘要部分开始,逐段翻译成计算机领域的中文。以下是论文开头部分的翻译:
摘要(ABSTRACT)
这项工作主要关注如何从庞大的未标注开放数据中进行选择,以对预训练语言模型进行预微调(pre-fine-tuning)。目标是减少在后续微调中对高成本领域特定数据的需求,同时实现预期的性能水平。尽管许多数据选择算法已经被设计用于小规模应用,但它们并不适合我们面临的大规模语言数据问题。然而,部分新兴方法开始能够处理语言数据的规模,但它们通常优先选择与目标分布一致的数据。尽管这种策略在从头训练模型时可能有效,但当模型已经在不同的分布上预训练过时,这种方法可能效果有限。与之前的工作不同,我们的核心思路是选择那些能够推动预训练分布更接近目标分布的数据。我们证明了在某些条件下,该方法在微调任务中的最优性。我们通过多种任务(自然语言理解、自然语言生成、零样本任务)验证了我们方法的有效性,模型规模高达2.7B,结果表明我们的方法在性能上持续优于其他选择方法。此外,我们提出的方法比现有技术更快,仅需一小时单GPU即可处理数百万样本。我们已将代码开源。尽管微调在提升模型性能方面潜力巨大,但其相关成本往往限制了其广泛应用;通过这项工作,我们希望为低成本的微调奠定基础,使其益处更加广泛。
1. 引言(INTRODUCTION)
大型预训练语言模型(LLMs) 已成为广泛应用于各类AI任务中的核心技术(Devlin et al., 2018b;Touvron et al., 2023;Wang et al., 2022b)。通常,要将这些模型适应具体应用,需要进一步进行微调。在这个过程中,一个持续的挑战是不断出现的新任务,这些任务的标注数据往往较为稀缺。例如,GPT模型在安全性相关的问题上引起了广泛关注(Wang et al., 2023;2022a),这些问题需要及时且集中的干预措施。尽管专家标注的安全性数据集是理想的解决方案,但获取这些数据集的过程既昂贵又耗时。
一种切实可行的替代方案,如图2所示,是从大量开放的未标注数据中提取相关样本,并在这些样本上对预训练模型进行微调。我们将这一步称为预微调(pre-fine-tuning)。然后,经过预微调的模型会进一步基于任何现有的任务特定标注数据进行微调,这称为目标微调(targeted fine-tuning)。这种两阶段微调方法旨在充分利用来自庞大未标注数据集中的相关样本(如图1所示)。在本文中,我们深入研究了LLM的这种两阶段微调方法。我们的目标是设计一个策略,在预微调阶段选择样本,以确保预微调后的模型能为目标微调做好最佳准备。
好的,我将继续进行翻译,以下是论文的后续部分:
2. 方法(METHODS)
2.1 数据选择的挑战
尽管在数据选择方面已有大量文献(Ghorbani & Zou, 2019;Mirzasoleiman et al., 2020;Borsos et al., 2020),但许多现有技术仅适用于小规模数据集,因为这些方法通常依赖于重新训练模型并反向传播梯度。近期研究(Xie et al., 2023)开始探索大规模语言数据的数据选择。然而,这些研究的核心在于选择样本,这些样本专门与目标分布相匹配。然而,这种思路忽略了预训练分布:所选样本仍可能包括在预训练数据中已得到良好表示的样本,而这些样本对微调贡献不大,导致数据效率普遍不佳。实际上,在低选择预算情况下,现有方法在目标任务性能上的提升往往是微不足道的。我们在附录A中对相关工作进行了扩展讨论。
我们总结了与预微调的数据选择相关的挑战,如下所示:
- 任务有效性(G1):所选择的数据应有效提升目标任务性能。
- 数据效率(G2):预微调应在有限选择预算内提高性能,因为微调LLMs的费用通常随样本数量的增加而增加。例如,微调175B参数的GPT-3模型以完成文本生成任务,在小规模(100K短样本,最大长度128个标记)上进行微调,根据OpenAI API的建议设置,费用约为$1500。
- 可扩展性(G3):数据选择方法应能扩展到开放语言数据集的规模,并能够在有限的计算资源下完成。
- 通用性(G4):数据选择方案应适用于多种使用场景,而不需要大量修改,并能提供一致的性能提升。
2.2 GOT-D方法概述
为了解决上述挑战,我们引入了GOT-D(Gradients of Optimal Transport for Data Selection),这是一种针对预微调量身定制的可扩展数据选择策略。我们的核心思路是优先选择那些最有效地将预训练分布向目标数据分布拉近的样本。直观而言,使用这些样本对预训练模型进行微调将提升其在目标数据集上的表现。我们在某些假设条件下证明了这一直觉的有效性,从而为我们的方法奠定了坚实的理论基础。尽管确切的预训练数据集并不总是可访问的,但广泛认识到LLMs主要使用常见的开放来源进行预训练(Touvron et al., 2023;Liu et al., 2019b)。因此,我们可以利用这些来源来构建一个候选数据集,作为预训练分布的代理。
2.3 GOT-D的具体步骤
GOT-D方法包括以下几个关键步骤:
构建候选数据集(Candidate Dataset):根据已知的开放数据源,构建一个未标注的候选数据集,以近似预训练数据分布。
计算最优传输距离(Optimal Transport Distance):使用最优传输理论计算候选数据集和目标数据之间的距离,识别数据分布的差异。
选择样本:优先选择那些能够有效降低最优传输距离的样本。这一过程通过计算目标任务的梯度信息来确定,从而保证选择的样本能够最大程度地推向目标任务的数据分布。
预微调(Pre-fine-tuning):使用选定的样本对预训练模型进行预微调,使模型适应目标任务的分布。
目标微调(Targeted Fine-tuning):在预微调后,利用少量标注数据对模型进行目标微调,以提高其在特定任务上的表现。
2.4 理论支持与实验验证
我们在论文中提供了理论证明,表明在特定条件下,GOT-D方法在任务微调中的有效性。此外,通过多种实际任务(如自然语言理解、生成等)进行实验验证,结果显示我们的方法在性能上优于现有的数据选择策略,并且能够高效处理大规模数据集。
3. 实验(EXPERIMENTS)
3.1 实验设置
在本节中,我们通过实验证明我们提出的方法在实际应用中的有效性。我们包括了三个不同的用例,以验证所提方法的实用性和潜力:针对模型去毒(detoxification)的自然语言生成任务(第3.1节)、8个具有预定义领域的自然语言理解任务(第3.2节),以及8个没有预定义领域的通用自然语言理解任务(GLUE基准,Wang et al., 2018)(第3.3节)。这些用例具有代表性,涵盖了多样的下游场景。我们将实验设置、基线和运行时间分析的详细信息推迟到附录中。
3.2 模型去毒
LLMs被发现容易生成有毒的输出,包括粗鲁、不尊重或明显的内容(McGuffie & Newhouse, 2020;Gehman et al., 2020;Wallace et al., 2019;Liang et al., 2022)。鉴于这些问题,近年来减少模型输出的毒性水平受到了越来越多的关注(Wang et al., 2022a;2023)。基于DAPT,Gehman et al. (2020) 提出通过在标注最低毒性分数的干净样本上微调模型来去毒。虽然这种方法有效,但需要大量专家精心制作的干净数据集,这限制了其适用性。给定少量标注的数据集,包括干净(正面)或有毒(负面)的示例,我们的方法可以从未标注的数据池中选择样本,以将模型推向正面示例或远离负面示例。
3.3 实验方法与基线
我们使用GPT-2(基础模型,124M参数)作为我们的基础模型。我们考虑了五种方法:GOT-Dclean(我们的方法)、GOT-Dcontrast(我们的方法)、RTP、DSIR和随机选择。RTP(Gehman et al., 2020)使用Perspective API评估每个样本的毒性分数,并选择那些毒性分数最低的样本。对于GOT-Dclean(我们的方法)和DSIR,使用2.5K毒性分数≤0.1的干净样本作为目标进行选择;对于GOT-Dcontrast(我们的方法),使用2.5K毒性分数≥0.5的有毒样本作为负面目标进行选择。候选数据集来自OpenWebTextCorpus(OWTC),与GPT-2的预训练领域相同。候选数据完全与用于评估的提示数据集分开。我们在10K和20K的样本上进行数据选择,然后使用学习率为2e-5对基础GPT-2模型进行3个epoch的微调。
好的,下面是论文的后续部分翻译:
4. 结果(RESULTS)
4.1 毒性评估结果
我们在使用Perspective API进行的毒性评估中获得的结果如表1所示。与原始的GPT-2模型相比,我们提出的数据选择方法显著降低了毒性水平。特别是在20K子集中,我们的方法分别对有毒提示和非有毒提示的最坏情况毒性降低了0.21和0.12。我们还观察到,有毒提示的毒性概率从0.67降至0.21,非有毒提示的毒性概率从0.25降至0.07。值得注意的是,GPT-2的预训练是在40GB的文本语料库上进行的(Radford et al., 2019)。因此,仅使用一小部分(20K)经过精心挑选的子集便能实现显著的毒性降低,显示了我们提出的数据选择方法的有效性。这种显著的降低并未被RTP、DSIR或随机选择所匹敌。需要指出的是,在实现这些毒性降低的同时,模型在下游任务上的平均准确率仅有小幅下降,从0.422降至0.408。我们的方法在Moderation API评估下也表现出最佳性能,进一步突显了我们方法的稳健性。由于篇幅限制,Moderation API的结果我们在附录中的表6中进行了展示,同时关于这两个API的更多信息和讨论也在C.4和D.1部分中提供。
| 方法 | 最大毒性(↓) | 毒性概率(↓) | OWTC 实用性 | PPL(↓) | 平均准确率(↑) |
|---|---|---|---|---|---|
| 10K子集 | |||||
| GOT-Dclean(我们的方法) | 0.45 ↓0.17 | 0.28 ↓0.10 | 0.36 ↓0.31 | 0.09 ↓0.16 | 41.0 ↓1.2 |
| GOT-Dcontrast(我们的方法) | 0.47 ↓0.15 | 0.29 ↓0.09 | 0.39 ↓0.28 | 0.11 ↓0.14 | 42.0 ↓0.2 |
| RTP | 0.52 ↓0.10 | 0.35 ↓0.03 | 0.49 ↓0.18 | 0.16 ↓0.09 | 40.9 ↓1.3 |
| DSIR | 0.60 ↓0.02 | 0.38 ↓0.00 | 0.64 ↓0.03 | 0.23 ↓0.02 | 41.7 ↓0.5 |
| 随机选择 | 0.57 ↓0.05 | 0.37 ↓0.01 | 0.60 ↓0.07 | 0.21 ↓0.04 | 42.5 ↑0.3 |
| 20K子集 | |||||
| GOT-Dclean(我们的方法) | 0.41 ↓0.21 | 0.26 ↓0.12 | 0.28 ↓0.39 | 0.09 ↓0.16 | 40.8 ↓1.4 |
| GOT-Dcontrast(我们的方法) | 0.46 ↓0.16 | 0.28 ↓0.10 | 0.39 ↓0.28 | 0.10 ↓0.15 | 42.6 ↑0.4 |
| RTP | 0.50 ↓0.12 | 0.33 ↓0.05 | 0.44 ↓0.23 | 0.13 ↓0.12 | 41.3 ↓0.9 |
| DSIR | 0.60 ↓0.02 | 0.38 ↓0.00 | 0.63 ↓0.04 | 0.23 ↓0.02 | 41.1 ↓0.1 |
| 随机选择 | 0.57 ↓0.05 | 0.36 ↓0.02 | 0.58 ↓0.09 | 0.20 ↓0.05 | 42.9 ↑0.7 |
| 基础模型(GPT-2) | 0.62 | 0.38 | 0.67 | 34.2 | 42.2 |
4.2 领域特定任务适应
在这一部分,我们实施了GOT-D以选择数据,为给定的LLM在8个领域特定任务上进行预微调。我们评估数据选择方法在下游任务性能上的有效性,并考虑固定的选择预算。尽管先前的工作(Brown et al., 2020)表明,在领域数据集上进行广泛的继续预训练可以显著提升性能,但我们表明,如果选择得当,使用有限的数据预算进行预微调同样可以提升这些任务的性能。
实验设置:该实验涉及两个阶段:首先在所选数据上进行预训练,然后在下游任务上微调和评估。我们选择数据以在标注的目标训练集上微调预训练的bert-base-uncased模型。我们考虑了两种设置:
- 我们应用基线和GOT-D,以150K样本的固定选择预算从附录C.1中定义的语料库中进行选择。
- 我们模拟一个资源更为受限的场景,其中选择预算限制为50K,且下游训练数据集的大小限制为5K标注样本。所有MLM在其选择的数据上进行1个epoch的训练。
我们将8个标注数据集分为4个领域进行下游任务评估,包括生物医学(RCT (Dernoncourt & Lee, 2017)、ChemProt (Kringelum et al., 2016))、计算机科学论文(ACL-ARC (Jurgens et al., 2018)、Sci-ERC (Luan et al., 2018))、新闻(HyperPartisan (Kiesel et al., 2019)、AGNews (Zhang et al., 2015))、评论(Helpfulness (McAuley et al., 2015)、IMDB (Maas et al., 2011)),这些数据集由Gururangan et al. (2020)整理。除了ChemProt和RCT使用微观F1分数外,其他数据集的评估指标为宏观F1分数。有关详细的实验设置和超参数选择,请参见附录C.5。
| 方法 | RCT | ChemProt | ACL-ARC | Sci-ERC | HyperPartisan | AGNews | Helpfulness | IMDB | 平均值 |
|---|---|---|---|---|---|---|---|---|---|
| BERT (基础模型) | 86.87 | 70.09 | 79.33 | 66.18 | 90.47 | 93.42 | 68.78 | 93.78 | 82.70 |
| 所有领域 | 86.97 | 80.24 | 69.44 | 80.23 | 90.35 | 93.45 | 69.16 | 92.71 | 82.81 |
| DAPT | 87.14 | 81.03 | 70.51 | 80.97 | 89.57 | 93.66 | 68.15 | 93.89 | 83.11 |
| DSIR | 87.04 | 80.69 | 70.32 | 80.21 | 90.05 | 93.48 | 68.33 | 93.79 | 82.98 |
| GOT-D (我们的方法) | 87.21 | 81.97 | 72.34 | 81.99 | 90.69 | 93.72 | 68.96 | 93.81 | 83.83 |
4.3 没有预定义领域的任务适应
LLMs表现出了解决多种复杂任务的强大能力(Ge et al., 2023;Bubeck et al., 2023)。为了测量这种能力,标准化基准——通用语言理解评估(GLUE)(Wang et al., 2018)被引入,用于测试模型在多个困难数据集上的自然语言理解能力。我们应用这个基准评估我们在所选数据上微调的BERT模型的改进效果。
实验设置:我们的任务是选择数据以微调bert-base模型(提供在Huggingface上)。接下来,我们在每个GLUE任务上进一步微调模型。对于每个任务,我们在每个任务的测试集
上测量准确性,除了CoLA数据集外,我们报告马修斯相关系数。结果是在三个随机种子下平均的,并以标准差的形式呈现。
在这里,我们介绍两种数据选择设置,预算为50K。首先,在通过掩蔽语言建模(MLM)微调选定数据后,我们对每个GLUE任务进行了进一步微调,使用最多5K的训练数据(表4(下半部分));其次,在通过MLM微调所选数据后,我们对每个GLUE任务进行了进一步微调,使用所有训练数据(表4(上半部分))。我们将我们的方法与基线方法进行比较:BERT(基础模型),在没有未标注数据的情况下直接对任务进行微调,DSIR和TAPT/c。
| 方法 | CoLA | MNLI | MRPC | QQP | RTE | SST-2 | STS-B | QNLI | 平均值 |
|---|---|---|---|---|---|---|---|---|---|
| BERT (基础模型) | 54.94 | 84.33 | 81.37 | 90.72 | 76.17 | 92.77 | 87.42 | 91.39 | 82.39 |
| DSIR | 56.15 | 84.38 | 86.51 | 90.76 | 76.29 | 92.58 | 87.90 | 91.44 | 83.25 |
| TAPT/c | 56.49 | 84.34 | 85.29 | 90.76 | 76.89 | 92.43 | 87.86 | 91.52 | 83.18 |
| GOT-D(我们的方法) | 57.01 | 84.40 | 85.29 | 90.89 | 77.97 | 92.54 | 87.97 | 91.45 | 83.43 |
结果分析
从表4可以看出,在两种设置中,我们的方法在平均性能上始终优于其他数据选择方法,并且相较于基础的BERT模型提升了1.04%和3.13%。这表明,无论选择预算的情况如何,我们的方法不仅能超越基础模型的性能,还能在微调中显著提升GLUE得分。我们注意到,对于一些初始表现较低的任务(如CoLA和RTE),我们的方法能够获得更大的性能提升(CoLA提升约2%,RTE提升约18%)。由于其他任务在基础模型上表现较高,因此即便提供更多的微调数据,其提升空间有限。这种效果表明我们方法在选择过程中考虑了预训练数据的额外信息,使得数据选择更为精准,从而提高了下游任务的性能。
好的,接下来是论文的后续部分翻译,包括讨论、结论和致谢等内容。
5. 讨论(DISCUSSION)
在本研究中,我们提出了GOT-D方法,它为如何在预微调阶段选择有效数据提供了新的见解。我们的实验证明,使用未标注数据进行预微调能够显著提升微调模型在目标任务上的性能,尤其是在标注数据稀缺的情况下。GOT-D的成功在于其优先选择能有效将预训练分布推向目标任务分布的数据样本。
5.1 未来的研究方向
尽管我们的工作在使用未标注数据进行预微调方面取得了成功,但仍然有几个未来研究的方向可以进一步探索:
- 动态选择机制:开发更灵活的动态数据选择机制,以便在不同任务和数据集上不断优化选择策略。
- 其他应用领域:将GOT-D方法应用于不同的领域,如计算机视觉和强化学习,以验证其通用性和有效性。
- 多模态学习:探索GOT-D在多模态学习中的潜力,特别是在同时处理文本、图像和音频数据时。
6. 结论(CONCLUSION)
我们引入了预微调作为一种新的方法,利用开放的未标注数据来改善任务适应性能。我们强调了传统数据选择方法在预微调背景下的局限性,并提出了GOT-D,这一有效地将预训练分布向目标分布推移的方法。我们的实验结果显示,该方法在多种任务上都表现出色,并且其速度和可扩展性使得它能够快速处理数百万样本。我们相信,这项工作为低成本的高效微调奠定了基础,使得这一技术的优势更加广泛地被应用。
思考一:这篇文章提出的预微调和data selection之间的关系什么?
1.预微调的目的
利用大量的未标注开放数据来为后续的目标微调做准备。通过预微调,模型能够更好的适应目标任务的分布,从而提升其性能。
2.数据选择的关键性
在预微调的过程中,数据选择起着至关重要的作用。有效的数据选择能够确保从未标注的数据集中挑选出对微调最有价值的样本。具体而言,作者体现出的GOT-D方法通过计算预训练分布与目标数据分布之间的最优传输距离,优先选择拿些能够有效地将预训练分布向目标任务靠拢的样本。
总结
总的来说,预微调是一个利用未标注数据增强模型能力的过程,而数据选择则是确保这一过程有效性的关键环节。二者相辅相成,旨在提高模型在特定任务上的性能,降低对标注数据的依赖。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









