




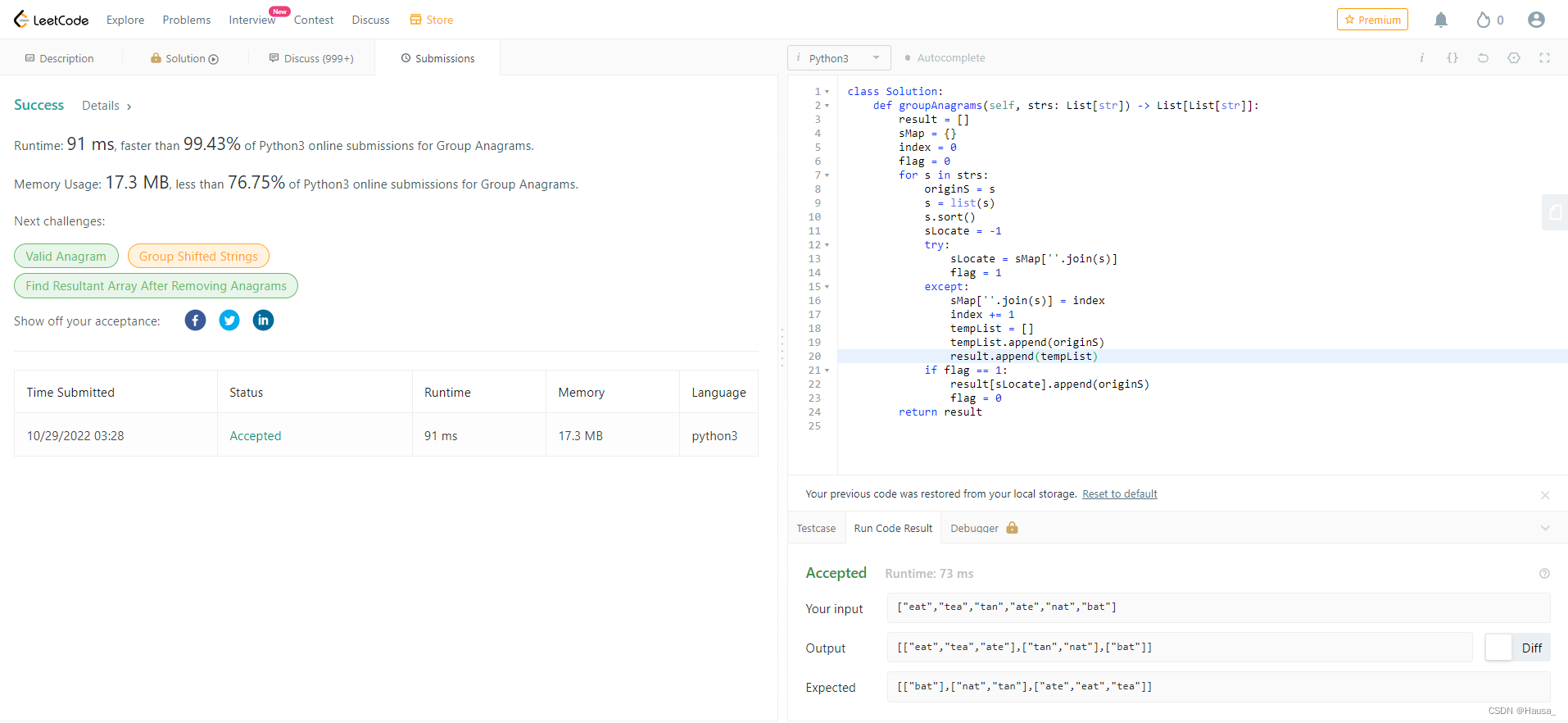
Runtime: 99.43%
Memory: 76.75%
没有关键词,乱做
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
result = []
sMap = {}
index = 0
flag = 0
for s in strs:
originS = s
s = list(s)
s.sort()
sLocate = -1
try:
sLocate = sMap[''.join(s)]
flag = 1
except:
sMap[''.join(s)] = index
index += 1
tempList = []
tempList.append(originS)
result.append(tempList)
if flag == 1:
result[sLocate].append(originS)
flag = 0
return result
具体思路是遍历每一个字符串,每次遍历将其所有字符排序,看看map里有没有,若没有:将该排序后的字符串作为键放入map里,值是index,然后往result里append一个列表。若有,就读取index,直接往result里面append。
try里面的第一行是取排序后字符串在map里的位置,如果没有这个键值就会报错,就走不到flag=1。
有没有读者知道方便的方法可以判断map里有没有该键值,请在评论区推荐一下。


















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









