







pandas,即Python数据分析库(Python data analysis library)
DataFrame和Series
DataFrame(数据帧)和Series(序列)是pandas的核心数据结构。DataFrame的主要组件包含索引、列、数据。DataFrame和二维的Numpy数组类似,但是它的行和列有对应的标签,并且每一列都可以存储不同类型的数据。从DataFrame中提取一行或一列时,会得到一个一维的Series。Series相当于带标签的一维Numpy数组。
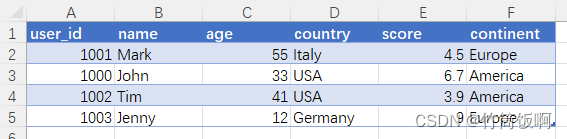
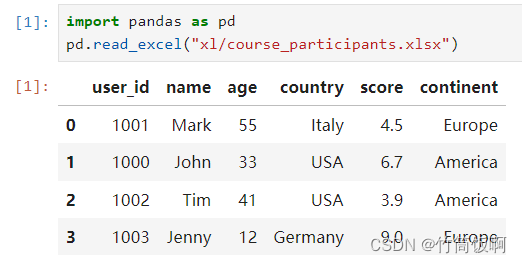
读取Excel为DataFrame格式,首先导入pandas,然后使用read_excel函数通过Excel文件构造一个DataFrame。
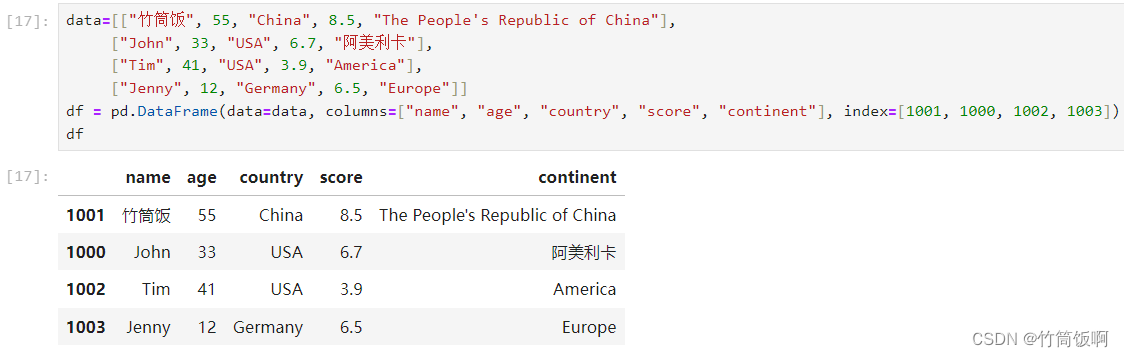
不读取Excel,从头创建一个DataFrame。创建DataFrame的方法之一是利用嵌套列表来提供数据,除了数据本身外,还需要提供columns参数和index参数。
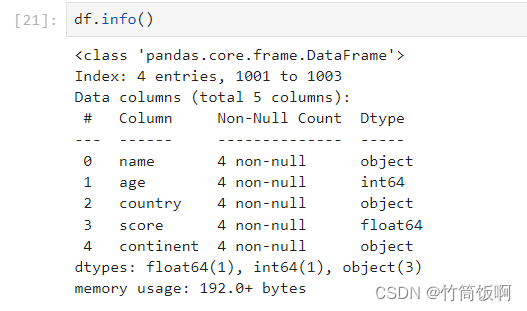
调用info方法可以获取DataFrame的一些基本信息,其中最重要的是数据点数量和每一列的数据类型:
索引
DataFrame的行标签被称为索引。如果找不到有意义的索引,构造DataFrame时可以直接省略,pandas会自动创建一个从0开始的整数索引。如下获取所有对象:

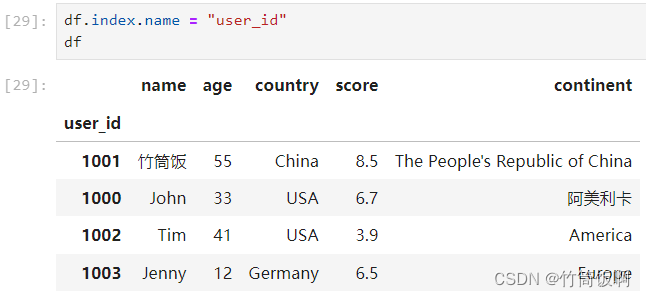
也可以给索引命名:
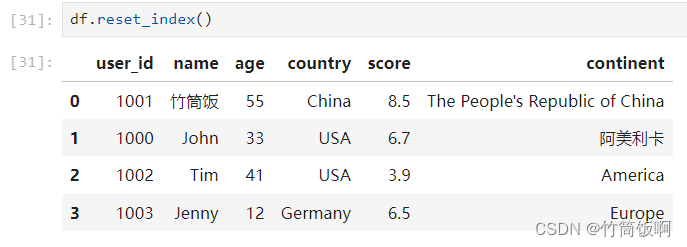
reset_index会将索引还原成普通索引,同时用默认用默认索引替换当前索引:
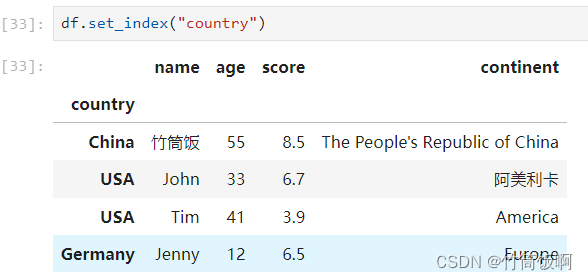
set_index可以将任意列设为索引:
DataFrame的方法返回的是副本: 每当df.method_name()的形式调用DataFrame时,都会得到一个应用了该方法的DataFrame副本,而原来的DataFrame没有发生任何变化。如果想要改变原来的DataFrame,可以把返回值赋值给原来的变量:
df = df.reset_index()用reindex方法更换索引:
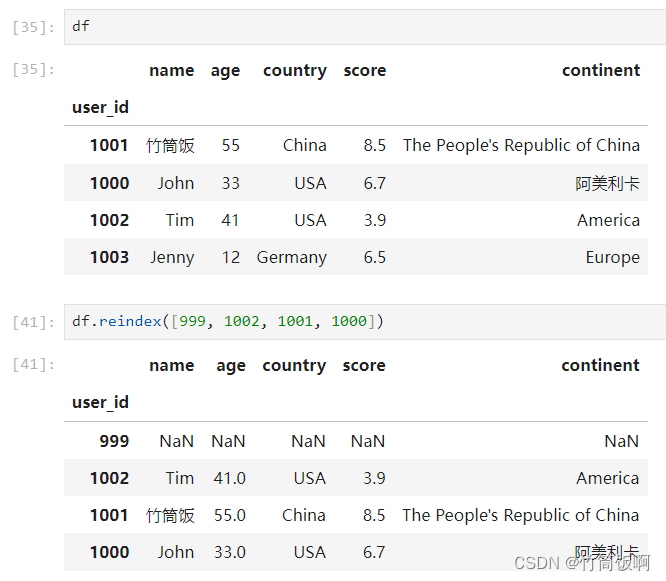
reindex会接管所有能够怕匹配新索引的行,而无法匹配的索引会引入空值(NaN)。被忽略的索引所对应的行会被直接丢弃。
sort_index可以按索引进行排序:
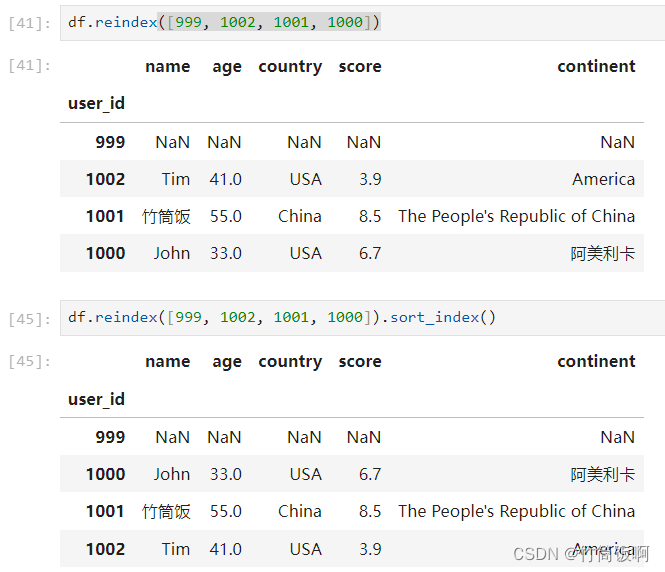
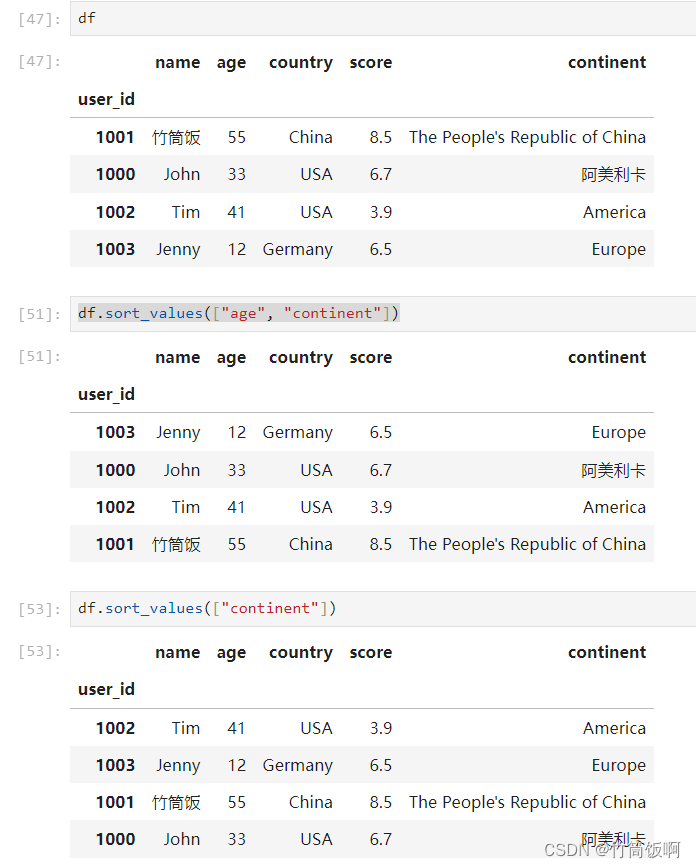
如果想按一列或多列排序,可以使用sort_values。按多列排序时会先按前面的列排序,排序后的结果依次按后面的列排序:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









