







数据倾斜的一种解决:
(1.重写Partitioner自定义分区)
package com.mr.day04;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.Random;
public class pr extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
Random random = new Random();
int i = random.nextInt(numPartitions);
return i;
}
}
(2.打撒为3个区每个区自己合并)
package com.mr.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Count {
public static class map01 extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] vsplit = value.toString().split(" ");
for (String val:vsplit)
context.write(new Text(val),new IntWritable(1));
}
}
public static class reduce01 extends Reducer<Text,IntWritable,Text,IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable unm: values){
int i = unm.get();
sum+=i;
}
context.write(key,new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS","hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(Count.class);
job.setMapperClass(map01.class);
job.setReducerClass(reduce01.class);
//调用自定义重写后的partitioner
job.setPartitionerClass(pr.class);
//分为3个区
job.setNumReduceTasks(3);
//指定map和reduce输出数据的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\上课\\hadoop\\2019.08.27-04MapReduce运行原理\\Test\\01-数据倾斜\\input01"));
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path("D:\\上课\\hadoop\\2019.08.27-04MapReduce运行原理\\Test\\01-数据倾斜\\output01");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
job.submit();
}
}
打撒后的3个文件结果图:
1
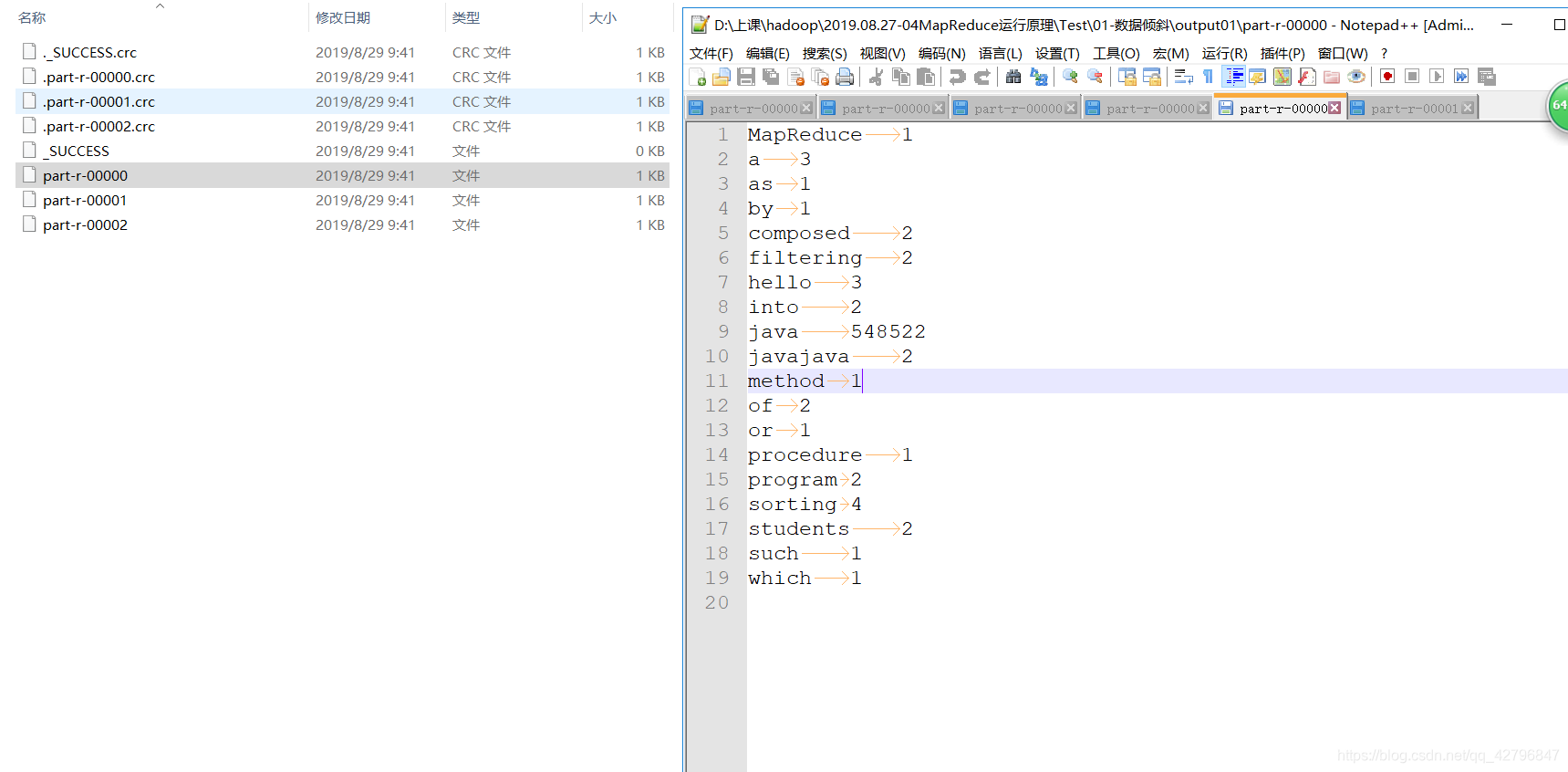
2
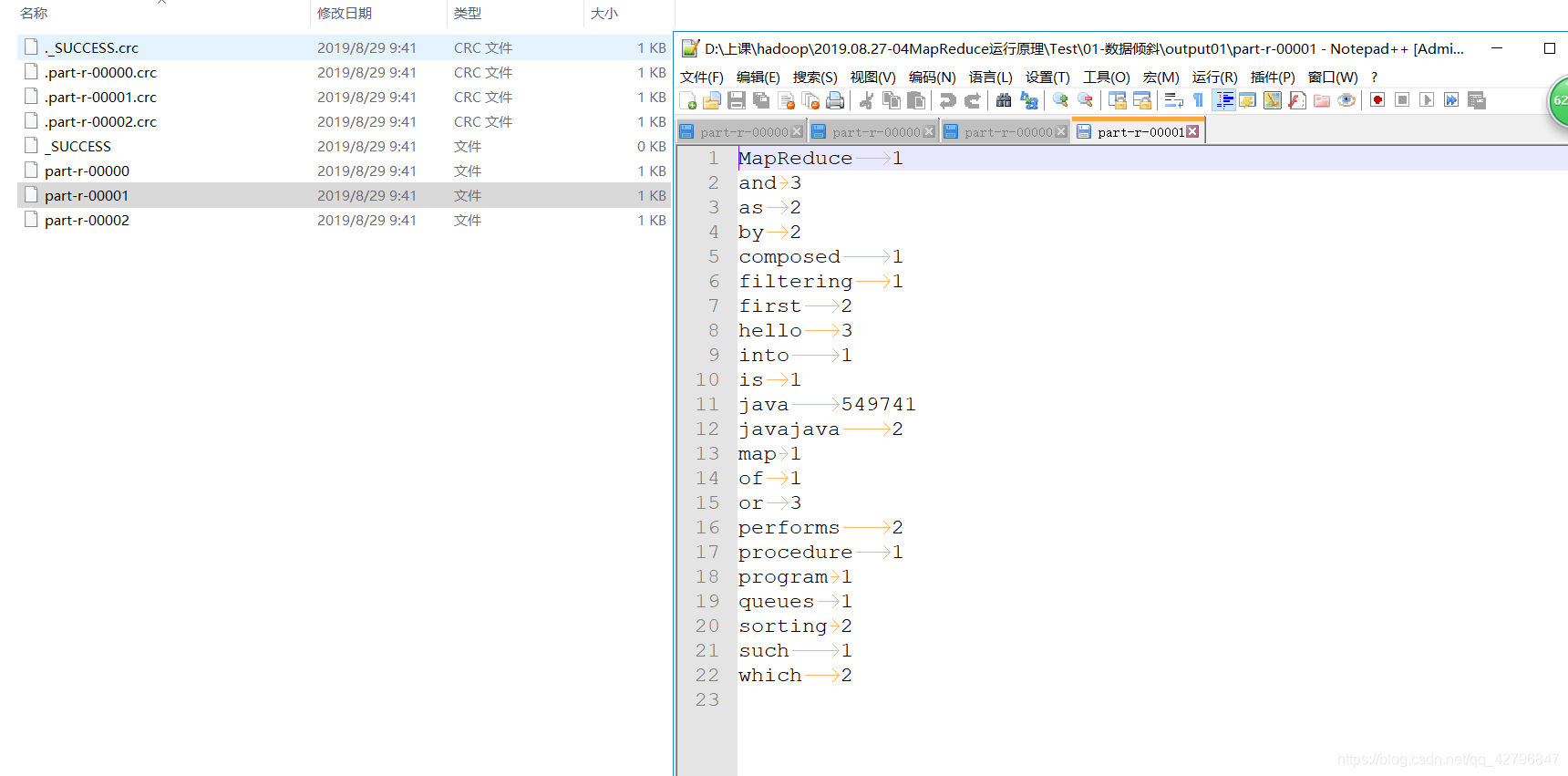
3
(3.得到后的结果合并)
package com.mr.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Count02 {
public static class map02 extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if(key.get()!=0){
String[] vsplit = value.toString().split("\t");
String name = vsplit[0];
String num = vsplit[1];
context.write(new Text(name), new IntWritable(Integer.valueOf(num)));
}
}
public static class reduce02 extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable unm : values) {
int i = unm.get();
sum += i;
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS","hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(Count02.class);
job.setMapperClass(map02.class);
job.setReducerClass(reduce02.class);
//指定map和reduce输出数据的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:\\上课\\hadoop\\2019.08.27-04MapReduce运行原理\\Test\\01-数据倾斜\\output01"));
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path("D:\\上课\\hadoop\\2019.08.27-04MapReduce运行原理\\Test\\01-数据倾斜\\output02");
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
job.submit();
}
}
}
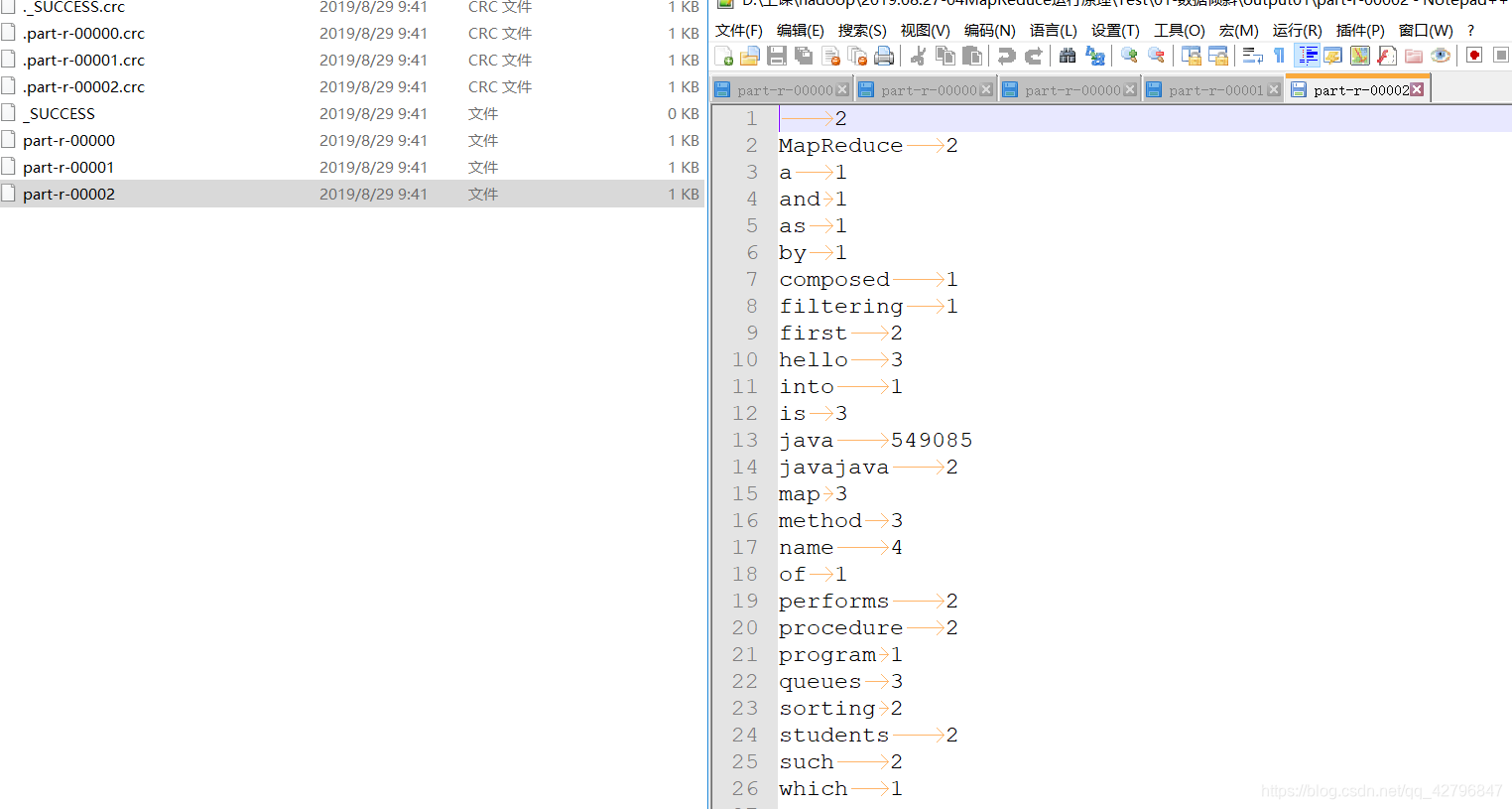
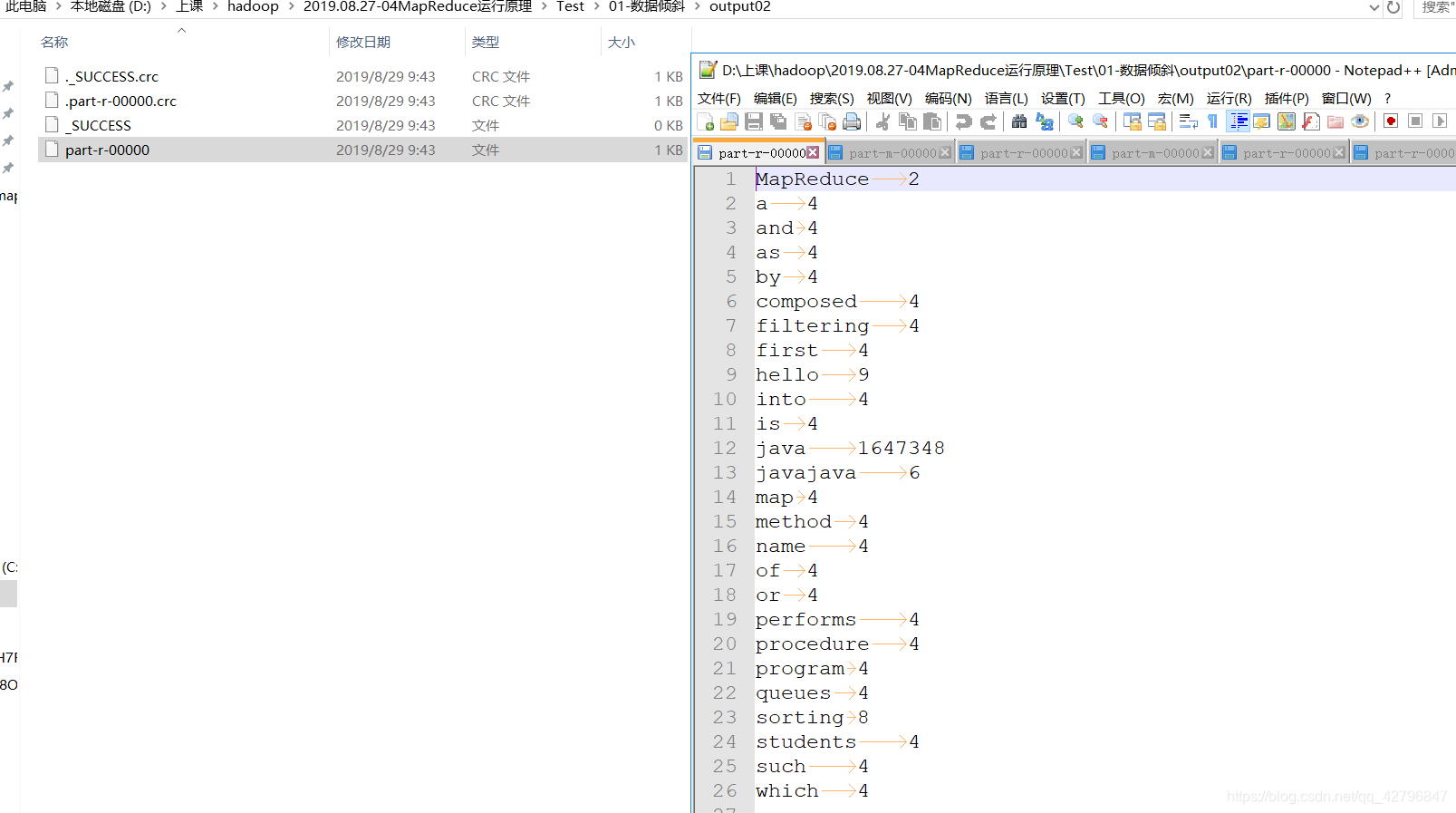
最后把3个文件合并后的最终结果图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









