









XML以及相关技术
为了实现实现的不同路径执行不同的资源,需要使用XML文件进行配置。而为了限定XML的内容,我们需要使用XML约束(DTD或schema)为了获得xml的内容,我们需要使用dom4j进行解析。
XML
Extensible Markup Language,可扩展标记语言。语法上和HTML相似,但HTML中的元素是固定的,而XML中的标签是可以由用户去自定义的。
常见的应用
配置文件
存放数据

XML语法
- XML文档声明
- 1.文档声明必须为<?xml 开头,以 ?> 结束
- 2.文档声明必须从文档的0行0列位置开始
- 3.文档声明只有两个属性:
- version:当前版本,只选1.0版(必选);
- encoding:指定当亲啊文档的编码。默认utf-8(可选);
-
元素element

-
属性

-
注释
XML的注释与HTML相同,即以"< !-- " 开始,以" – >"结束 -
转义字符
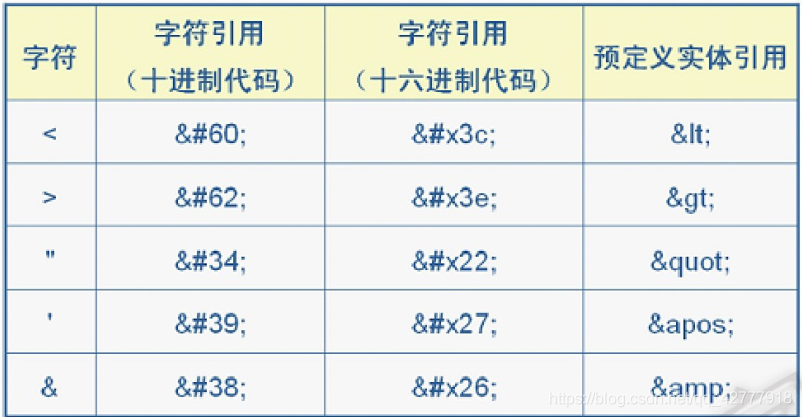
-
CDATA区
如果转义字符大量出现在xml文档中,会使xml文档的可读性大幅度降低,这时如果使用CDATA段就会更好一些。
在CDATA段中的<、>、‘、"、&等都无需使用转义字符。这可以提高xml文档的可读性
在CDATA段中不能包含]]>,即CDATA段的结束定界符。
DTD约束
常见的xml约束DTD和Schema
什么是DTD
DTD(Document Type Definition)文档类型定义,用来约束xml文档。规定xml文档中元素的名称、子元素的名称以及顺序,元素的属性等
DTD重点要求
开发中、很少自己编写文档。通常都是通过框架提供的DTD约束文档,编写对应的XML文档。常见的框架使用DTD约束有:struts2、hibernate等
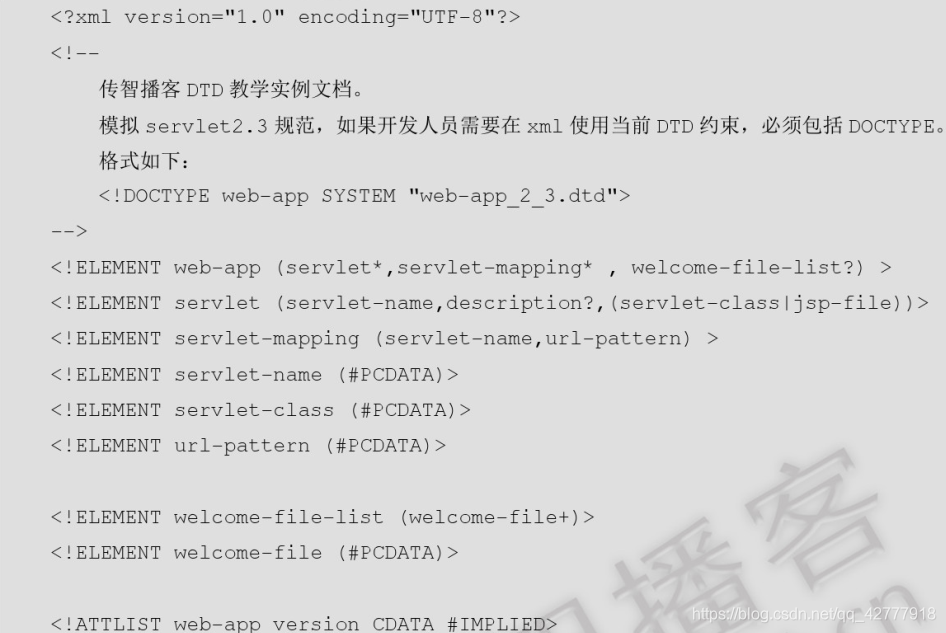
案例实现
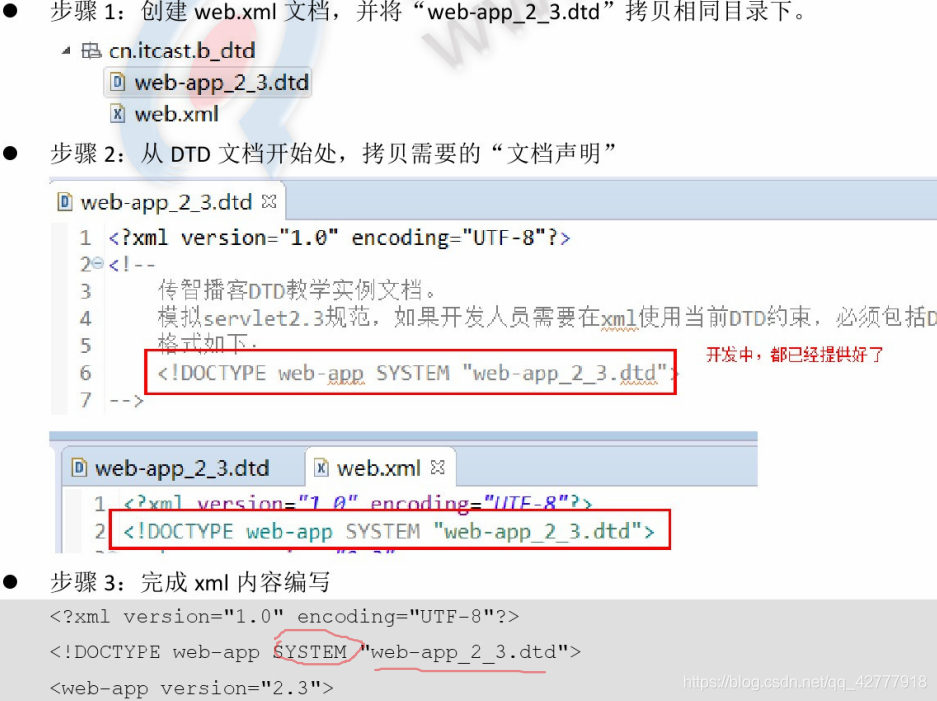
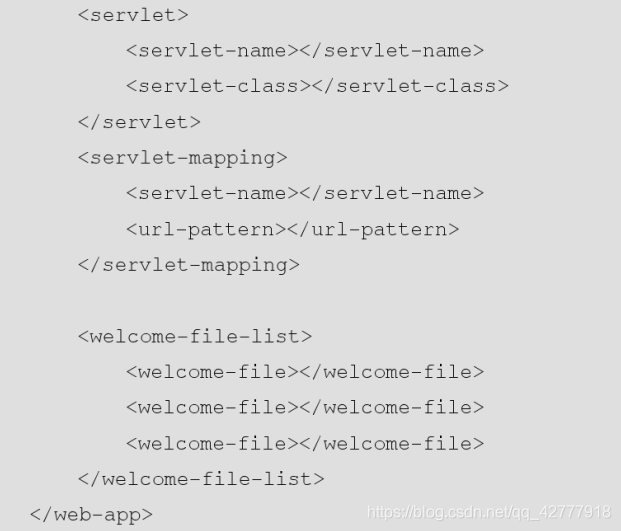
DTD语法(了解)
文档声明

元素声明
定义元素语法:<!ELEMENT 元素名 元素描述>
元素名:自定义
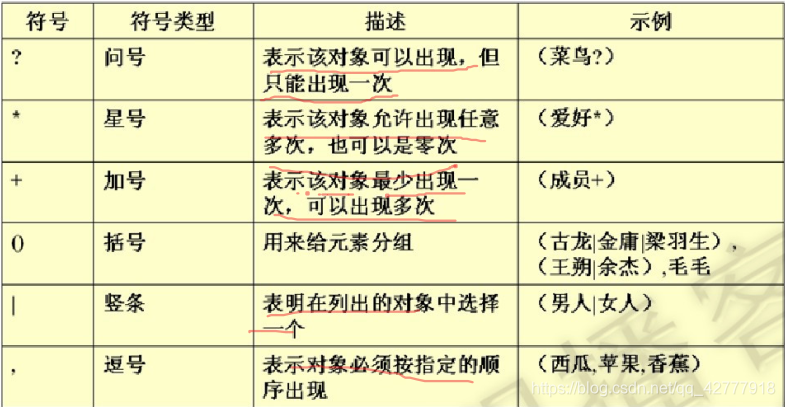
元素描述包括:符号和数据类型
常见符号:?* + () | ,
常见类型:#PCDATA表示内容是文本,不能是子标签
实例
<! ELEMENT web-app (servlet *,servlet-mapping*,welcome-file-list?)>
web-app 包括3个标签,且必须顺序出现
servlet-mapping 个数任意
servlet-mapping 个数任意
welcome-file-list 最多只能出现一次
<! ELEMENT servlet (servlet -name,description?,(servlet-class|jsp-file))>
servlet 有3个子标签,且必须顺序出现
servlet-name 有且只有一个
description 可选一次
servlet-class和jsp-file二选一,且只能出现一次
<! ELEMENT servlet-name (#PCDATA)>
servlet-name的标签必须是文本
<! ELEMENT welcome-file-list (welcome-file+)>
welcome-file-list 至少有一个子标签welcome-file
属性声明
属性的语法:(attribute)
<!ATTLIST 元素名
属性名 属性类型 约束
属性名 属性类型 约束
...
>
元素名:属性必须是给元素添加、所有必须先确定元素名
属性名:自定义
属性类型:ID、 CDATA、枚举...
ID:ID类型的属性用来标识元素的唯一性
CDATA:文本类型
枚举:(e1|e2|...)多选一
实例
<!ATTLIST web-app version CDATA #IMPLIFD>
给web-app添加version属性,属性值必须是文本,且可选。
<web-app version="2.3">和<web-app>都符合约束
Schema
新的XML约束文件,是DTD的替代者,扩展名是xsd而不是xml、dtd且支持名称空间。
Schema重点要求
与DTD一样,要求可以通过schema约束文档编写xml文档。
格式:
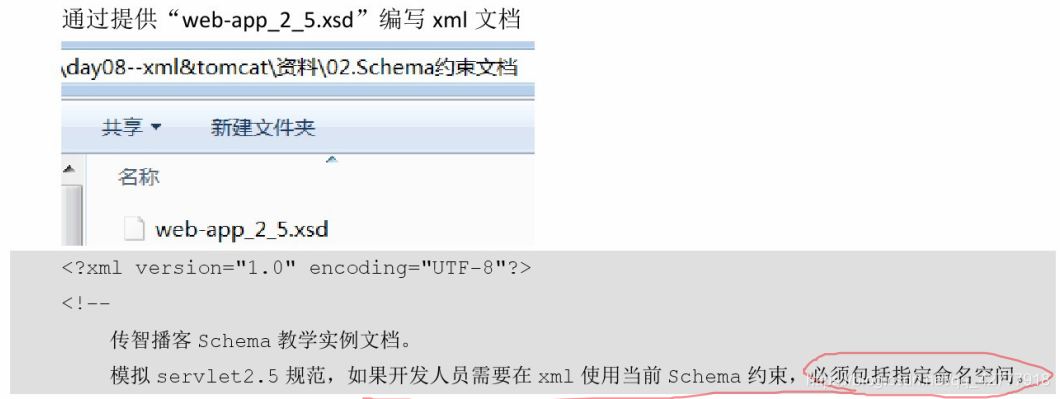


案例实现
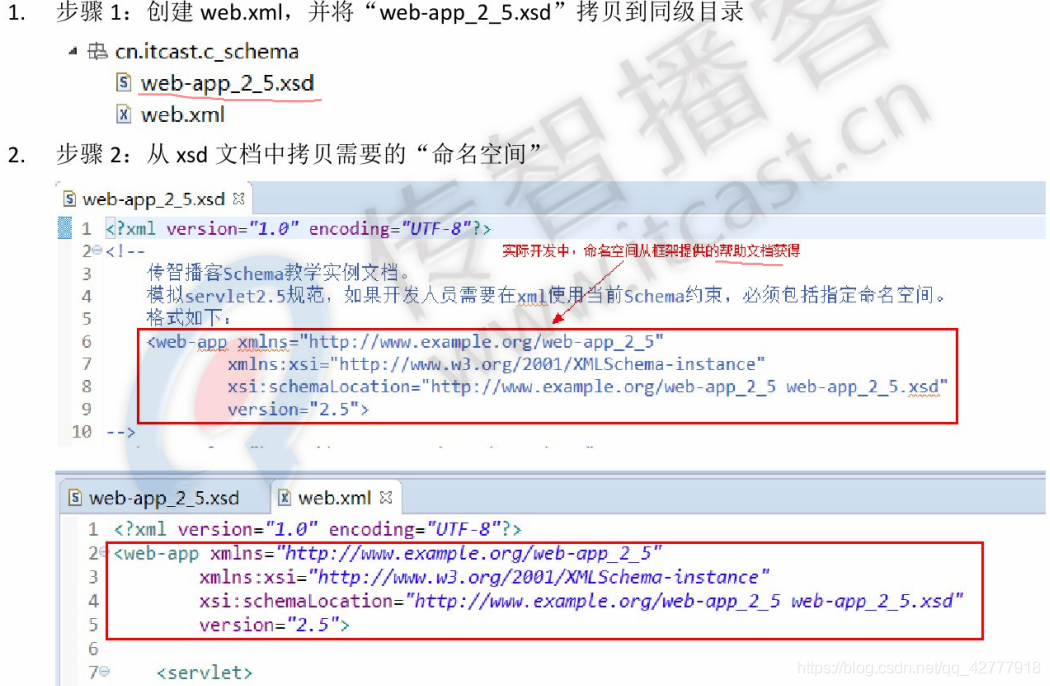

命名空间(语法)
什么是命名空间

约束文档和XML关系

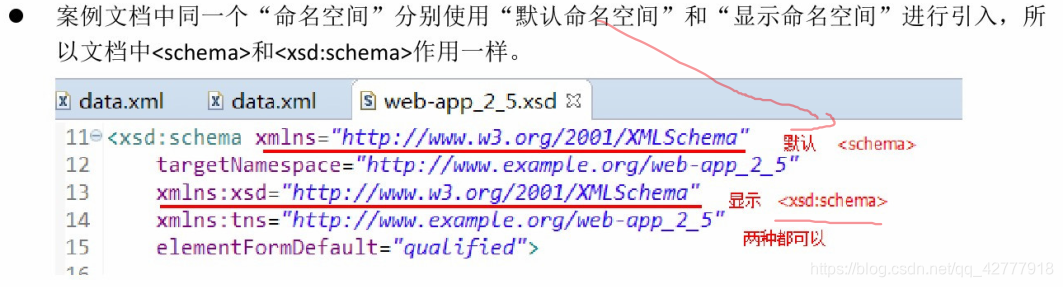
声明命名空间
- 默认命名空间:,使用<标签>
- 显示命名空间: <xxx xmlns:别名="">,使用<别名:标签>
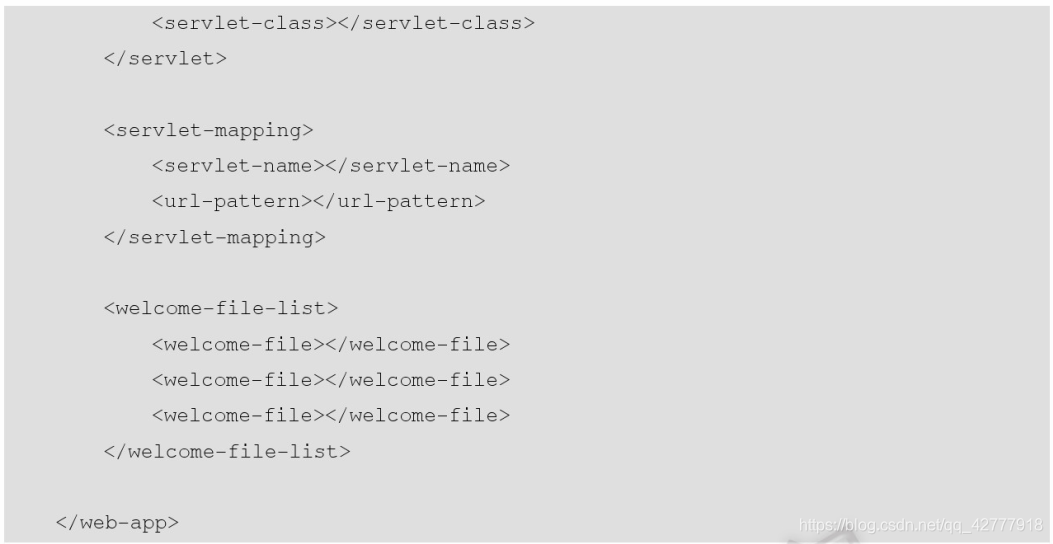
实例:web-app_2_5.xsd

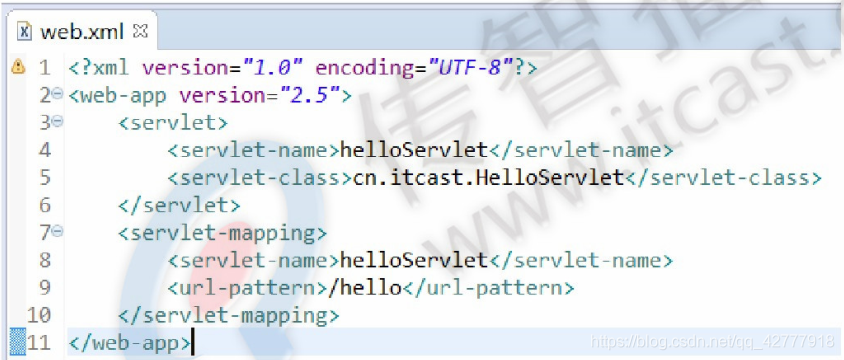
实例:web.xml

dom4j 解析
XML解析概述
为不同问题提供不同的解析方式,并提交对应的解析器,方便开发人员操作xml
解析方式和解析器
常见的解析方式
- DOM:要求解析器把整个XML文档装载到内存,并且解析成一个Documnt对象。
优点:元素与元素之间保留结构关系、所以可以进行增删改查操作。
缺点:XML文档过大,可能出现内存溢出显现 - SAX:是一种速度更快更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行都将触发对应的事件。
优点:处理速度快,可以处理大文件
缺点:只能读,逐行后将释放资源。
常见的解析器:

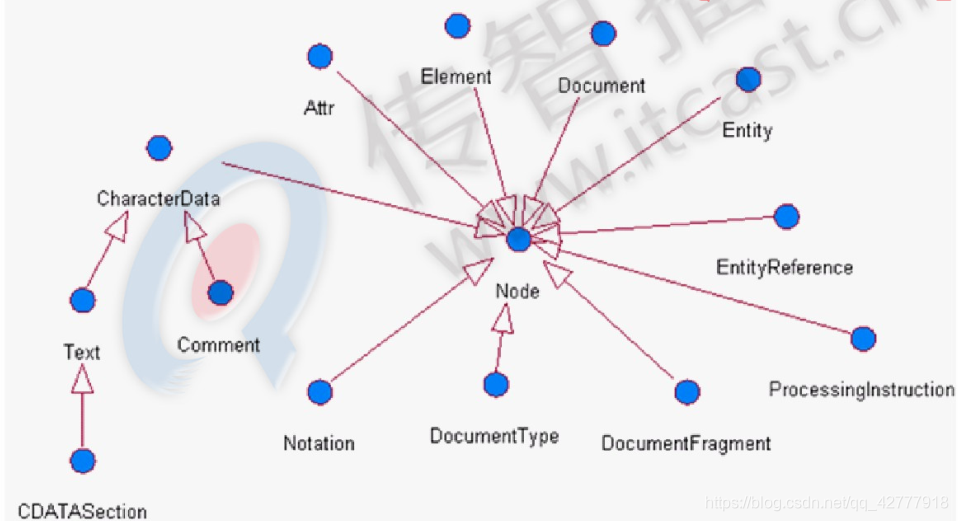
DOM解析原理及结构模型
XML DOM 和HTML DOM类似,XML DOM将整个XML文档加载到内存,生成DOM树,并获得一个Document对象,通过Document对象就可以对DOM进行操作。
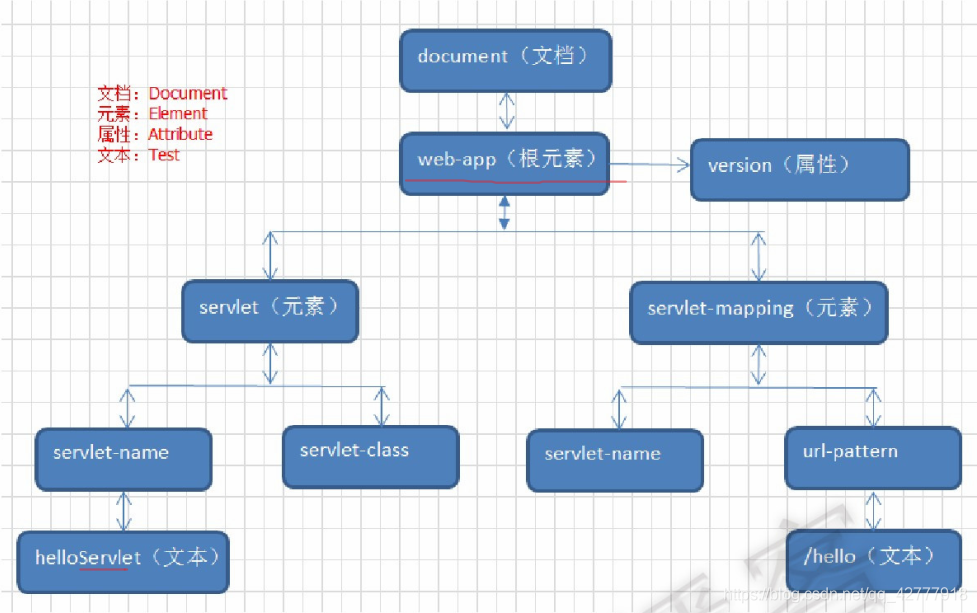
DOM中的核心概念就是节点,在XML文档中的元素、属性、文本等,在DOM中都是节点
API使用
要使用dom4j必须导入dom4j的jar包,dom4j必须使用核心类SaxReader加载xml文档获得Document,通过Document对象获得文档的根元素,然后就可以继续擦操作了,常用api如下:
- SaxReader对象
- read(…)加载执行xml文档
- Document对象
- getRootElement()获得根元素
- Element对象
- elements(…) 获得指定名称的所有子元素。可以不指定名称
- element(…)获得指定名称第一个元素 ,也可以不指定名称
- getName()获得当前元素的元素名
- attributeValue(…)获得指定属性名的属性值
- elementText(…)获得指定名称子元素的文本值
- getText(…)获得当前元素的文本内容
实例

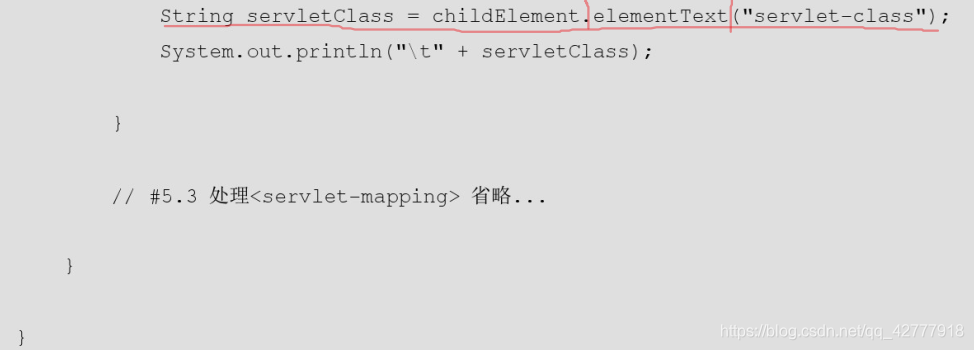
反射
为了实现后期程序的可扩展,以及不必把程序写死,开发中通常使用实现类的权限类名(cn.itcast.e_web.HelloMyServlet),通过反射加载字符串指定的类,并通过反射创建实例。
@Test
public void demo02() throws Exception{
/*反射创建执行
*1)Class.forName 返回指定接口或类的Class对象
* 2)newInstance() 通过Class对象创建类的实例对象,相当于new Xxx();
*/
//3.获得字符串实现类实例
Class clazz =Class.forName(servletClass);
Myservlet myServlet =(Myservlet) clazz.newInstance();
//4 执行对象的方法
myServlet.init();
myServlet.service();
myServlet.destory();'
}
解析xml
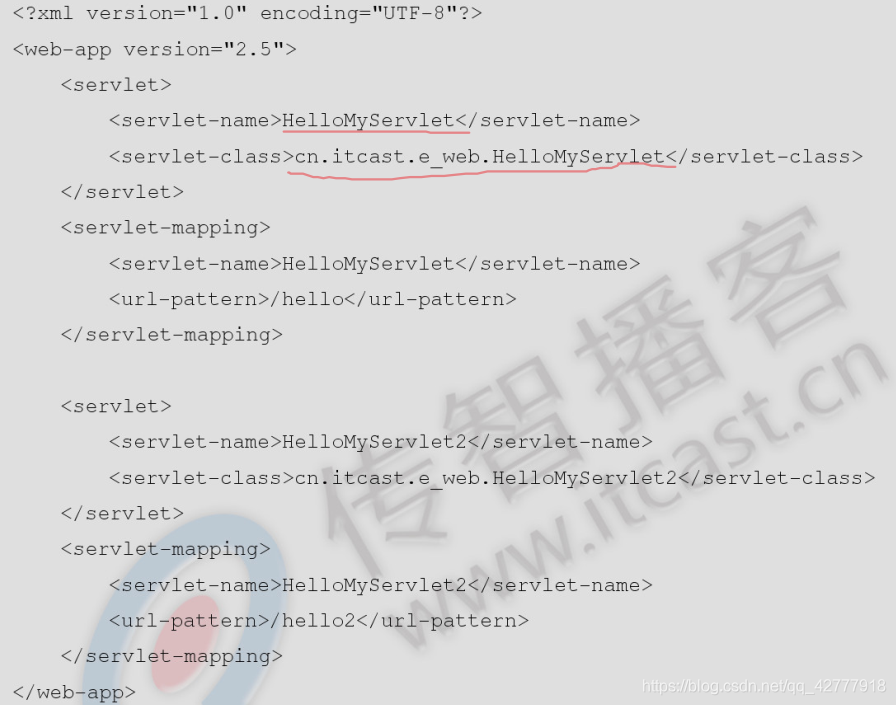
使用反射我们已经可以创建对象的实例,此时我们使用的全限定类名,在程序中仍是写死的,我们将其配置到xml文档中。
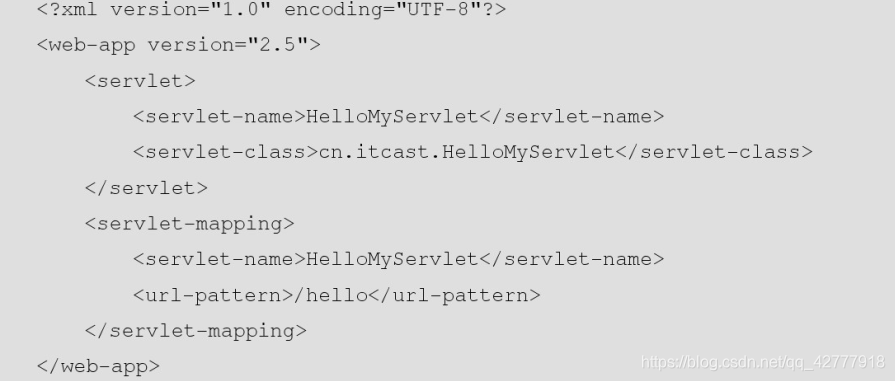
xml文档内容:
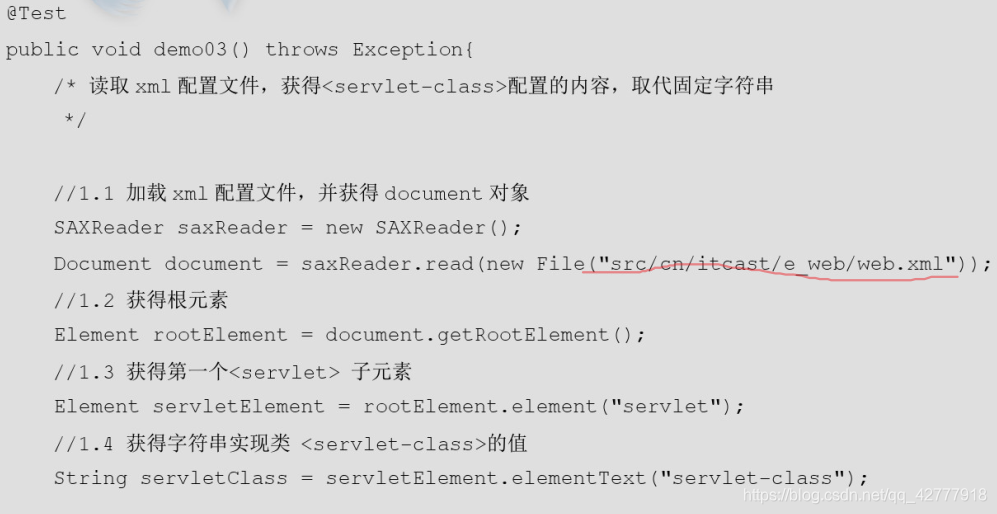
解析实现

模拟浏览器路径



















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









