






来自某中英文大学的小白学习笔记。。。
Report of 2D U-net paper
Title: U-NET: Convolutional Networks for Biomedical Image Segmentation
Author: Olaf Ronneberger, Philipp Fischer & Thomas Brox
Published: International Conference on Medical Image Computing and Computer-assisted Intervention, 2015
Introduction:
Most of the CNNs are typically used in classification tasks, while biomedical image processing requires localized output. Ciresan et al. attempted to train a network to do this task. However, its performance was not satisfactory.
Main modification:
In this paper, the researchers developed a “fully convolutional network” – U-net. The main idea is to add a upsampling layers after the pooling layers. Meanwhile, high resolution features from contracting path are provided to the upsampling layers to assemble precise outputs.
A crucial modification in the architecture is that plenty of feature channels allow the network to propagate context features to higher resolution outputs. Also, the network has no connected layers but convolutional layers, which makes the network compatible for different size of segmentation tasks.
To supplement the dataset, the researchers used some elastic deformation. Random elastic deformations are important variation among tissues and cells. Those deformations helped the network to learn the invariance of the images without large dataset.
In addition, a weighted loss is attached to the borders of touching objects of same class. The separation border is computed using morphological operations.
Architecture of the network:
The contracting path consists of repeated 3X3 convolutions with ReLU as well as 2X2 max pooling operations. In the expansive path, the researchers adapted 2X2 up-convolution operations and some 3X3 convolutions. Two paths together form a shape of “U”.
Training:
Paddings are not added to convolution operations. As a result, the output is smaller than input in size. To reduce the overhead and to make full use of GPU memory, the researchers chose large input tiles over a large batch size. Accordingly, they use a high momentum so that the previous seen training samples determine the current optimization.
*momentum: an acceleration technique of SGD. We add momentum term as a history information term, so the descent will be speed up if the last momentum has the same direction with the current descent. [1] Actually, I need to read more to completely understand the concept of momentum.
[1] 优快云, dongapple. “在神经网络中weight decay, momentum, batch normalization各自意义”
The energy function is computed by a pixel-wise soft-max over final feature map combined with the cross entropy loss function.
The ideal initial weights of the network should satisfy the condition that each feature map has approximately unit variance. The research set the initial weight from Gaussian distribution with standard diviation of sqrt(2/N), where N denotes the number of incoming nodes of a single neuron.
Data argumentation:
The main idea is to do random elastic deformation to the images. I cannot completely understand the precise operation.
To supplement the dataset, the researchers used some elastic deformation. Random elastic deformations are important variation among tissues and cells. Those deformations helped the network to learn the invariance of the images without large dataset.
Experiment Report based on ISBI Challenge of U-net
1.Preparation
Source code:
Retrieved from github: https://github.com/milesial/Pytorch-UNet
Dataset:
Retrieved from ISBI website: http://brainiac2.mit.edu/isbi_challenge/
Dataset Processing:
I converted the each .tif file into 30 jpg pictures by an online converter and then put the “train_volume” images into /imgs folder, the “train_labels” images into /masks folder and the “test_volume” images into /target folder.
I revised the code in dataset.py so that the model can correctly read in the imgs.For example, I changed the file path of images and the number of channels.
I found that Pytorch 1.5.1 is only compatible with certain version of cuda tools. Therefore, I reinstalled my cuda to version 10.1. I also have to change the value num_workers to 1 due to my limited GPU kernel.
2.Training:
I firstly trained the network with default mode. However, after 5 epochs, the outputs are still blank. With more epochs trained, I can clearly see better performance of the output images on segmentation. Then I changed the learning rate from 0.001 to 0.01. The model gave better performance with less epochs.
We can give some hyper-parameters with command:
python train.py -l 0.01 -e 100 -f 1.pth
Where -l denotes the learning rate, -e denotes the number of training epochs, -f denotes the loading model.
In the readme file, the author claimed that we could have better results if we enlarged the scale to 1. However, due to the limit of my GPU memory, I cannot validate it.
The model picked dice loss coeficient as loss function.
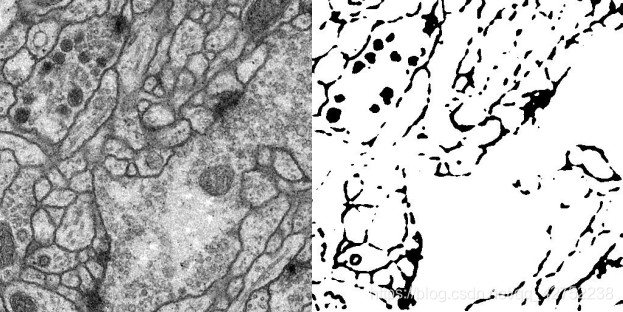
图 1 Input/Output 1 with lr=0.01, scale=0.5, spoch=70
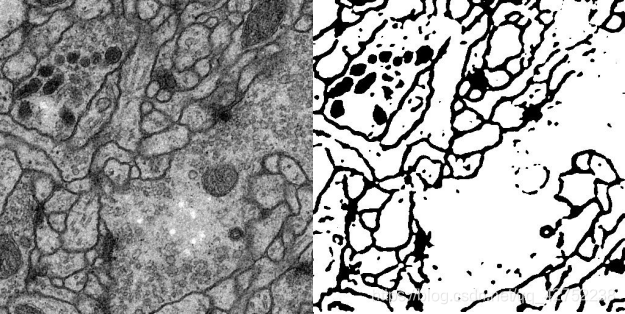
图 2 Input/Output 2 with lr=0.01, scale=0.5, epoch=70
Besides, I found an interesting phenomenon. Figure a is the result of training the network for 100 epochs. Figure b is the result of training the network first for 100 epochs and for another 1 epoch based on the 100th pth. Figure c is the result of training the network first for 100 epochs and for another 10 epochs based on the 100th pth. The performances of them are: c >> b >> a

图 3 a: 100 epochs b: 100+1 epochs c: 100+10 epochs


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









