






论文链接:https://arxiv.org/abs/2403.07332
Code: https://github.com/wjh892521292/LKM-UNet
来源: Medical Image Computing and Computer Assisted Intervention – MICCAI 2024
摘要:
临床背景与需求:医学图像分割能提供目标器官或组织的轮廓和尺寸信息,帮助提高疾病诊断和治疗的效果。
现有技术的局限性:目前主要使用卷积神经网络(CNNs)和Transformer方法,但它们在捕获大范围信息(受限的感受野)或高计算成本(长距离依赖建模)方面存在不足。
引入Mamba模型:Mamba是一种状态空间序列模型(SSM),能以线性复杂度高效建模长距离依赖,具有潜力弥补上述不足。
提出的新模型——LKM-UNet:本研究设计了基于大核Mamba的U形网络(LKM-UNet),提升局部空间建模能力(通过大核尺寸)和全局建模的效率(相比于自注意力机制的二次复杂度)。
创新设计——层次化和双向Mamba块:为了增强模型的空间信息捕获能力,作者设计了新颖的层次化、双向Mamba模块,进一步优化模型表现。
实验验证:实验结果证明,使用大尺寸的Mamba核可以实现更大的感受野,展现出优越的效果和可行性。
1. 引言
医学图像分割的重要性: 医学影像中对目标器官或组织(如病变)的精准分割,能显著促进临床诊断与研究。
现有技术的局限性
- CNN(如UNet):擅长逐级提取局部细节(像素级特征)但受限于有限的感受野,难以捕获长距离依赖关系。虽然最近研究尝试用大卷积核改善,但实现复杂,优化困难。
- Transformer:能出色进行全局长距离建模,但会牺牲像素级别的空间细节;尤其是基于自注意力(Self-Attention)机制的方式,计算复杂度为二次(quadratic),限制了在大图像中的应用。
- 混合模型(CNN-Transformer):试图结合两者优点,但大尺寸医学图像带来了交互复杂度难题。
新兴的结构化状态空间模型(SSMs)
- Mamba等模型:以线性复杂度实现长距离序列建模,原本用于自然语言处理,但也在计算机视觉中展现潜力。
- 潜力与挑战:
- 具有较大空间可调性(大感受野)但原本为单向模型,缺乏位置感,难以处理空间连续性,容易出现“遗忘”问题(局部信息欠缺或不连续)。
- 原始设计适合一维序列(文本等),不直接适用于处理空间结构。
本文提出的LKM-UNet模型,核心创新:
- 大卷积核的Mamba模块(Large Kernel Mamba):赋予模型大感受野能力,能高效捕获全局及局部信息。
- 层次化与双向设计的LM块(Large Kernel Mamba Block):
- 双向性(Bidirectional):增强位置感和序列感知,减少输入序列顺序的影响。
- 层次化结构:包括两种操作
- 像素级SMM(PiM):用于邻域像素的局部信息捕获,避免由分块(tokenization)导致的邻近像素不连续问题。
- 块级SMM(PaM):处理全球性长距离依赖和块之间的全局交互。
该模型通过赋予SSM大感受野、设计双向序列建模、结合像素级和块级SSM操作,解决传统模型在捕获局部细节与全局信息之间的矛盾。实验验证其在2D和3D医学影像分割中的优越表现。
2. SSM模型
基于SSM(结构化状态空间模型,Structured State Space Models)的方法,特别是S4和Mamba模型的数学基础和工作原理如下:
连续系统描述:这些模型起源于描述一类连续的动态系统,其核心数学形式是一阶线性常微分方程(ODE):
h′(t)=Ah(t)+Bx(t)y(t)=Ch(t) h^′(t)=Ah(t)+Bx(t) \\ y(t)=Ch(t) h′(t)=Ah(t)+Bx(t)y(t)=Ch(t)
其中:
- h(t)∈RNh(t)∈R^Nh(t)∈RN 是隐藏状态(对应模型的内部记忆或中间表示);
- x(t)x(t)x(t) 是输入(可以是一维函数或序列);
- A∈RN×NA∈R^{N×N}A∈RN×N 是状态转移矩阵(描述状态的动态变化);
- B∈RNB∈R^NB∈RN 和 C∈RNC∈R^NC∈RN 分别是输入映射和输出映射的参数(投影矩阵/向量)。
从连续系统到离散版本:实际应用中多为离散的序列建模,因此需要将连续系统通过时间间隔 Δ 进行离散化。使用零阶保持(Zero-Order Hold, ZOH)进行离散化,得到:
A^=exp(ΔA)B^=(ΔA)−1(exp(ΔA)−I)ΔB \hat A=exp(ΔA) \\ \hat B=(ΔA)^{−1}(exp(ΔA)−I)ΔB A^=exp(ΔA)B^=(ΔA)−1(exp(ΔA)−I)ΔB
这里,exp(ΔA)exp(ΔA)exp(ΔA) 表示矩阵指数,表示在时间ΔΔΔ内状态的演变。
离散后,系统方程变为:
h′(t)=A^h(t)+B^x(t)y(t)=Ch(t) h^′(t)=\hat Ah(t)+\hat Bx(t) \\ y(t)=Ch(t) h′(t)=A^h(t)+B^x(t)y(t)=Ch(t)
与连续版形式相似,但参数已由连续到离散转换得来。
输出计算:最终输出 y(t)y(t)y(t) 由输入序列 x(t)x(t)x(t) 和一个结构化卷积核 KKK 进行卷积(在序列长度 LLL 上):
y=x∗K^ y=x∗ \hat K y=x∗K^
其中:
K^=(CB^,CAB^,CA^L−1B^) \hat K=(C \hat B,C\hat {AB},C\hat A^{L−1} \hat B) K^=(CB^,CAB^,CA^L−1B^)
这是将状态空间模型中的参数通过矩阵乘积组合,形成一个结构化的卷积核,能高效捕获长距离依赖。
- S4和Mamba模型借鉴连续系统的动态描述,将序列建模转化为一个状态空间系统,通过离散化后,利用矩阵指数和线性运算实现高效的序列处理。
- 这种建模方式具有线性复杂度(相比传统自注意力的二次复杂度),适合长序列信息的捕获,特别是在自然语言和计算机视觉中的应用。
3. 方法
3.1 LKM-UNet
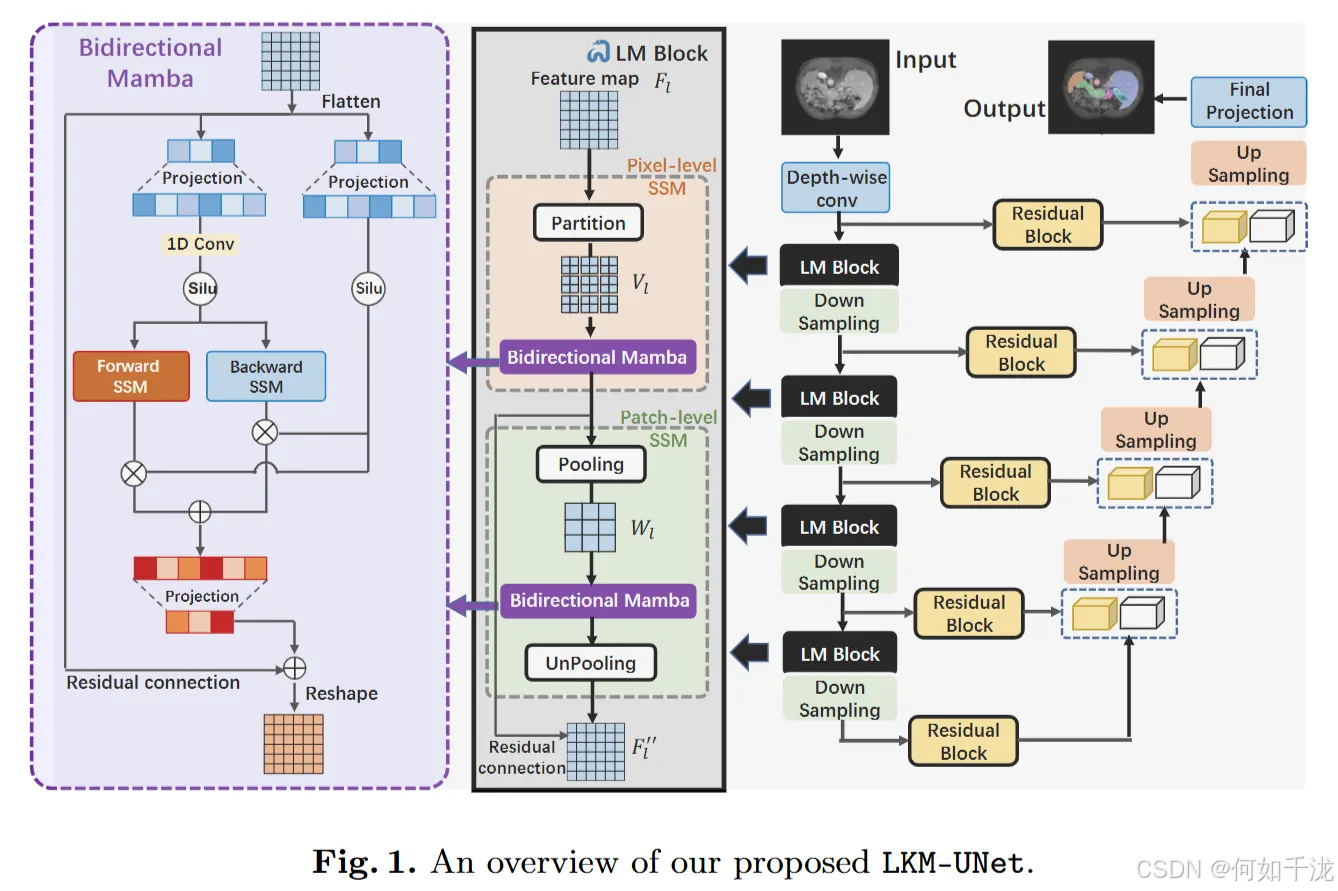
总体架构(Fig. 1), 基于标准的UNet结构,包括:
- 编码器(encoder): 含有下采样(downsampling)层
- 解码器(decoder): 含有上采样(upsampling)层
- 侧边连接(skip-connection)
改进点:在编码器部分插入了大核Mamba(LM)块,以增强模型的空间建模能力。
输入处理:
- 输入为3D图像,尺寸为 C×D×H×WC×D×H×WC×D×H×W,即包含多通道,它经过深度逐层卷积(depth-wise convolution)进行编码。
- 这一步将原始输入编码成特征图 F0∈R48×D2×H2×W2F_0∈R^{48}×\frac {D} {2}×\frac {H} {2}×\frac {W} {2}F0∈R48×2D×2H×2W,即通道数为48,空间尺寸缩小一半。
特征提取流程:
- 编码的特征图 F0 被送入每个LM块和对应的下采样层。在每一层(第l层)中,经过两个主要的模块:
- 像素级SSM(PiM):用于捕获局部邻域的像素信息。
- 块级SSM(PaM):用于捕获全局范围的块间关系。
- 这两个模块的数学表达为:
Fl′=PiM(Fl),Fl′′=PaM(Fl′),Fl+1=Down−sampling(Fl′′) F_l^′=PiM(Fl),F_l^{′′}=PaM(F_l^′),F_{l+1}=Down-sampling(F_l^{′′}) Fl′=PiM(Fl),Fl′′=PaM(Fl′),Fl+1=Down−sampling(Fl′′)
- 这表明在每一层,特征在经过像素级和块级SSM处理后,被下采样以获得更深层次的多尺度特征。
- 特征的编码与尺度变化:每经过一层,下采样后得到的特征图 Fl+1 被重新编码为:(2Cl,Dl2,Hl2,Wl2)(2C_l,\frac {D_l}{2},\frac {H_l}{2},\frac {W_l}{2})(2Cl,2Dl,2Hl,2Wl)
- 其中,ClC_lCl 是通道数,{Dl,Hl,Wl}\{ D_l,H_l,W_l \}{Dl,Hl,Wl}是空间尺寸。
- 这一过程确保逐层提取多尺度、多层次的特征信息。
解码部分(decoder):
- 使用标准的UNet解码器结构,以及残差块(residual block)和跳跃连接(skip connections)。
- 这些元素帮助逐步恢复空间信息,最终生成分割掩码。
3.2 LM block

LM块的作用与创新性:
- 多尺度空间建模:LM块旨在同时实现像素级和补丁级的空间关系建模,与传统方法(使用CNN进行局部像素建模,Transformer进行全局依赖建模)不同,LM块结合两者优势。
- 大核(Large Kernel)优势:采用大尺寸核(窗口)能扩大感受野,提升局部建模的效率,且由于Mamba模型具有线性复杂度,使用大核成为可能。
层级结构:PiM与PaM:
- Pixel-level SSM(PiM):
- 局部邻域像素建模,解决Mamba作为连续模型时的“信息遗忘”问题。
- 具体做法是将特征图划分成多个大子核(子窗口),在每个子核内进行Mamba操作,以实现连续的局部像素关系的建模。
- 大核划分提升了局部细节的捕获能力,但需要机制实现不同子核间的信息交流。
- 具体操作:
- 将二维特征图(大小为H×WH×WH×W)均匀划分成非重叠的子核,每个子核的大小为m×nm×nm×n(m和n可以最大达到40)。
- 假设H是m的整数倍,W是n的整数倍(保证划分整除),则可以得到HW/mnHW/mnHW/mn个子核。
- 每个子核内的像素连续输入到Mamba层中处理。
- Patch-level SSM(PaM):
- 处理全局长距离依赖关系。
- 通过对特征映射进行池化(按m×nm×nm×n大小)以获得代表性特征,再用Mamba进行跨子核的通信,最后进行反池化恢复原始大小(结合残差连接)。
- 使模型能在更大范围内捕获相关性,提升全局建模能力。
- 具体操作流程:
- 特征图池化(Pooling):
- 输入特征图 Fl′F_l^′Fl′(大小为H×WH×WH×W)首先经过一个尺寸为 m×nm×nm×n 的池化层。
- 这样,每个子核(大小为 m×nm×nm×n)的局部信息被压缩成一个代表值。
- 经过池化后,整个特征图被缩减为包含 HW/mnHW/mnHW/mn 个代表值,这些代表值构成了聚合图 ZlZ_lZl。
- 跨子核通信(用Mamba实现):
- 这些代表值(ZlZ_lZl)经过双向Mamba(Bi-Mamba)处理,进行全球范围的依赖建模。
- 这一过程实现了不同子核之间的信息交流,提升了模型对全局关系的理解。
- 反池化(Unpooling):
- 经过Mamba处理后的信息(Wl′W_l^′Wl′)被反池化(Unpooling)到原始的特征图尺寸。
- 这一操作将全局信息融合到原始空间中
- 特征图池化(Pooling):
双向Mamba(BiM)设计:与只考虑单向扫描的原始Mamba不同,BiM同时进行前向和后向扫描(双向),并将两个方向的结果叠加。
优势包括:
- 更加专注于图像中间区域(如器官和病灶较多的区域),而非边角。
- 更好地建模位置关系(绝对和相对位置),增强模型的空间感知能力。
4. 实验
4.1 数据集
实验目的:
- 通过与当前最先进的方法(如其他主流模型)进行对比,验证LKM-UNet在医疗图像分割中的效果。
- 测试模型在不同类型和维度数据集上的泛化能力和扩展性。
数据集介绍:
- Abdomen CT(腹部CT)数据集:一个公开的3D多器官分割数据集。来源:MICCAI 2022 FLARE挑战。
- 内容:包含100个CT病例,涵盖13种腹部器官(如肝、脾、胰腺、左右肾、胃、胆囊、食管、主动脉、腔静脉、左右肾上腺和十二指肠)。
- 图像尺寸:40(深度)× 224(高度)× 192(宽度)。
- 训练集:使用来自MSD Pancreas数据集(标注来源于AbdomenCT-1K)中的50个病例。
- 测试集:来自其他不同的医疗中心的50个病例。
- Abdomen MR(腹部MRI)数据集:一个公开的2D分割数据集。来源:MICCAI 2022 AMOS挑战。
- 内容:包括110个MRI案例,涵盖与CT数据集相同的13种腹部器官。
- 图像尺寸:320 × 320(像素)。
- 训练集:60个标注病例(依据之前的研究工作)。
- 测试集:50个病例。
4.2 实验设置
实现平台:使用的是PyTorch 1.9.0,基于nnU-Net框架进行开发。
硬件环境:NVIDIA GeForce RTX 3090 GPU
训练参数:
- 批处理大小(Batch size):
- 3D数据(Abdomen CT):采用两张图像一批(batch size=2),以适应3D图像较大计算量。
- 2D数据(Abdomen MR):采用24张图像一批(batch size=24),因为2D图像计算需求较低,更大批量有助于训练稳定性。
- 优化器:使用Adam优化器,动量参数设为0.99,提供平滑的梯度更新,有助于模型更快收敛。
- 学习率和正则化:
- 初始学习率为0.01。
- 权重衰减(weight decay)为3×10^(-5),用于防止过拟合。
- 训练周期:最大训练轮数为1000轮,确保模型有充分的训练时间。
- 模型结构细节:
- Abdomen CT(3D):
- 模型共有6个阶段(stage=6)。
- 由于不同阶段的特征图尺寸不一致,设置了不同的三维卷积核尺寸:
- 第一和第二阶段: [20, 28, 24]
- 第三和第四阶段: [10, 14, 12]
- 第五和第六阶段: [5, 7, 6]
- Abdomen MR(2D):
- 模型包含7个阶段(stage=7)。
- 每个阶段的卷积核大小依次为: 40、20、20、10、10、5、5。
- Abdomen CT(3D):
4.3 整体表现
基线模型的类别:
- CNN基础的网络:如nnU-Net和SegResNet。这些模型以卷积神经网络为核心,擅长局部特征提取。
- Transformer基础的网络:如UNETR、SwinUNETR 和 nnFormer。这些模型利用Transformer结构,具有更宽的感受野和全局建模能力。
- 最新的Mamba基础网络:如U-Mamba,使用Mamba作为核心,强调长距离依赖建模。
实验设计的公平性:
- 所有模型均在nnU-Net框架中实现,确保平台一致性。
- 使用默认的图像预处理方法,避免人为干预导致的偏差。

实验结果:表1中的结果显示,提出的LKM-UNet在两个指标(DSC:Dice Similarity Coefficient, NSD:Normalized Surface Distance)上均优于其他模型。这表明Mamba在全球建模能力(整体上下文特征捕获)方面对于医疗图像分割至关重要。
关于U-Mamba和LKM-UNet的比较:
- U-Mamba只是单纯将Mamba用作全局建模的工具。
- LKM-UNet在U-Mamba基础上加入了双向和层次化的Mamba设计,实现了更优的性能。
4.4 核大小的重要性
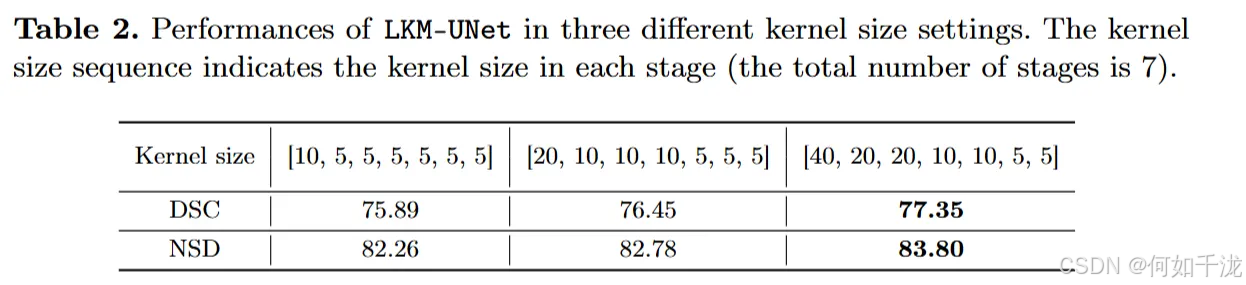
通过比较三组不同核大小配置的性能,可以看到,使用较大核尺寸的LKM-UNet表现更优。这说明,在医学图像分割中,拥有较大的感受野(即能同时考虑较大范围信息)是非常关键的。由于Mamba的线性复杂度,它能够高效实现更大的感受野,从而提升模型的性能。
- Mamba能够实现大范围空间建模(较大感受野)
- 增大核尺寸(感受野)确实带来性能提升, 这强调了大范围空间信息在医学图像分析中的重要性
- Mamba的线性复杂度使得在保持效率的同时实现大感受野成为可能
4.5 消融实验
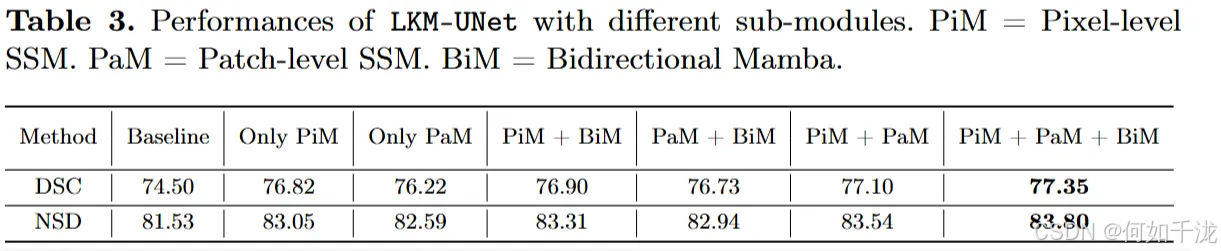
在腹部磁共振(MR)数据集上进行了消融实验(即逐一验证模型中不同关键组件的作用),结果详见表3。
- 结果显示,加入PiM(像素级空间关系建模)和PaM(块级空间关系建模)都能提升LKM-UNet相对于基础模型的性能。这验证了两者在分别进行局部像素级建模和全局建模上的优势。
- 其中,带有PiM的模型带来的改善更明显,表明扩大局部区域的感受野(即理解更多局部信息)是提升模型性能的关键。
- 引入BiM(双向Mamba)后,模型性能继续提升,强调了双向(前后两个方向)空间建模在位置感知中的重要作用。
4.6 有效感受野可视化

为了更详细地展示模型的感受野(即模型能够“看到”的区域范围),展示了其它方法和LKM-UNet的有效感受野(ERF)如图3所示。
- 基于卷积神经网络(CNN)的方法主要侧重于局部特征提取,ERF相对较小;
- Transformer基方法具有更宽泛的ERF,能够捕获更大范围的特征;
- 虽然U-Mamba使用Mamba机制实现了全局ERF,但这会削弱部分局部的注意力机制;
- 相比之下,作者提出的LKM-UNet利用大核(large kernel)Mamba实现了更大的ERF,在全局和局部两个方面都得到了增强。

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









