






Requests模块是一个用于网络访问的模块,类似的模块有urllib,urllib2,httplib,httplib2等
在爬虫中常使用的模块:
获取网页内容的----- urllib, requests
分析网页常用的模块------ re, bs4(beautifulsoup4)
一 安装Requests
pip install requests
示例:
import requests
url = 'http://www.taobao.com'
response = requests.get(url)
print(response)
print(response.text)
print(type(response.text))


可以看到 get类就可以直接访问了,再通过该类中的方法,就可以查看具体的内容了。并且还可以看到其内容的类型是字符串
还可以查看其访问状态和cookie信息等
print(response.status_code)
print(response.cookies)

二 具体的Requests操作
1.常见的请求方式
上传与删除:
import requests
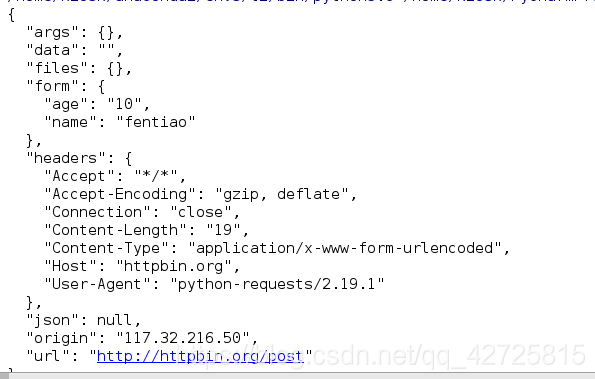
response = requests.post('http://httpbin.org/post', data={'name' : 'fentiao', 'age':10})
print(response.text)
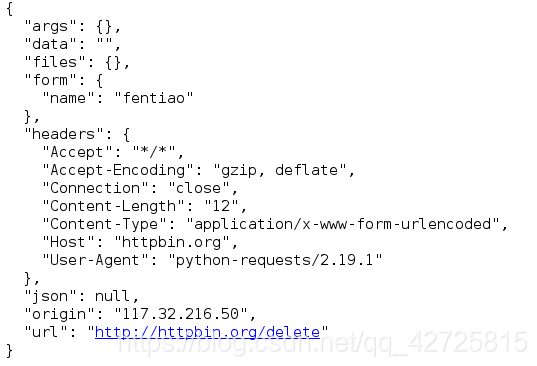
response = requests.delete('http://httpbin.org/delete', data={'name' : 'fentiao'})
print(response.text)
2.带参数的get请求
比如说要访问一个网址(url1 = 'https://movie.douban.com/subject/4864908/comments?start=20&limit=20&sort=new_score&status=P),但是它太长了
这时就可以将其解析,后面的参数可以作为参数传进去
import requests
data = {
'start': 20,
'limit': 40,
'sort': 'new_score',
'status': 'P',
}
url = 'https://movie.douban.com/subject/4864908/comment'
response = requests.get(url, params=data)
print(response.url)

3.解析json格式
和json模块相结合,将所需的内容转换成所需要的格式
import requests
ip = input("请输入查询的IP:")
url = "http://ip.taobao.com/service/getIpInfo.php?ip=%s" %(ip)
response = requests.get(url)
content = response.json()
print(content)
print(type(content))

4.获取二进制数据
1). 下载图片
import requests
url = 'https://gss0.bdstatic.com/-4o3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=4f7bf38ac3fc1e17fdbf8b3772ab913e/d4628535e5dde7119c3d076aabefce1b9c1661ba.jpg'
response = requests.get(url)
with open('github.png', 'wb') as f:
# response.text : 返回字符串的页面信息
# response.content : 返回bytes的页面信息
f.write(response.content)

2)下载视频
import requests
url = "http://gslb.miaopai.com/stream/sJvqGN6gdTP-sWKjALzuItr7mWMiva-zduKwuw__.mp4"
response = requests.get(url)
with open('/tmp/learn.mp4', 'wb') as f:
f.write(response.content)

5. 添加headers信息
可以直接添加header信息,更加简洁的进行浏览器的伪装
import requests
url = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
headers = {
'User-Agent': user_agent
}
response = requests.get(url, headers=headers)
print(response.text)
print(response.status_code)

6.响应信息的操作
1).对象常用的属性:
import requests
url = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
headers = {
'User-Agent': user_agent
}
response = requests.get(url, headers=headers)
print(response.text)
print(response.content)
print(response.status_code)
print(response.headers)
print(response.url)
2).状态码的判断
利用三元运算符来进行判断
import requests
url = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
headers = {
'User-Agent': user_agent
}
response = requests.get(url, headers=headers)
exit() if response.status_code != 200 else print("请求成功")

7.上传文件
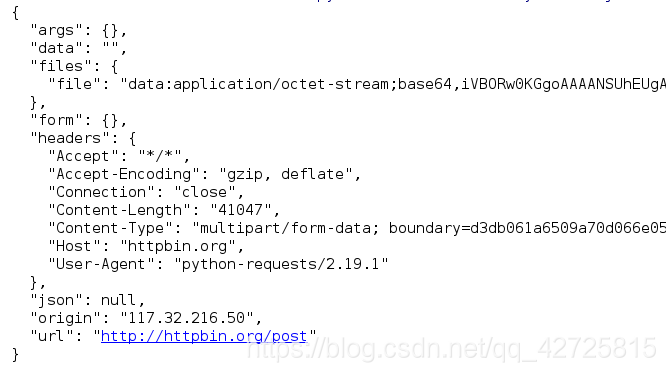
import requests
# 上传的数据信息(字典存储)
data = {'file':open('github.png', 'rb')}
response = requests.post('http://httpbin.org/post', files=data)
print(response.text)
8.获取cookie信息
1).获得的cookie信息是以字典的形式存在的
import requests
response = requests.get('http://www.youkuaiyun.com')
print(response.cookies)
for key, value in response.cookies.items():
print(key + "=" + value)

2).读取已经存在的cookie信息访问网址内容
import requests
# 设置一个cookie: name='westos'
response1 = requests.get('http://httpbin.org/cookies/set/name/westos')
response2 = requests.get('http://httpbin.org/cookies')
print(response1.text)
print(response2.text)
但是发现在第二次访问的时候,cookie信息并没有存在。
这是因为在第一次访问时,会话跟踪,但是在第二次访问时,会话已经断开,进行的是第二次的会话跟踪
这里就需要在两次访问之间将会话维持住,不让其断开
requests 中的 session 提供了这样的作用
import requests
# 设置一个cookie: name='westos'
s = requests.session()
response1 = s.get('http://httpbin.org/cookies/set/name/westos')
response2 = s.get('http://httpbin.org/cookies')
print(response1.text)
print(response2.text)
9.忽略证书验证
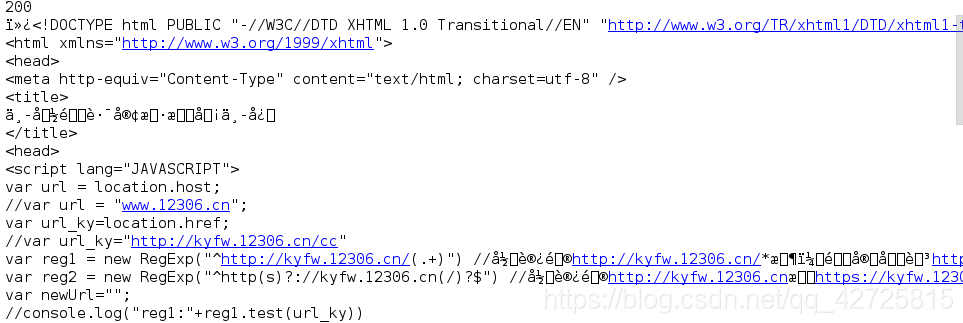
有些网站是需要进行证书验证的,比如我们熟知的12306
#忽略证书验证
import requests
url = 'https://www.12306.cn'
response = requests.get(url, verify=False)
print(response.status_code)
print(response.text)
10.代理设置
设置超时时间:为 0.1s ,是访问不成功的
import requests
proxy = {
'https': '171.221.239.11:808',
'http': '218.14.115.211:3128'
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxy, timeout=0.1)
except:
print('time out')
else:
print(response.text)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









