






os.makedirs() 方法用于递归创建目录
- makedirs()方法语法格式如下:
os.makedirs(path, mode=0o777) - 参数
path – 需要递归创建的目录,可以是相对或者绝对路径。
mode – 权限模式。
os.path.join()函数用于路径拼接文件路径
路径表示
. 表示当前目录
.. 表示当前目录的上一级目录。
./表示当前目录下的某个文件或文件夹,视后面跟着的名字而定
../表示当前目录上一级目录的文件或文件夹,视后面跟着的名字而定。
os.path.join(‘…’, ‘data’, ‘house_tiny.csv’) 表示当前目录的data文件夹下的house_tiny.csv文件的目录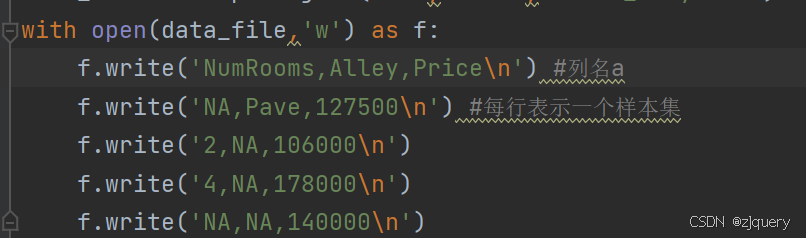
在上述新建的文件data_file里写内容。
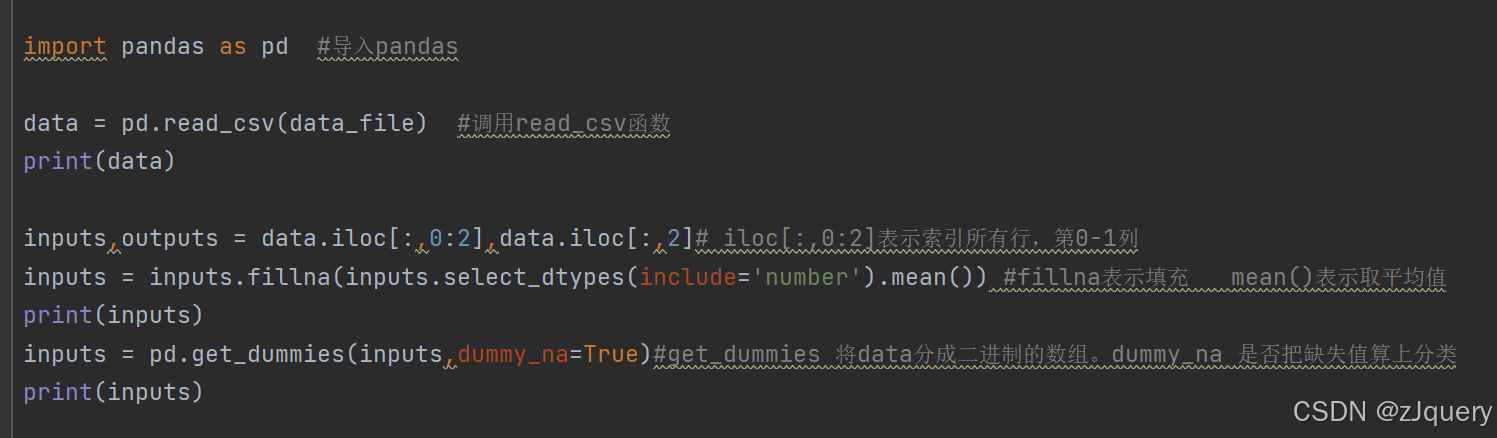 导入pandas包
导入pandas包
read_csv():将csv文件导入成data的数据
iloc[:0:2]: 冒号前是行,冒号后是列,索引范围为:全部的行,和第0-1列的值
fillna()表示填充所有NA值
mean()表示取维度的平均值
由于数据中有string,不能取数值的平均值,所以确定数据种类,只限数值
get_dummies:表示将数据的某一列或者一行分类成二进制数组,数值为0或1。
data: 要进行独热编码的 DataFrame 或 Series。
prefix: 生成的独热编码列的前缀。
prefix_sep: 生成的独热编码列的前缀和原始列名之间的分隔符。
dummy_na: 是否为原始数据中的缺失值生成独热编码列。
columns: 要进行独热编码的列的名称,如果指定,则只对这些列进行操作。
drop_first: 是否删除第一个独热编码列,以避免共线性问题
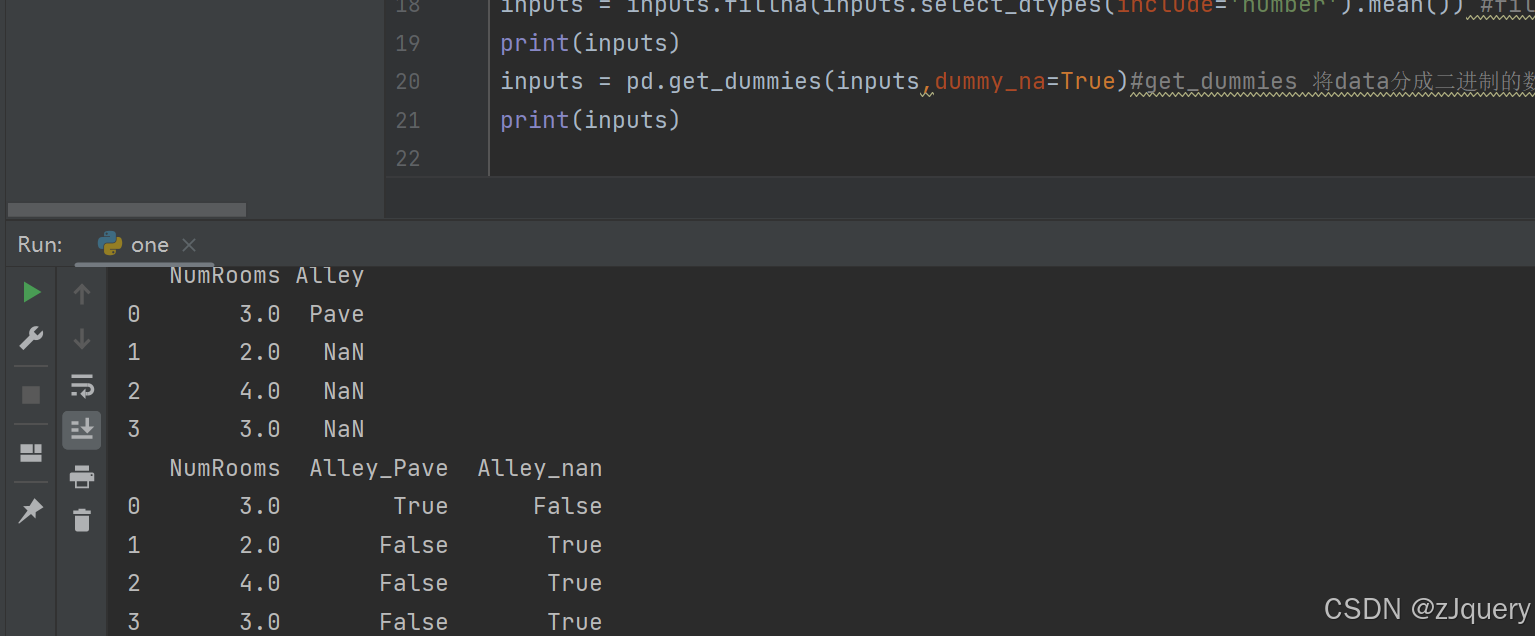 由于pandas版本(1.6.0)问题,结论全部都是布尔值,需要定义dtype=int;
由于pandas版本(1.6.0)问题,结论全部都是布尔值,需要定义dtype=int;
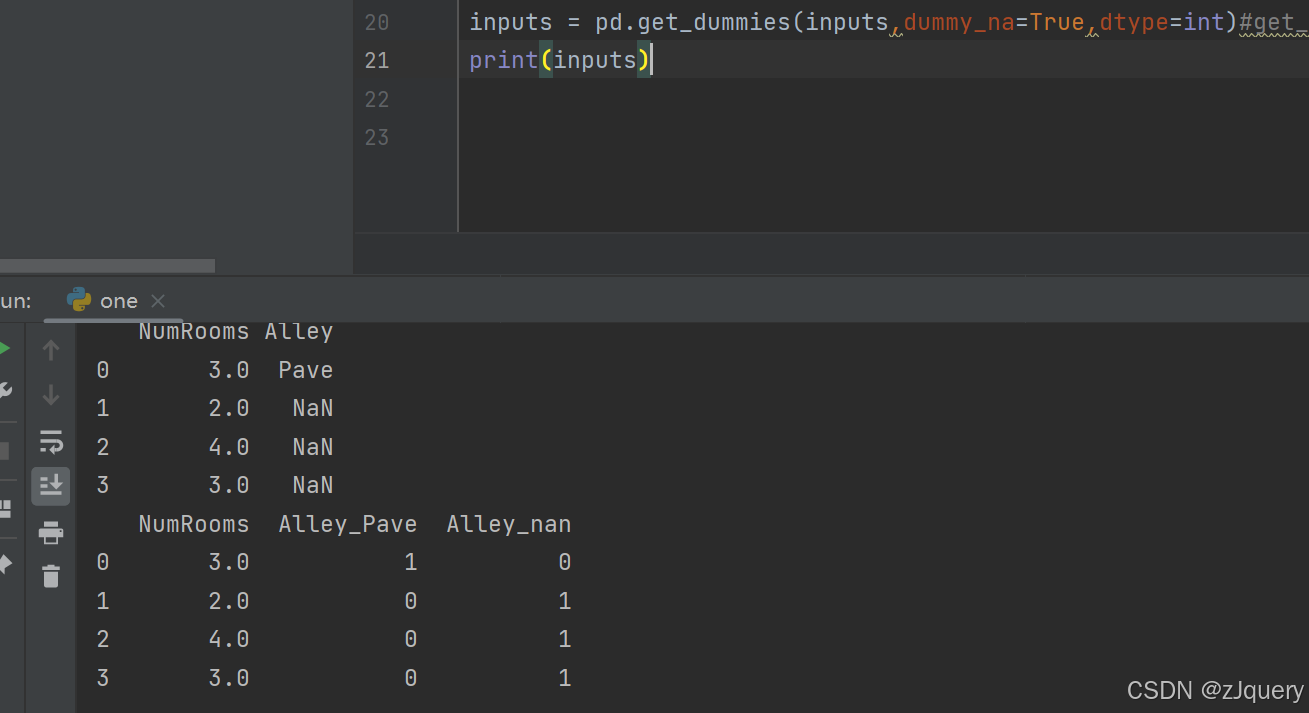 data数组有栏目,如果没有,需要加columns
data数组有栏目,如果没有,需要加columns
函数形式:dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









