










 本文介绍了作者基于React结构重写UI的过程,参考了PyOneDark但认为其源码不友好,因此自行重构。项目结构清晰,每个组件包含组件本身、静态数据和CSS。文章展示了数据查询组件的实现,包括筛选、表格和分页功能,由JSON驱动。
本文介绍了作者基于React结构重写UI的过程,参考了PyOneDark但认为其源码不友好,因此自行重构。项目结构清晰,每个组件包含组件本身、静态数据和CSS。文章展示了数据查询组件的实现,包括筛选、表格和分页功能,由JSON驱动。
1 写在前面
1.1 UI和平时做的一般B端管理系统结构差不多,同时也借鉴了国外那个pyOneDark。不过,笔者看过他的源码并不友好,感觉结构很乱,因此自己重撸了一遍,缩减了很多。
1.2 笔者学过一些react,所以本项目的结构是仿照react结构来做的,每一个组件里包括组件+静态数据(假数据和css)。然后通过main.py(APP.js/index.js)来作为入口。逻辑在封装好的组件里,结构极为清晰。
2 结构
2.1目录结构:
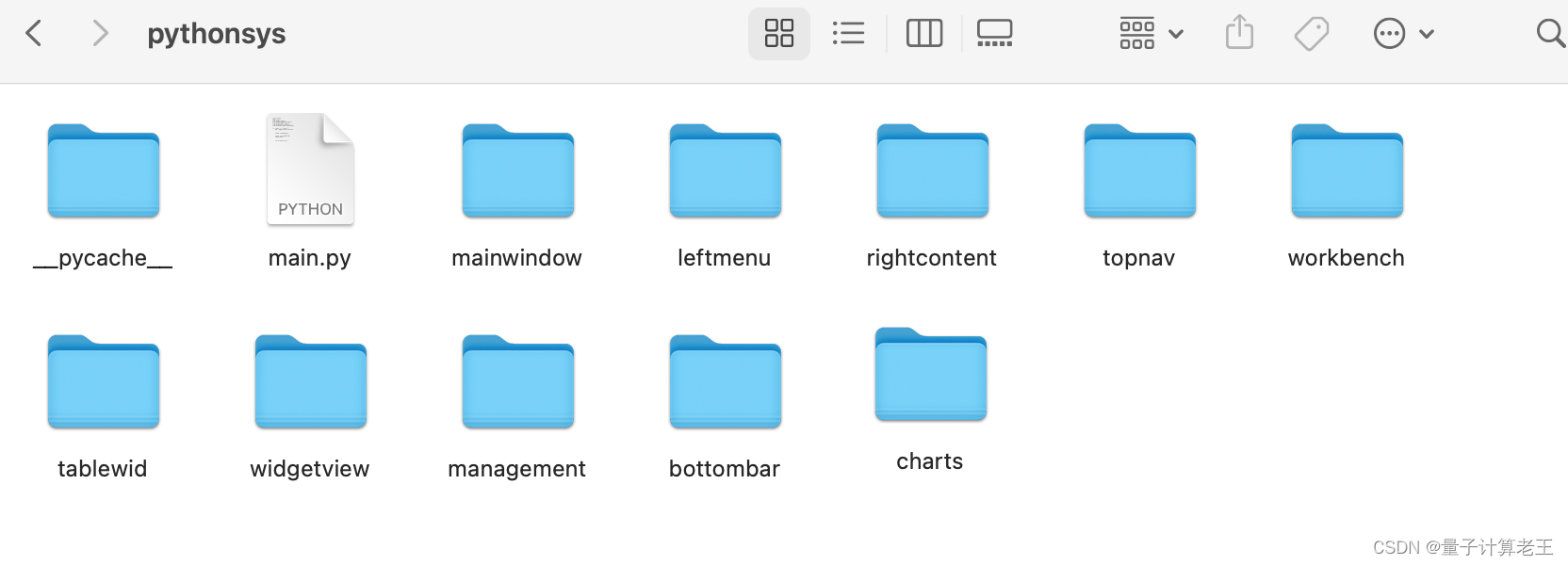
大家可以看到,结构和react结构非常相似(我喜欢这种结构)。不过缺少了config这种外层配置的,因为本人对这个配置驱动文件逻辑或者说项目理解不深,所以没将这部分动态的东西拿出来放到配置文件里统一管理。
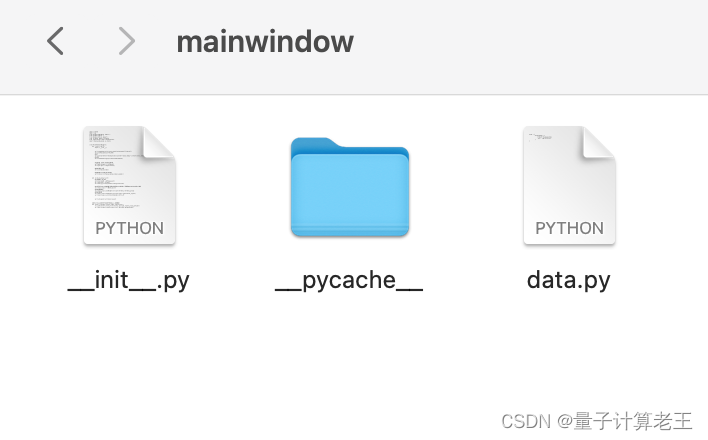
随机点开一个组件,所有组件结构基本上都是这样的结构。css和假数据都放到了组件文件夹下的data.py里。
3 代码示例
在这里我用封装并不太好的数据查询的组件来举例。包括筛选条件、表格按钮、表格、表格分页这几个类。由数据那一个大json驱动这个组件的具体的样子。(封装的并不完善,输入目前只有数据,后续可能加上更多属性,如列宽、排序、字段显隐、字段顺序、分页样式等等)

4 demo展示
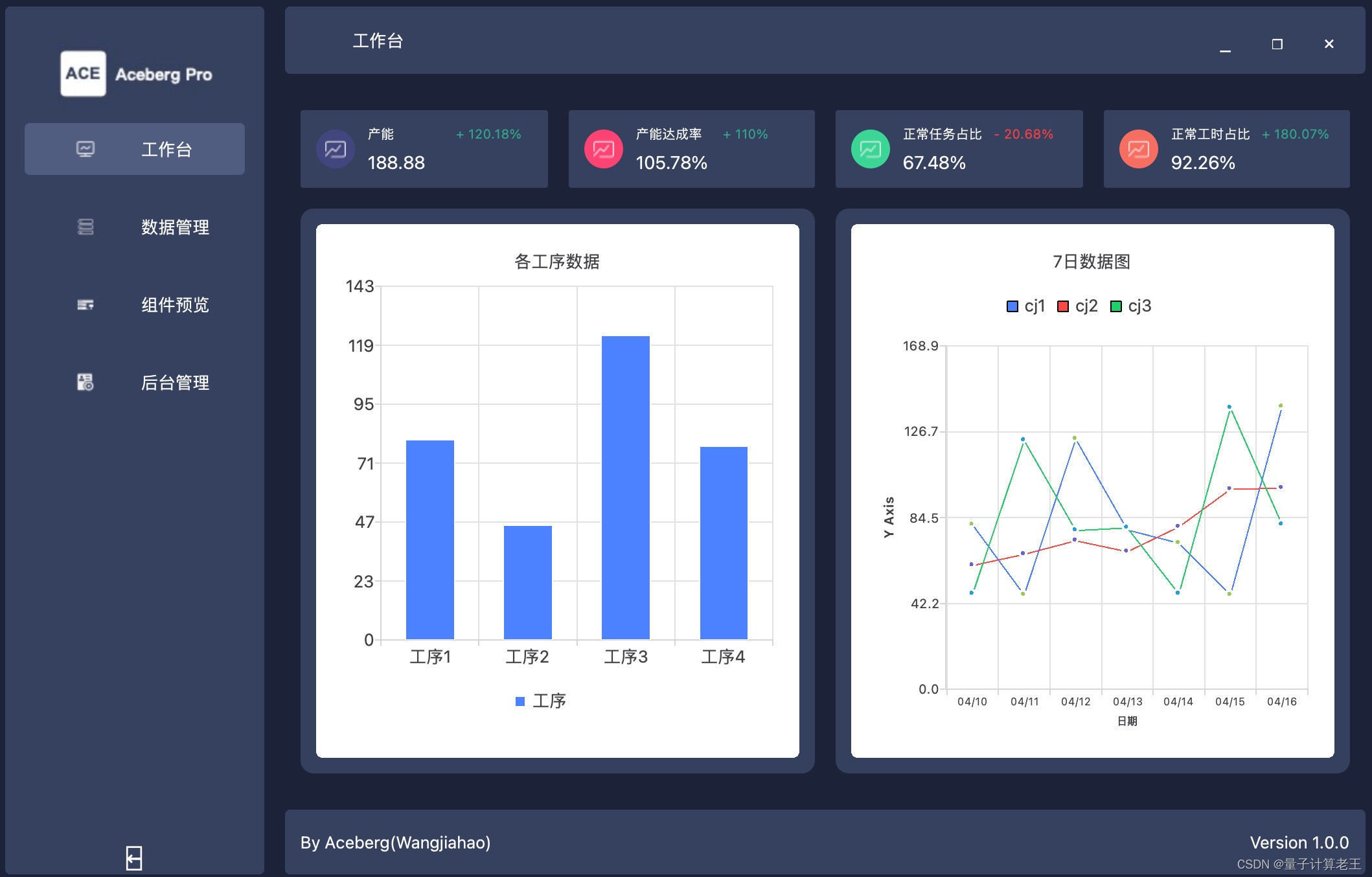
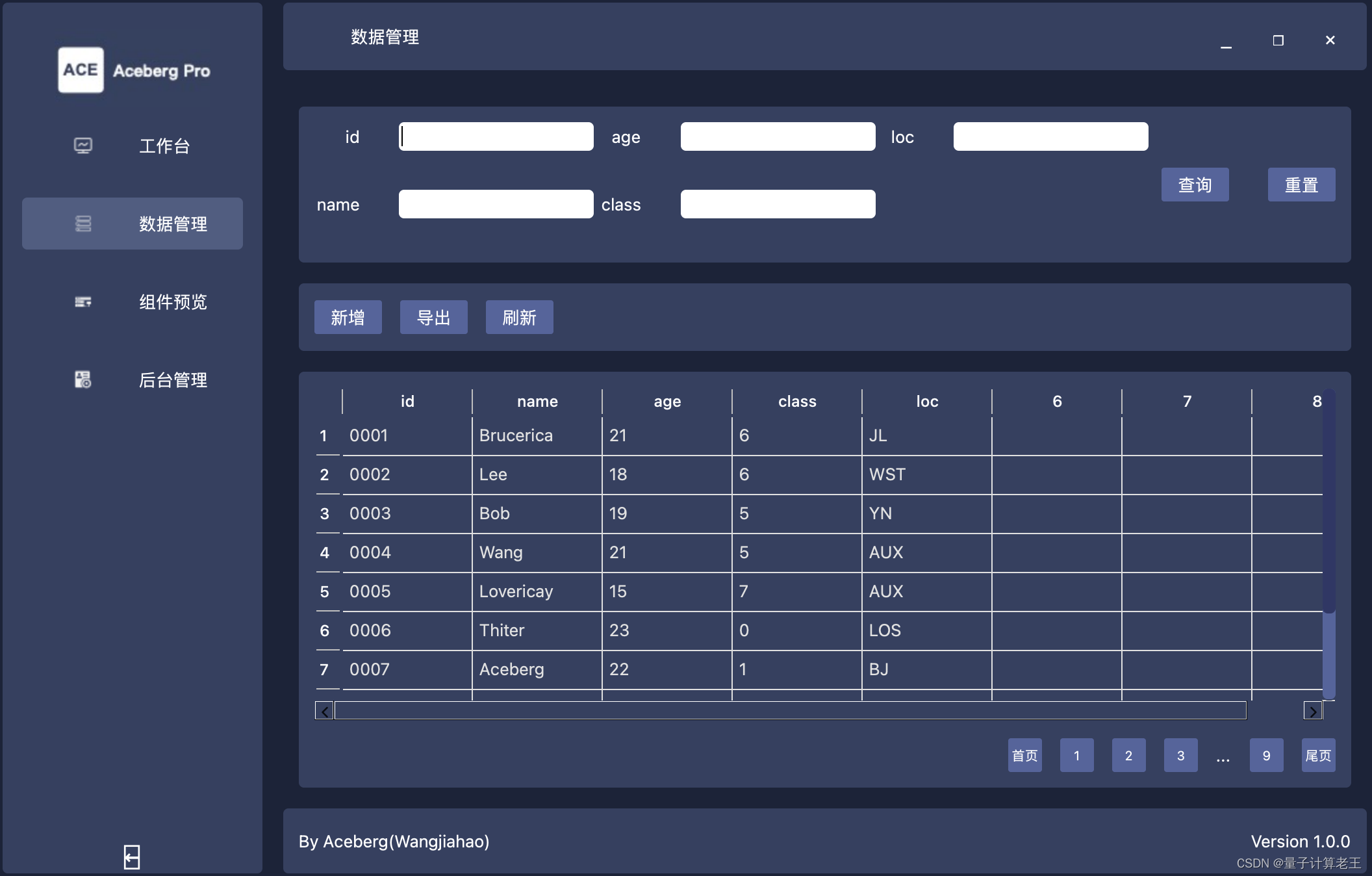
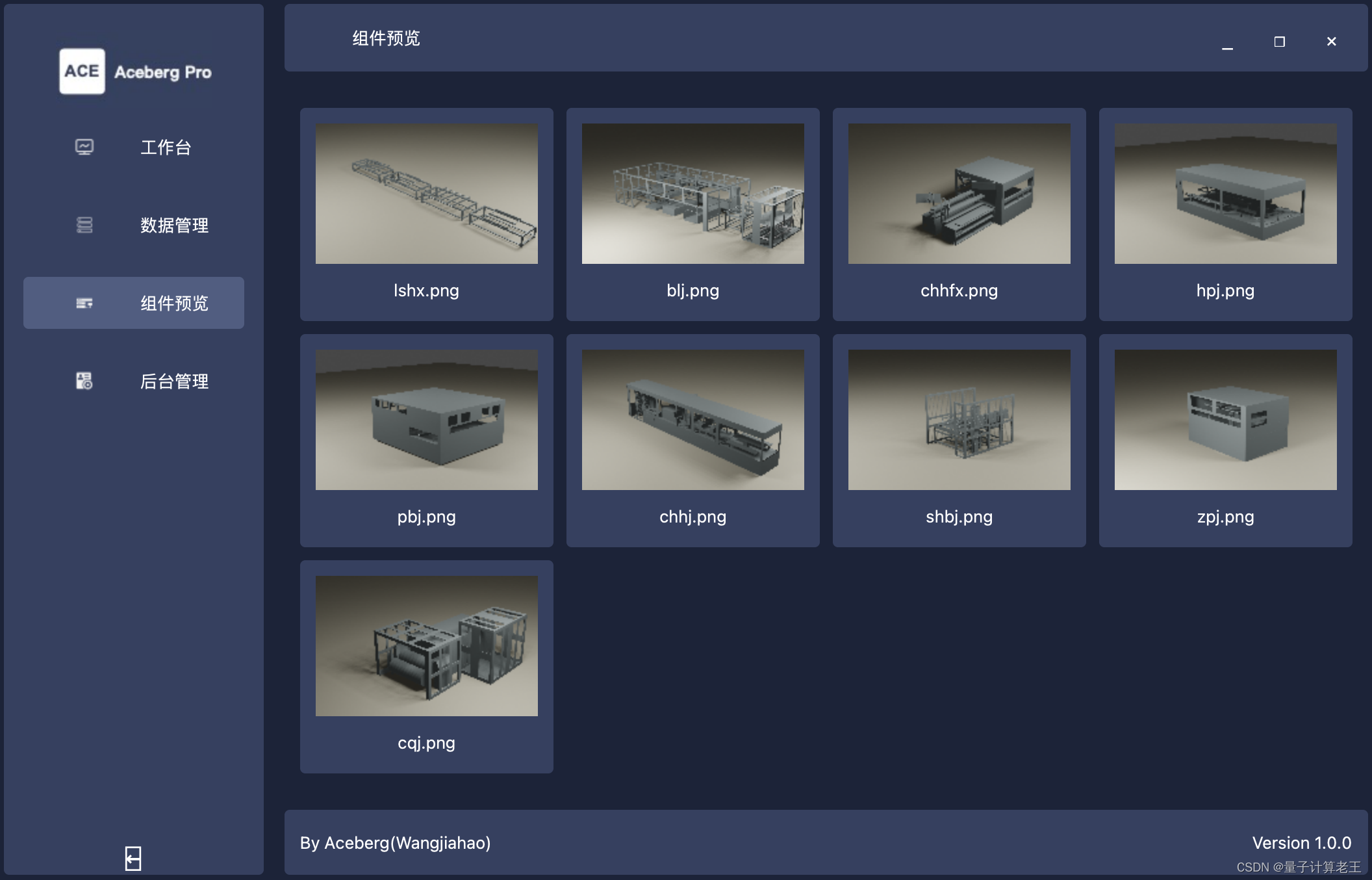

demo video:
【纯手撸】使用pyside6 / pyqt 构建现代化 普通toB系统 图形化界面 Aceberg Pro

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









