




 本文深入解析正则表达式的各种模式,包括非贪婪与贪婪模式的区别,预定义字符组的使用,以及如何通过实例理解电子邮件地址的匹配。同时,介绍了常用的正则函数如findall, match, search的功能和应用。
本文深入解析正则表达式的各种模式,包括非贪婪与贪婪模式的区别,预定义字符组的使用,以及如何通过实例理解电子邮件地址的匹配。同时,介绍了常用的正则函数如findall, match, search的功能和应用。
非贪婪模式(. * ?)
-
. 单个字符
-
‘*’ :表示0~n
-
? 表示0~1
-
组合后表示非贪婪模式,即尽可能少地匹配字符。
s='abcadcaecd'
r1=re.findall('ab.*?c',s) #非贪婪模式
print(r1)
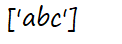
贪婪模式
贪婪模式即除了非贪婪模式下的三个字符组合,其他的任意组合都是非贪婪模式,即尽可能多地匹配字符
s='abcadcaecd'
r=re.findall('ab.*c',s) #贪婪模式,尽可能多地匹配
print(r)
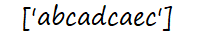
预定义字符组
- \d 匹配0~9这十个数字。
s='<a href="asdf">157875456748</a>'
a=re.findall('(\d.*\d)',s) #前后都是\d才能取到完整数字,中间是贪婪模式
print(a)
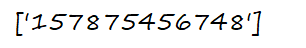
- \D 匹配非数字字符,并返回单个字符
s='<a href="asdf">157875456748</a>'
a=re.findall('\D',s)
print(a)
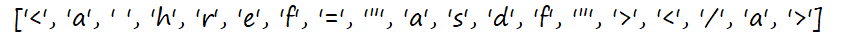
- \s 匹配任一空白符
s='fd\tcd\nef\x0b\fjk\r'
a=re.findall('\s',s)
print(a)
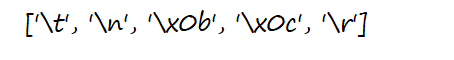
- \S 匹配任意非空白符
s='fd\tcd\nef\x0b\fjk\r'
a=re.findall('\S',s)
print(a)
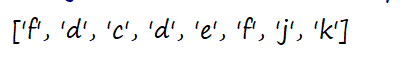
- \w 匹配任一字母数字字符 包括字母数字下划线汉字
s='重生后123e_fg<a href="asdf">'
a=re.findall('\w',s)
print(a)
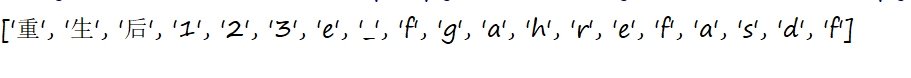
- \W 匹配任一非数字字母字符
s='重生后123e_fg<a href="asdf">'
a=re.findall('\W',s)
print(a)
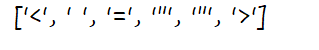
例子:取邮箱
"123456789@qq.com"
要想获取到该邮箱,需分析:
- 邮箱肯定是.com结尾,所以要用.com$
- 前面可以是数字或字母开头而且至少得有一个,可以用^\w+
- @和.com之间也可以是任意字符,所以也要用\w+
综上:正则表达式为:^\w+@\w+.com$
s='123456789@qq.com'
a=re.findall('^\w+@\w+.com$',s)
print(a)
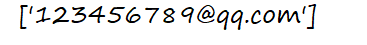
正则常用函数
- re.findall(): 将全部匹配后的内容匹配到一个列表中。
- re.match(): 只匹配开头,而且返回的是一个对象,可以通过group()函数来看返回的字符串。如果分了多个组,要用groups()函数来获取所有组的内容。
s='cats are cat'
a=re.match('c\w+',s)
b=re.findall('c\w+',s)
c=re.match('(c)(\w+)',s) //多个组
print(a.group())
print(b)
print(c.groups())
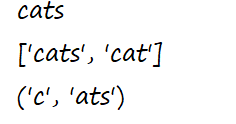
- re.search(): 全局匹配,和match对应,不过不仅仅是匹配开头,返回的也是对象。
s='cats are Cat' //注意两个cat不一样
c=re.search('(C)(\w+)',s)
print(c.groups())
即第一个cat不匹配,但会继续往后找,直到找到匹配的。
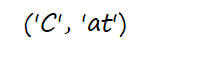

















 4338
4338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









