






深度学习进阶
深度学习的实现
训练, 验证, 测试集(Train/ Dev/ Test sets)
偏差方差
神经网络正则化
dropout正则化(Dropout Regularization)
随机删除神经单元
优化方法
mini-batch梯度下降法: p186
即每个batch反向传播一次
batch过大,单次迭代耗时长
batch过小,及为随机梯度下降法,失去向量化的加速增益,会在小范围收敛或波动
动量梯度下降法(Gradient descent with Momentum)
指数加权平均
v i = β v i − 1 + ( 1 − β ) θ i \ v_i = \beta v_{i-1} + (1-\beta)\theta_i vi=βvi−1+(1−β)θi
偏差修正
不直接使用 v i v_i vi而是如下转换: v i 1 − β i v_i \over 1-\beta^i 1−βivi
动量梯度下降法 Momentum
利用指数加权平均计算
d
W
dW
dW能够消除
d
W
dW
dW的震荡
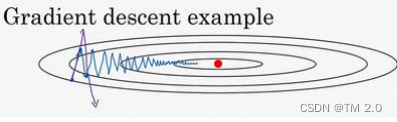
均方根 RMSprop(root mean square prop): p210
平均各个方向的梯度, 加速梯度下降:
S
d
w
=
β
S
d
W
+
(
1
−
β
)
(
d
W
)
2
S_{dw}=\beta S_{dW}+(1-\beta )(dW)^2
Sdw=βSdW+(1−β)(dW)2
W
:
=
W
−
a
d
W
S
d
W
W:=W-a{dW \over { \sqrt {S_{dW}}}}
W:=W−aSdWdW
Adam优化算法(Adam optimization algorithm):p213
超参: a , β 1 , β 2 , ϵ a,\beta_1,\beta_2,\epsilon a,β1,β2,ϵ


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









