



 本文介绍了通过lex工具设计和实现C语言词法分析程序的过程,涵盖了词法分析的工作内容、环境配置、功能要求及错误处理。实验者通过编写LEX源程序,利用flex生成词法分析器,对源代码进行单词符号识别、注释跳过、错误检查和恢复等操作,加深了对编译原理的理解。
本文介绍了通过lex工具设计和实现C语言词法分析程序的过程,涵盖了词法分析的工作内容、环境配置、功能要求及错误处理。实验者通过编写LEX源程序,利用flex生成词法分析器,对源代码进行单词符号识别、注释跳过、错误检查和恢复等操作,加深了对编译原理的理解。
编译原理与技术实验一
实验目的:
- 掌握词法分析程序的设计与实现方法
- 掌握词法分析的工作内容
实验环境:
(1)VMware Workstation 15 Player 虚拟机
(2)Ubuntu 18.04.2 操作系统
实验内容:
设计并实现c语言的词法分析程序,要求实现如下功能。
(1)可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2)可以识别并跳过源程序中的注释。
(3)可以统计源程序中的语句行数、各类单词的个数、以及字符总数,并输出统计结果。
(4)检査源程序中存在的词法错误,并报告错误所在的位置。
(5)对源程序中出现的错误进行适当的恢复,使词法分析可以继续进行,对源程序进行一次扫描,即可检查并报告源程序中存在的所有词法错误。
实现要求:分别用以下两种方法实现。
方法1:采用C/C++作为实现语言,手工编写词法分析程序。
方法2:编写LEX源程序,利用LEX编译程序自动生成词法分析程序。
本次实验采用方法2实现。
实验过程:
打开虚拟机,打开Terminal,输入命令sudo apt-get install flex安装flex,flex能将.lex程序解释成lex.yy.c文件,再输入命令vim lex.l,开始编辑lex词法分析程序。
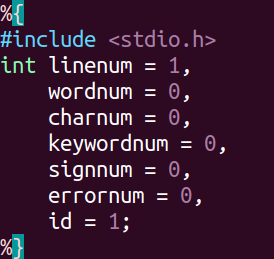
声明分两部分,第一部分由“%{”和“%}”包括起来,包含所引用的头文件,以及用到的全局变量。我用到的全局变量有:行号,单词数,字符数,关键字数,符号数,标识符号。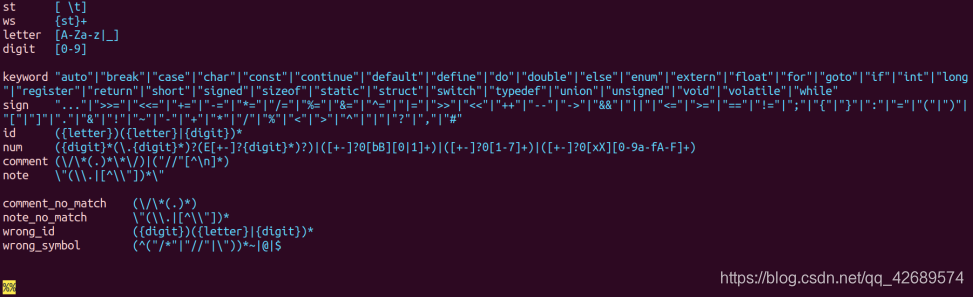
声明的第二部分定义词法分析程序要识别的标识符,常数,运算符,关键字,分隔符等单词符号,以及错误处理用到的模式,用正则表达式表示。需要注意:“include”,“define”不属于关键字。同时我也考虑了二进制数,八进制数,十六进制数的情况,将其归入num中。
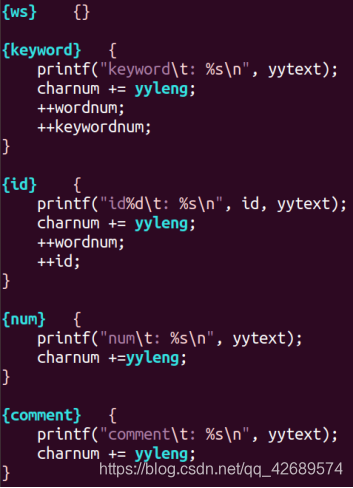
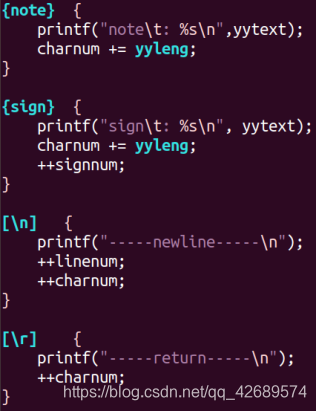
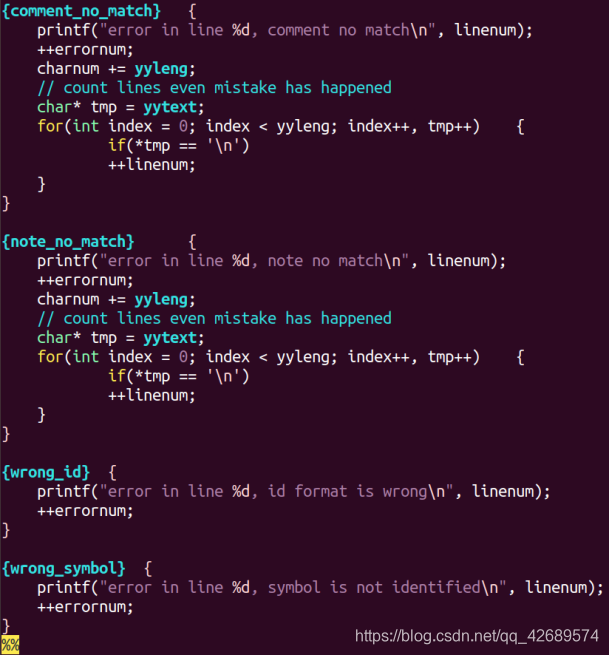
翻译规则部分,遇到一个单词,就在相应的统计变量加一,输出提示信息,同时考虑错误处理,我将错误分为四类:第一类是注释符不匹配,第二类是引号不匹配,第三类是标识符格式错误,第四类是在非注释、非引号部分出现“~@”等符号。第一类第二类错误发生了仍要计算行数。



辅助过程,定义主函数,要用到Lex提供的函数和变量,参考IBM推出的教程,这里介绍一下。主函数检查参数,调用yylex()函数分析源程序,并打印统计信息。
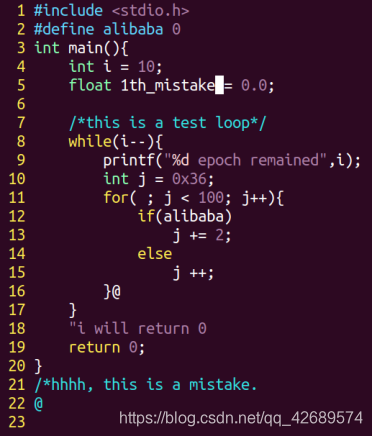
保存退出,输入命令vim test.c编写测试程序test.c
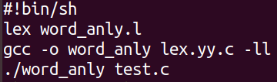
编写测试用的批处理文件show_res.sh,并输入命令sh show_res.sh运行
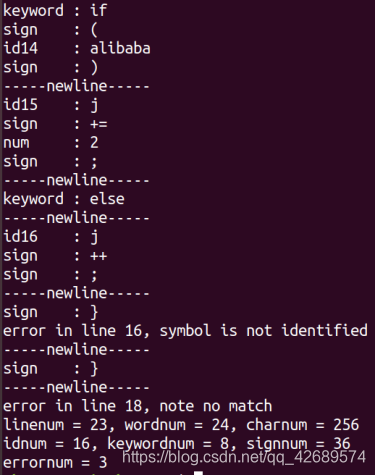
实验结果:
实验总结:
本次实验让我掌握了词法分析程序的设计与实现方法,感受到相比用C语言设计,lex程序设计更加便捷。在实验的过程中对C语言也有了更深入的了解。

















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









