



一、核心要点
- SensorFlow是一个新型的图像和传感器融合框架,用于稳健,高质量的视频稳定。
- 作者认为SensorFlow不仅能够纠正复杂动作的灵活性(帧内平滑),而且能够增强对传感器数据的鲁棒性(帧间连续)
- 主要框架:基于传感器的预稳定模块、基于遮挡和动态感知的光流补全、基于遮挡感知训练的3D卷积网络。
二、相关背景
Motivation
视频稳定通常遵循轨道平滑和扭曲的过程,track-smooth-and-warp。
- track阶段的motion估计很难达到可以用作视频稳定的标准
- warp阶段的 Grid-base 以及 dense per-pixel warp也都很难应对非刚性的视觉失真
基于视觉的视频稳定方法
-
核心优势:能够获取的数量更多且自由度更高的信息,比如利用图像构建像素级和语义级的重建损失。
-
核心挑战:如何解决运动估计算法中相机运动、深度、RSC和匹配错误导致的综合误差,而且由于运动跟踪和图像合成的局限性,难以对这些因素进行建模,并且极易出现局部失真的灾难性问题。
基于传感器的视频稳定方法:
-
核心优势:基于传感器的视频稳定方案仅利用传感器信号估计相机运动,比如 EIS 和 OIS ,这些信号与视频内容分离,可以避免视觉中的综合误差,从而使它们能够处理大尺度的动作。
-
核心挑战:通常仅限于旋转运动,并且传感器容易受到校准误差和环境因素(例如温度)的影响,可能会引起误差和漂移。
Contribution
本文提出了一条新型的视频稳定流程,该流程不仅借助传感器和视觉方案的优势,而且通过方案上的独特设计抵消了部分两种方案的劣势。
-
基于传感器的预稳定模块:通过传感器信息有效删除大型相机运动,同时在移除掉部分运动后,后续残余光流的滤波尺度就足够小,在运动区域和遮挡区域的运动平滑的压力就会变小,造成失真的可能性也就相应减小。
-
基于遮挡和动态感知的光流补全:提出一种新颖的遮挡掩码策略并且引入遮挡感知的损失,能够有效处理遮挡和动态对象。
-
基于遮挡感知训练的3D卷积网络:利用3D卷积结构,充分感知时域和空域的信息,能够有效补偿传感器引入的噪声和温漂,并且结合遮挡感知训练,有效处理遮挡和动态对象。
三、算法结构
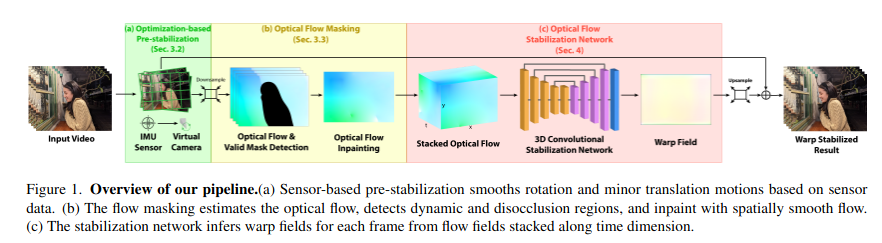
Optimization-based Pre-stabilization
问题描述:正常情况下,直接估计或平滑大尺度相机运动会引入相对更大的误差和视觉失真,所以预对齐部分对于大尺度运动平滑就比较重要,现在常用的方法大多以估计单应矩阵来实现预对齐的功能,但这种依赖视觉匹配的方式限制性比较大,在光流估计任务中,大多利用多尺度金字塔实现 coarse to fine 的预对齐 。
本文方法:利用IMU信息对输入图像进行局部视差的校正,可以在摆脱视觉限制并且不引入失真的情况下对运动进行平滑,可以有效处理大规模相机运动。
具体实现:根据陀螺仪和OIS的传感器数据提取相机旋转信息以及平移信息,并运行基于优化的算法以平滑大型旋转运动和小型转换运动
- 在角速度域限制0阶和1阶平滑
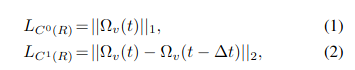
- offset的0阶和1阶平滑
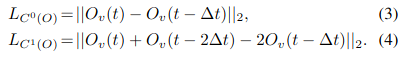
Optical Flow Masking Strategy
光流掩码策略的目的是检测任何可能在稳定结果中引入失真伪像的光流区域,包括遮挡和动态对象。
-
Flow cycle consistency
:检测非遮挡区域,对于遮挡像素点,在帧间追踪时物体消失,此时双向光流一致性的误差较大
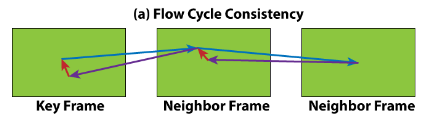
-
Fundamental matrix outlier
:检测运动区域,属于“静态背景”的像素应遵循满足相同基本矩阵的运动,无论其居住在哪个深度上。如果像素在任何估计的基本矩阵中都是异常值,那么像素将是无效的。
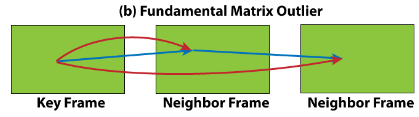
- Masking strategy Visualization

-
Optical Flow Inpainting:Laplacian region filling,通过强制执行每个像素值等于其四个相邻像素的平均值,可以保证无效区域的局部平滑度。
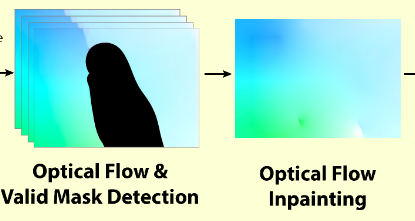
Optical Flow Stabilization Network
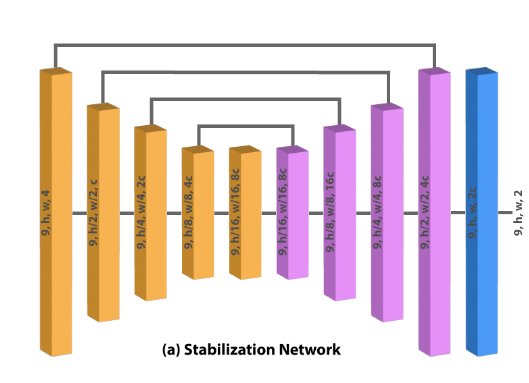
将时域堆叠与空域信息组合成 3D 结构,利用 3D 卷积和时空域损失约束的方式保证帧内的平滑性和帧间的连续性。
-
3D卷积提取时空域信息的方式之前也很常见,不过现在的研究更偏向于利用transforner的结构提取时域信息,例如VGGT。这里作者没有提到为何用3D CNN而非Transformer,并且作者提到过这篇论文的目的是高质量稳像效果而非实时。
Train Loss
- Motion loss
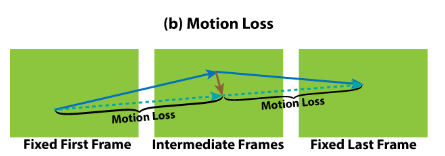
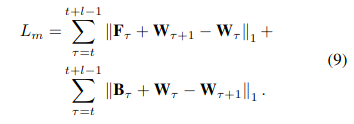
是
的光流,
是
的光流,
是网络输出的运动场
- Smoothness loss
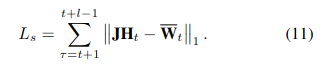
![]()
表示四个角点像素的运动,
表示线性插值的权重,
表示warp field
-
Occlusion-aware weight
![]()
![]()
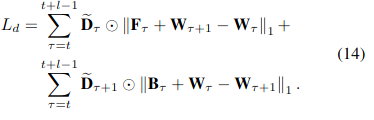
表示10*10的区域内标准差
-
Final Training loss
四、实验结果
与现有研究的对比:
-
基于光流的方法大多都会受遮挡问题导致局部失真
-
其余类型的非传统方法往往会因为稳定性不足导致异常的视觉缺陷

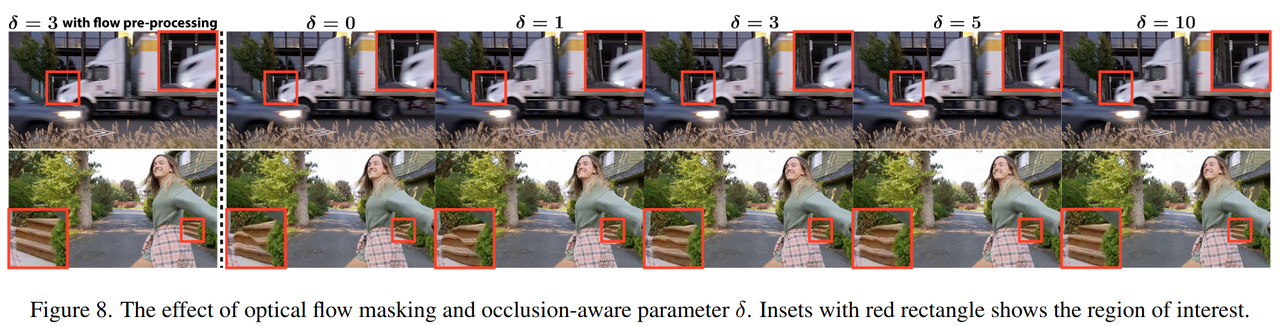
消融实验1:
-
验证了flow inpaint 和 Occlusion-aware Training
-
最左列显示了完整方案
-
虚线右侧则没有flow pre-process,并且显示遮挡参数的强度对稳定性和平滑性的影响
消融实验2:
-
系数的作用:用来平衡防抖效果和失真表现
-
Pipeline modules作用:体现了pre stabilization(Gyro only)与Flow mask and inpaint(Flow only)的效果

五、算法思考
局限性(Limitations)
-
本文方法需要光流作为输入,尽管现有的光流解决方案运行良好,但也引入了潜在的视觉伪像风险。
-
该模型从 2D warp field 纠正视差的能力仍然有限。理想情况下,可以通过适当的3D动态表示形式通过新型视图合成来完成稳定。
-
尽管这项工作着重于高质量的视频稳定,但可以通过进一步的性能优化来适应在线(甚至实时)稳定。
六、相关参考
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10944104&tag=1
论文发表:WACV 2025
评估代码:https://github.com/jiyangyu/sensorflow/tree/main

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









