




Motivation
-
现有的特征点检测和提取算法获取的描述符特征表达能力有限,难以适配一些变化域匹配的任务
-
现有特征匹配算法的匹配能力过于依赖特征点检测和提取获取的原始描述符特征的质量
OmniGlue Architecture
第一个以提高泛化能力为核心原理设计的可学习图像匹配器:引入DINOV2预训练模型,用来提取基础广泛且具有跨域表达能力的视觉特征,以此特征构建稀疏图神经网络,并在稀疏连接上用关键点位置计算注意力权重,一种新的角度分离位置信息和视觉信息的纠缠,并且降低对特征点检测和提取器的依赖,提高模型对不同域数据的泛化能力。
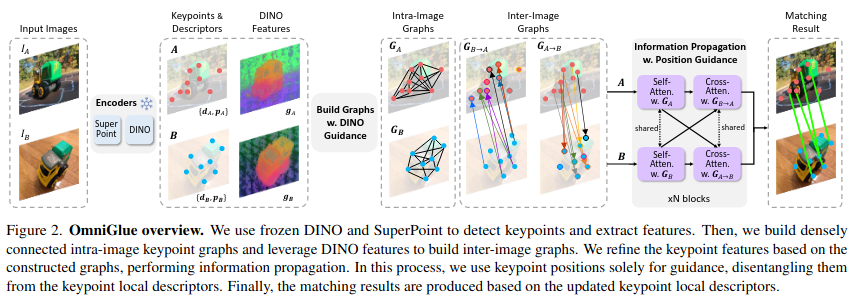
Encoders
引入DINOV2预训练模型,用来提取额外的基础广泛的视觉特征,具有跨域表达的能力,SuperPoint提取特征点和特征描述符。利用Superpoint获取的特征点位置对稠密特征图插值,得到特征点对应的DINO描述符
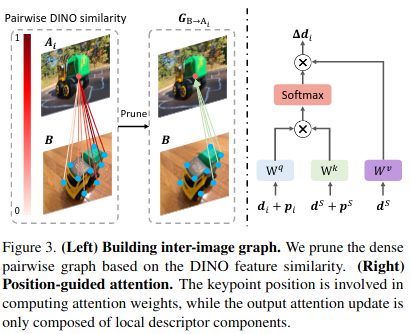
Build Graphs w. DINO Guidance
利用DINO描述符计算图内和图间的相似度矩阵,并选取top-half的有效连接构建图结构,图结构的稀疏化。
Information Propagation w. Position Guidance
利用关键点位置信息来构建有效连接内的注意力权重,指导信息传播过程。
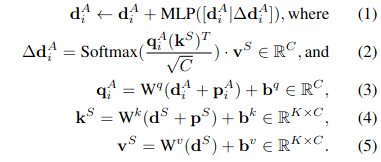
References
代码: https://github.com/google-research/omniglue
论文: https://arxiv.org/pdf/2405.12979
会议:CVPR 2024


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









