







 本文介绍了使用YOLOv5进行身份证分割任务的尝试,探讨了模型选择、训练过程、数据集处理和推理环节,强调了数据增强的重要性,并提出可加入更多类别和数据以优化掩膜生成。
本文介绍了使用YOLOv5进行身份证分割任务的尝试,探讨了模型选择、训练过程、数据集处理和推理环节,强调了数据增强的重要性,并提出可加入更多类别和数据以优化掩膜生成。
前情提要
基于yolo的分割训练yolo-segment
Yolo 都 已 经 v9 了 无所谓 这次用v5
是希望得到尽可能小的模型 完成检测识别分割任务 尝试了基于Unet的 HU-PageScan 模型小 但数据集小导致结果不如人意 后面选择了yolo-segment
各个版本的参数量对比 :
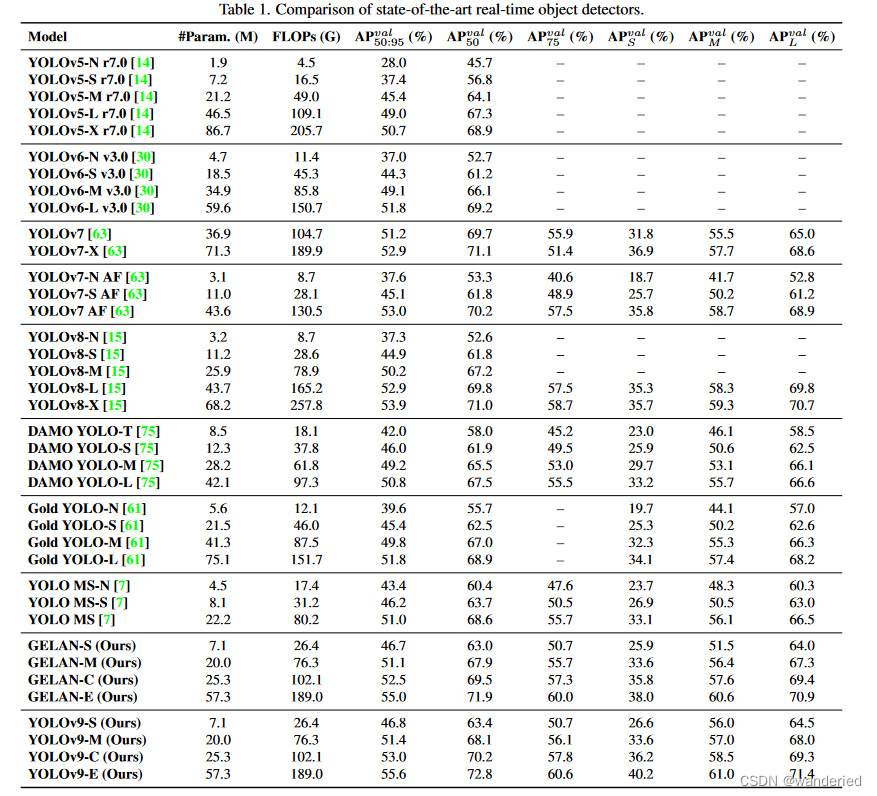
训练过程
仓库克隆
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -qr requirements.txt # install
克隆后装完依赖验证一下
import torch
import utils
display = utils.notebook_init() # checks
YOLOv5 2024-*-* Python-3.9.7 torch-1.10.0+cu113 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
Setup complete (** CPUs, *** GB RAM, 1***.**/3***.0 GB disk)
├───classify #分类
├───data #数据相关
│ ├───hyps #数据增强
│ ├───images #图片
├───models
│ ├───segment #分割用模型
├───runs #运行结果
├───segment #分割训练
├───utils #组件
│ ├───aws
│ ├───docker
│ ├───flask_rest_api
│ ├───google_app_engine
│ ├───loggers
│ ├───segment
数据集准备
data
├───images #数据图片
│ ├───test
│ ├───train
│ └───val
├───labels #数据标签
│ ├───test
│ ├───train
│ └───val
└───VOCTrainVal
├───Annotations
├───ImageSets
├───JPEGImages
└───YoloLabels
数据集转化
import json
import os
from xml.etree.ElementTree import Element, SubElement, ElementTree, tostring
from xml.dom.minidom import parseString
def points_to_bndbox(points):
xs = [point[0] for point in points]
ys = [point[1] for point in points]
return min(xs), min(ys), max(xs), max(ys)
def json_to_xml(json_object, xml_file_path):
annotation = Element('annotation')
# 添加图片尺寸
size = SubElement(annotation, 'size')
width = SubElement(size, 'width')
width.text = str(json_object['imageWidth'])
height = SubElement(size, 'height')
height.text = str(json_object['imageHeight'])
for obj in json_object['shapes']:
object_elem = SubElement(annotation, 'object')
name = SubElement(object_elem, 'name')
name.text = obj['label']
bndbox = SubElement(object_elem, 'bndbox')
xmin, ymin, xmax, ymax = points_to_bndbox(obj['points'])
x1, y1= obj['points'][0]
x2, y2= obj['points'][1]
x3, y3= obj['points'][2]
x4, y4= obj['points'][3]
SubElement(bndbox, 'xmin').text = str(xmin)
SubElement(bndbox, 'ymin').text = str(ymin)
SubElement(bndbox, 'xmax').text = str(xmax)
SubElement(bndbox, 'ymax').text = str(ymax)
SubElement(bndbox, 'x1').text = str(x1)
SubElement(bndbox, 'y1').text = str(y1)
SubElement(bndbox, 'x2').text = str(x2)
SubElement(bndbox, 'y2').text = str(y2)
SubElement(bndbox, 'x3').text = str(x3)
SubElement(bndbox, 'y3').text = str(y3)
SubElement(bndbox, 'x4').text = str(x4)
SubElement(bndbox, 'y4').text = str(y4)
SubElement(bndbox, 'width').text = str(json_object['imageWidth'])
SubElement(bndbox, 'height').text = str(json_object['imageHeight'])
# 生成美化后的XML字符串
rough_string = tostring(annotation, 'utf-8')
reparsed = parseString(rough_string)
pretty_xml_as_string = reparsed.toprettyxml(indent=" ")
# 保存美化后的XML到文件
with open(xml_file_path, 'w') as xml_file:
xml_file.write(pretty_xml_as_string)
source_folder = 'VOCard/VOCTrainval/Annotation'
des 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 50
50

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









