







测试案例:
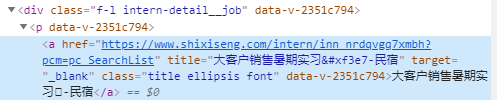
1.select方法
for item in soup.select('div[class="f-l intern-detail__job"] p a'):
detail_url = item.get('href')
print(detail_url)
2.find_all 方法
for items in soup.find_all('div',class_='f-l intern-detail__job'):
item = items.select('p a')[0]
detail_url = item.get('href')
print(detail_url)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









