




 本文介绍了如何使用Spring Data JPA整合JPA和Hibernate,通过简化ORM操作、自定义Repository和高级查询技巧,提升开发效率。涵盖了配置、映射、关系管理、分页排序和复杂查询等内容。
本文介绍了如何使用Spring Data JPA整合JPA和Hibernate,通过简化ORM操作、自定义Repository和高级查询技巧,提升开发效率。涵盖了配置、映射、关系管理、分页排序和复杂查询等内容。
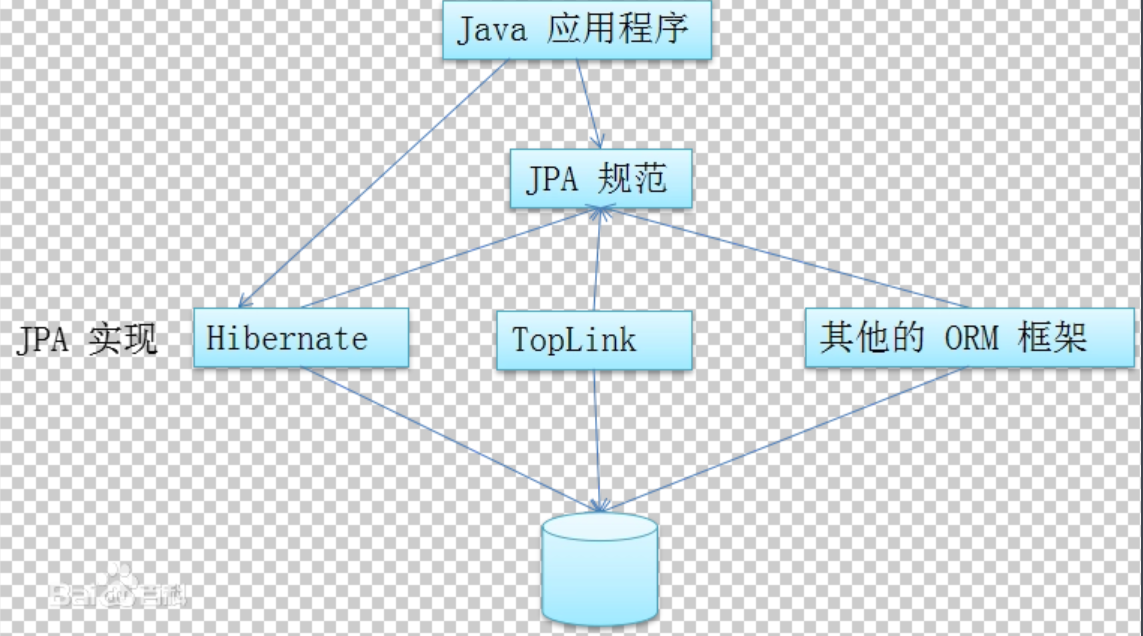
Spring-data-jpa
1.介绍
从理论上来说,Mybatis 和 Hibernate 并非同一类框架:Mybatis 是半自动 ORM 框架,而 Hibernate 是
全自动的。而从全自动 ORM 框架的角度来将,Hibernate 也非唯一的一个,跟它同类的竞争对手还有:
TopLink、JDO 等(虽然市场占有率十分低) 。
不同的全自动 ORM 框架(这里并不包括 Mybatis)之间,功能是是相似的,但是 API 接口的区别十分大。不
便于项目在底层技术实现之间迁移。
JPA(Java Persistence API)是 Sun 官方提出的 Java 持久化规范。它的出现主要是为了简化现有的持
久化开发工作和整合 ORM 技术,提供统一的 API 接口,结束现在 Hibernate、TopLink、JDO 等 ORM 框
架各自为营的局面。
2.如何使用
2.1 使用方式
-
直接使用 Hibernate 。
-
直接使用 JPA ,间接使用 Hibernate;
-
通过 spring-data-jpa ,将 JPA( 和 Hibernate )整合进 Spring 项目,以一种特定的方式( sprig data )使用 JPA ,从而间接使用 Hibernate 。
2.2 使用步骤
2.2.1 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
2.2.2 添加配置文件
server.port=8080
spring.application.name=spring-data-jpa-demo
## datasource
spring.datasource.name=defaultDataSource
spring.datasource.url=jdbc:mysql://localhost:3306/scott?serverTimezone=UTC
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=123456
## jpa
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.properties.hibernate.hbm2ddl.auto=update
## log
logging.level.root=INFO
logging.level.com.woniu=DEBUG
logging.pattern.console=%clr(%5level) \
%clr(|){faint} \
%clr(%-40.40logger{39}){cyan} \
%clr(:){faint} \
%m%n
配置说明
update 对数据库表结构的『更新』仅限于:
根据 Model 创建一个原本不存在的 Table;
为已存在的 Table『新增』列。
不包括
修改已有列的数据类型;
新增或修改已有列的约束条件;
删除 Table 的某列。
2.2.3 开启 JPA框架
在某个配置类(或入口类)上加上 @EnableJpaRepositories(basePackages = "xxx.yyy.zzz.dao") 注解(非必须,springboot也会扫描)。
2.2.4 实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "employee", schema = "scott")
public class EmployeePo {
@Id @Column(name = "id") private Long id;
@Basic @Column(name = "name") private String name;
@Basic @Column(name = "job") private String job;
@Basic @Column(name = "manager_id") private Long managerId;
@Basic @Column(name = "hire_date") private Date hireDate;
@Basic @Column(name = "salary") private Integer salary;
@Basic @Column(name = "commission") private Integer commission;
@Basic @Column(name = "department_id") private Long departmentId; // 外键列(department_id)没有演变,直接"对应"出来的一个"简单"属性。
// @ManyToOne // 标识它是一个非 @Id、非 @Basic 的属性,而是 "多对一关系" 中的 "多方" 属性
// @JoinColumn(name = "department_id") // "我" 这个属性对应的是数据库中 employee 表中的 department_id 列。
// private DepartmentPo department; // 外键列(department_id)演变出来的一个"引用"属性
/*
什么都不写,等同于写了 @Basic @Column(name = "...")
所以,要忽略就必须要写 @Transient,不能什么都不写。
*/
@Transient
private Long xxx;
// dao.save(po);
}
注解介绍
@Entity(name="EntityName") 必须
用来标注一个数据库对应的实体,数据库中创建的表名默认和类名一致。其中,name 为可选,对应数据
库中一个表,使用此注解标记 JavaBean 是一个 JPA 实体。
@Table(name="", catalog="", schema="") 可选
用来标注一个数据库对应的实体,数据库中创建的表名默认和类名一致。通常和 @Entity 配合使用,只
能标注在实体的 class 定义处,表示实体对应的数据库表的信息。
在数据库理论领域中,DBMS - Catalog - Schema - Table 是四级概念,但不是所有的数据库系统都支
持这四级。MySql 就不支持其中的 catalog ,而 schema 就是 mysql 中的 database 。
@Id 必须
@Id 定义了映射到数据库表的主键的属性,一个实体只能有一个属性被映射为主键。
@GeneratedValue(strategy=GenerationType, generator="") 可选
strategy:表示主键生成策略,有 AUTO、INDENTITY、SEQUENCE 和 TABLE 4 种。
generator:表示主键生成器的名称。
@Column(name="user_code", nullable=false, length=32) 可选
@Column 描述了数据库表中该字段的详细定义,这对于根据 JPA 注解生成数据库表结构的工具。
name:表示数据库表中该字段的名称,默认情形属性名称一致;
nullable:表示该字段是否允许为 null,默认为 true;
unique:表示该字段是否是唯一标识,默认为 false;
length:表示该字段的大小,仅对 String 类型的字段有效。
@Transient 可选
@Transient 表示该属性并非一个到数据库表的字段的映射,ORM 框架将忽略该属性。
除此之外,还有其它一些注解,不过出现频次会更低一些。
这些标注于属性上的注解,也可以标注在属性的 get 方法上。注意,不是/不用标注在 set 方法上。
UUID 和 ASSIGNED 主键策略
通常 JPA『背后』是 Hibernate,而 Hibernate 除了和上述的一样的 identity、sequence 主键生成策略
之外,还有 uuid 和 assigend 两种主键生成策略。
在 JPA 中使用 Hibernate 的 uuid 和 assigend 策略,需要『多』使用一个注解:@GenericGenerator
。
strategy = "identity":
@Id
@GeneratedValue(generator = "xxx")
@GenericGenerator(name = "xxx", strategy = "identity")
// @GeneratedValue(strategy = GenerationType.IDENTITY) 这是上面写法的简写
private Integer id;
表名数据库中的Id为自增长,当我们增加一行数据时id可以为null
strategy = "uuid":
@Id
@GeneratedValue(generator = "zzz")
@GenericGenerator(name = "zzz", strategy = "uuid")
private String id;
jpa 拦截程序给数据发送增加数据请求时将id设置为uuid
strategy = "assigned":
@Id
@GeneratedValue(generator = "zzz")
@GenericGenerator(name = "zzz", strategy = "assigned")
private Long id;
这边数据库和jpa都不管id的数据,由程序自己进行设定
Repository 构建
[^]: 如果要在 JUnit 中测试 Repository,记得使用 @Transactionl 注解。否则会报no session 的错。
自定义的 Repository 只要继承 JpaRepository 即可,就会帮我们自动生成很多内置方法。这是 spring
data-jpa 为我们带来的便利!
父接口 JpaRepository 要求传入 2 个泛型参数:
第一个泛型参数:是自定义的 Repository 所操作的 @Entity ;
第二个泛型参数:是 Entity 的 @Id 属性类型。
/*
1. 引包
2. @Enable... 注解激活使用 JPA + 包扫描
3. 写 PO 类,加注解
4. 写 Dao 接口,继承 JpaRepository
*/
@Repository
public interface DepartmentDao extends JpaRepository<DepartmentPo, Long> {
List<DepartmentPo> findAllByNameEquals(String name);
}
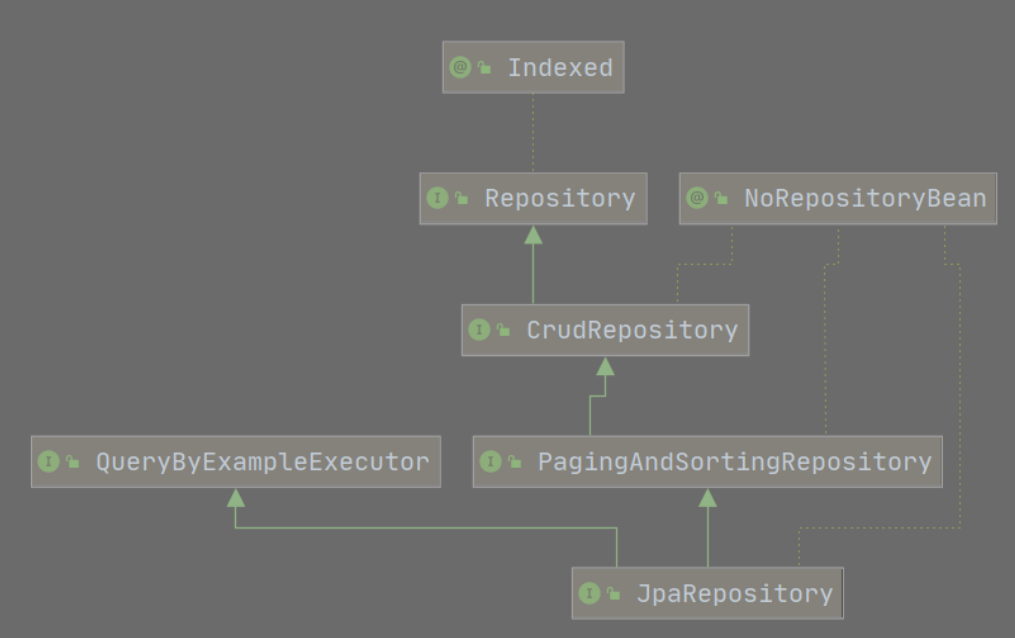
JpaRepository 继承 PagingAndSortingRepository 和 QueryByExampleExecutor。PagingAndSortingRepository 又继承了 CrudRepository 。
| 祖先 | 作用 |
|---|---|
| CrudRepository | 内置了我们最常用的增、删、改、查的方法。 |
| PagingAndSortingRepository | 在 CrudRepository 基础上负责排序和分页 |
| QueryByExampleExecutor | 提供了很多示例的查询方法。 |
因此使用 JPA 操作数据库时,只需要构建的 Repository 继承了 JpaRepository,就会拥有了很多常用的数据库操作方法。常用的方法有:
增/改操作
repository.save(entity);
添加和修改功能都是使用 .save() 方法。
有一点需要注意的是,对于修改而言,要先执行查询,再对查询到的 Entity 进行修改,而后再调用.save() 方法。
删操作
repository.delete(entity);
repository.deleteById(id);
删除常见两种:先执行查询,再对查询到的 Entity 调用 .delete 方法进行删除;另一种是直接提供
Entity 的 ID 进行删除。
简单查询操作
repository.getOne(id);
repository.findById(id);
repository.findAll();
.getOne() 和 findById() 都是根据 ID 进行查询。区别在于:查不到时,.getOne() 抛出EntityNotFoundException 异常,而 .findById() 查不查得到都是返回 Optional<> 。
在 Repository 的继承体系中 QueryByExampleExecutor 提供了通过 Example 对象进行条件查询。不
过,它用起来还是相对比较繁琐,因此,通常使用的是其它方案来实现各种条件查询。这也是
spring-data-jpa 对 JPA 的改进之处。
自定义简单的条件查询
spring-data-jap 还有一个功能非常实用:可以根据方法名自动生产 SQL。比如 .findByUserName() 会自动
生产一个以 userName 为参数的查询方法。只需要在我们自定义的 Repository 中创建好方法,使用的时候
直接将接口注入到类中调用即可。
根据用户名查询用户:
User findByUserName(String userName);
也可以加一些关键字 And、or:
User findByUserNameOrEmail(String username, String email);
修改、删除、统计也是类似语法:
Long deleteByUserName(String userName);
Long countByUserName(String userName);
基本上 SQL 体系中的关键词都可以使用,如 LIKE 、IgnoreCase、OrderBy:
List<User> findByEmailLike(String email);
User findByUserNameIgnoreCase(String userName);
List<User> findByUserNameOrderByEmailDesc(String email);
可以根据查询的条件不断地添加和拼接,Spring Boot 都可以正确解析和执行,其他使用示例例可以参考下表。
具体的关键字,使用方法和生产成 SQL 如下表所示
-tx-
| Keyword | Sample | JPQL snippet |
| :- | :- | :- |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstnameIs | … where x.firstname = ?1 |
| | findByFirstnameEquals | |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound
with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with
prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound
wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
2.2.5 关系映射
被省略掉的默认设置
由于 JPA 的默认设置在起作用,我们之前对 @Entity 中的属性的设置,『有些注解被省略掉了』。
-
与主键列对应的属性,除了使用 @Id 注解,还要使用 @Column 注解。( @GeneratedValue 注解的作用是另 一码事,和我们这里说的无关 )
-
与其它列对应的属性,除了使用 @Basic 注解,还要使用 @Column 注解。
完整的形式应该如下:
@Entity
@Table(name = "department", schema = "scott")
public class Department {
@Id @Column
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Basic @Column
private String name;
@Basic @Column
private String location;
// getter / setter
}
这里『默认』的规则如下:
-
Entity 的属性默认就是 @Basic 。因此,逻辑上是 @Basic 的属性头上的 @Basic 就都可以省略。不是@Basic 的属性,例如 @Id ,自然就要明确标明 @Id 。
-
如果属性名和列名是一致的,或只是驼峰命名法和下划线命名法这种命名风格的差异,那么,@Column注解可以省略。反而言之,@Column 注解只有在双方命名不一致的情况下,才会出来干活。
一对多关系映射/配置
这里有个概念可以便于理解和记忆以下配置:JoinColumn 指的就是外键列,只不过一个是编程领域中的叫法,一个是数据库领域中的叫法。@JoinColumn 的 name 自然就是外键列的列名。
如果没有映射成『引用』关系,那么 Entity 中的与外键列对应的属性,使用的注解自然就是 @Basic + @Column 。例如:
@Basic @Column
private Integer departmentId;
当 Integer departmentId 属性要衍变为 Department department 属性时,自然不再适合使用 @Basic +
@Column 注解。
在一对多的关系中:
-
@ManyToOne 是用在多方( 例如员工、学生 )的属性上;
-
@OneToMany 是用在一方( 例如部门、老师 )的属性上。
需要注意的是,@ManyToOne 和 @OneToMany 两个注解并非必须成对出现,只有在双向的关系中,一方和多方需要互相引用对象时,才会成对出现。
一般而言,如非必要,尽量不要使用双向关系。如果只是单向的关系,通常只是对多方使用
@ManyToOne 。
从多方出发的单向映射
Employee 类(多方)
@ManyToOne
@JoinColumn(name = "department_id") // 外键列列名字
private Department department;
从一方出发的单向映射
Department 类(单方)
@OneToMany
@JoinColumn(name = "department_id") // 外键列列名字
private List<Employee> employeeList;
无论是从多方出发的单向映射,还是从一方触发的单向映射,它们用到的 @JoinColumn 都是一样的。
双向映射
Employee 类(多方)
@ManyToOne
@JoinColumn(name = "department_id") // 外键列列名字
private Department department;
Department 类(单方)
@OneToMany(mappedBy = "department") // 对应对端的相关属性名。
private Set<Employee> employeeSet; // 可以使用 List
如果是双向关系的话,主表方/一方使用 @OneToMany 注解的 mappedBy 属性。
双向映射的通用形式:
多方/从表方 : Employee {
...
@ManyToOne
@JoinColumn(
name = "<外键列 name,这一列肯定是在从表中>",
referencedColumnName="<与外键列『挂钩』的列的 name,这一列肯定是在主表中的,通常是主 表的主键列>"
)
private Department department;
}
一方/主表方 : Department {
...
@OneToMany(mappedBy="对端对应的属性的 name,就是标注了 @ManyToOne 的那个属性")
private Set<Employee> employeeSet;
}
一对多双向关系的注意事项
再次强调,如无必要,尽量不要使用双向关系,以避免以下问题。
在『多方』 @ManyToOne 中要使用 FetchType.LAZY 延迟加载,否则会导致性能降低(1 + N 问题)。
class Employee { ...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "department_id")
private Department department;
}
『一方』中要增加了 2 个方法,.addXxx() 和 .removeXxx() 。
class Department { ...
public void addEmployee(Employee employee) {
if (employeeSet.contains(employee))
return;
employeeSet.add(employee);
employee.setDepartment(this);
}
public void removeEmployee(Employee employee) {
if (!employeeSet.contains(employee))
return;
employeeSet.remove(employee);
employee.setDepartment(null);
}
}
『多方』中的 .setXxx() 方法要重新设计。
class Employee { ...
public void setDepartment(Department department) {
if (this.department == department)
return;
if (this.department != null)
this.department.removeEmployee(this);
this.department = department;
if (department != null)
department.addEmployee(this);
}
}
在使用 JSON 来序列化对象或生成默认的 toString() 方法时,会产生无限递归(Infinite recursion)问题:StackOverFlow 。
再次强调一点,最理想的情况应该是「有向无环」。如非必要,尽量不要使用双向关系。因为一不小心容易出现逻辑错误。
多对多关系映射/配置
这里有个无关的小问题,由于下面的例子中使用到的素材里有个表名为 order,这与数据库关键字冲突,因此为了『告知』Hibernate/JPA 在『帮』我们执行 SQL 语句时要为它加返单引号,因此在 Entity 的@Table 中做一点小改动:
@Table(name = "`order`") // 这里加上了反单引号
如果充分理解 @ManyToOne ,那么接下来理解多对多关系中的 @ManyToMany 就很容易。
Order 类:
@ManyToMany
@JoinTable(name = "orderitem", // 指定中间表
joinColumns = {@JoinColumn( // 『我』(Order)是如何和中间表关联
name = "order_id", // 中间表中的对应我的主键列的外键列
referencedColumnName = "id") // 『我』的主键列
},
inverseJoinColumns = {@JoinColumn( // 『我的对端』(Product)是如何和中间表关联
name = "prod_id", // 中间表中的对应我的对端的主键列的外键列
referencedColumnName = "id") // 『我的对端』的主键列
}
)
private Set<Product> productSet;
由于多对多的关系中,外键列 是在中间表中(A B 并没有对方的外键列),因此 @JoinColumn 自然是出现在 @JoinTable 『里面』的。并且,@JoinColumn 的 name 指的就是外键列的列名。
Product 类
@ManyToMany(mappedBy = "productSet") // 对端的对应属性名
private Set<Order> orderSet;
一对多双向关系中需要关注的那几点,在多对多双向关系中一样也要关注!
通用形式:
A方 : Order {
...
@ManyToMany
@JoinTable(name="<中间表 name>",
joinColumns = { // 配置『我』(A方)与中间表的关系
@JoinColumn( name = "中间表中A方的外键列name", referencedColumnName = "A方表中与之对应的列的name(通常就是A方的主键 列)" ) }
inverseJoinColumns = { // 配置『对方』(B方)与中间表的关系
@JoinColumn( name = "中间表中B方的外键列name", referencedColumnName = "B方表中与之对应的列的name(通常就是B方的主键 列)" ) } )
private Set<Product> productSet; }
B方 : Product {
...
@ManyToMany(mappedBy="对方用上了@ManyToMany和@JoinTable写了一大坨配置的那个属性的name")
private Set<Order> orderSet;
}
一对一关系映射/配置
class Product { // 主表
...
@OneToOne(mappedBy="product")
private Productnote productnote;
}
class Productnote {
...
@OneToOne(optional = false)
@JoinColumn(name = "prod_id") // 外键列
private Product product;
...
}
上面用到的 optional 并非必须,这里只是故意显示其作用。optional 的默认值为 true,在 @ManyToOne 和 @ManyToMany 中也可使用。
当 optional 的属性值为 true 时,Hibernate/JPA 执行的是内连(inner join)查询,因此 product 属性值必定为 null 。为 false 时,Hibernate/JPA 执行的是左外连接(left join)查询,因此 product属性的值有可能为 null (是否真为 null,取决于数据库的实际情况)。
通用形式
主表 : Product {
...
@OneToOne(mappedBy="<从表方用上了 @OneToOne 和 @JoinColumn 的那个属性的name>")
private ProductNode node;
}
从表 : ProductNote {
...
@OneToOne
@JoinColumn( name="<外键列 name,这一列肯定是在从表中的>",
referencedColumnName="<与外键列『挂钩』的列 name,这一列肯定是在主表中的,通常是 主键列>")
private Product product;
}
分页和排序
Spring Data JPA 已经帮我们内置了分页功能,在查询的方法中,需要传入参数 Pageable,当查询中有多个参数的时候 Pageable 建议『作为最后一个参数传入』。
Slice<EmployeePo> findAllBySalaryGreaterThanEqualAndSalaryIsLessThan(int lowSalary, int highSalary, Pageable pageable);
具有分页功能的方法会返回一个 Page<T> 对象,其中封装了与分页有关的相关信息,及其所获取的数据。
Pageable 是 Spring 封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则,Page 是Spring 封装的分页对象,封装了总页数、分页数据等。返回对象除使用 Page 外,还可以使用 Slice 作为返回值。
Page 和 Slice 的区别如下:
-
Page 接口继承自 Slice 接口,而 Slice 继承自 Iterable 接口。
-
Page 接口扩展了 Slice 接口,添加了获取总页数和元素总数量的方法,因此,返回 Page 接口时,必须执行两条 SQL,一条复杂查询分页数据,另一条负责统计数据数量。
-
返回 Slice 结果时,查询的 SQL 只会有查询分页数据这一条,不统计数据数量。
-
用途不一样:Slice 不需要知道总页数、总数据量,只需要知道是否有下一页、上一页,是否是首页、尾页等,比如前端滑动加载一页可用;而 Page 知道总页数、总数据量,可以用于展示具体的页数信息,比如后台分页查询。
@Test
public void testPageQuery() {
int page=1, size=2;
Sort sort = new Sort(Sort.Direction.DESC, "id"); // 排序
Pageable pageable = PageRequest.of(page, size, sort);
userRepository.findALL(pageable);
userRepository.findByNickName("aa", pageable);
}
-
Sort,控制分页数据的排序,可以选择升序和降序。
-
PageRequest,控制分页的辅助类,可以设置页码、每页的数据条数、排序等。
limit 限制查询
有时候我们只需要查询前 N 个元素,或者只取前一个实体。
// order by salary
List<Employee> findFirstByOrderBySalary();
// order by salary desc limit 2
List<Employee> findFirst2ByOrderBySalaryDesc();
// where job = ? order by salary desc limit 2
List<Employee> findFirst2ByJobEqualsOrderBySalaryDesc(String job);
复杂查询:**@Query** 查询
不常用,仅作了解。
使用 Spring Data 大部分的 SQL 都可以根据方法名定义的方式来实现,但是由于某些原因必须使用自定义的 SQL 来查询,Spring Data 也可以完美支持。
在 SQL 的查询方法上面使用 @Query 注解,在注解内写 Hql 来查询内容。
@Query("select e from Employee e where e.job = ?1")
List<Employee> xxx(String job);
@Query("select e from Employee e where e.job = :hello")
Page<Employee> yyy(@Param("hello") String job, Pageable pageable);
//当然如果感觉使用原生 SQL 更习惯,它也是支持的,需要再添加一个参数 nativeQuery = true 。
@Query(value = "select * from employee where job = ?1", nativeQuery = true)
Page<Employee> zzz(String job, Pageable pageable);
复杂查询:多表关联查询
多表查询在 Spring Data JPA 中有 2 种实现方式:
-
利用 Hibernate 的级联查询来实现;
-
创建一个结果集的接口来接收连表查询后的结果。
定义一个结果集的"接口",接口的内容来自于员工表和部门表。
public interface EmployeeInfo {
Integer getId();
String getName();
String getJob();
Integer getSalary();
Integer getDepartmentId();
String getDepartmentName();
String getDepartmentLocation();
}
在运行中 Spring 会给接口(EmployeeInfo)自动生产一个代理类来接收返回的结果,代码中使用getXXX() 的形式来获取。
在 EmployeeRepository 中添加查询的方法,返回类型设置为 UserInfo :
@Query(value = "select e.id as id," +
" e.name as name," +
" e.job as job," +
" e.salary as salary," +
" e.departmentId as departmentId," +
" d.name as departmentName," +
" d.location as departmentLocation" +
" from Employee e, Department d" +
" where e.departmentId = d.id and e.job = ?1")
List<EmployeeInfo> findEmployeeInfo(String job);
这里的查询语句是 HQL 而是不是 SQL ,需要写类的名和属性,这块很容易出错。
因为是非级联查询方案,所以这里 Employee 表和 Department 表没有、不需要使用 @ManyToOne的配置。
JpaSpecificationExecutor 查询
我们可以通过 AND 或者 OR 等连接词来不断拼接属性来构建多条件查询,但如果参数大于 6 个时,方法名就会变得非常的长,并且还不能解决动态多条件查询的场景。到这里就需要给大家介绍另外一个利器JpaSpecificationExecutor 了。
JpaSpecificationExecutor 是 JPA 2.0 提供的 Criteria API 的使用封装,可以用于动态生成 Query 来满足我们业务中的各种复杂场景。我们只需要为我们的自定义接口多继承一个父接口:JpaSpecificationExecutor 。
-
我们的自定义的接口多继承了 JpaSpecificationExecutor 后,我们的接口中自然就『多』出来一些入参为 Specification 类型的方法。
-
Specification 是一个接口,其中的 toPredicate 方法的返回值 Predicate 对象就代表着查询条件。
-
简单来说,我们要去实现 Specification 接口,并通过实现它的 toPredicate 方法返回一个 Predicate对象。JpaSpecificationExecutor 需要这个 Predicate 对象来执行查询操作。
在使用 JpaSpecificationExecutor 构建复杂查询场景之前,我们需要了解几个概念:
| 概念 | 说明 |
|---|---|
| Root<T> root | 代表了可以查询和操作的实体对象的根,可以通过 get("属性名") 来获取对应的值。 |
| CriteriaQuery<?> query | 代表一个 specific 的顶层查询对象,它包含着查询的各个部分,比如 select 、from、where、group by、order by 等。 |
| CriteriaBuilder cb | 来构建 CritiaQuery 的构建器器对象,其实就相当于条件或者是条件组合,并以 Predicate 的形式返回。 |
使用案例
-
为 EmployeeRepository『多』添加接口:
@Repository public interface EmployeeRepository extends JpaRepository<Employee, Integer>, JpaSpecificationExecutor<Employee> { ... }
-
在 Service( 或 Junit )中使用 JpaSpecificationExecutor 的具体使用。
// 1. Specification 的 toPredicate() 方法返回的 Predicate 对象负责描述『要找的人的标准』。 Specification<Employee> specification = new Specification() { @Override public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder) { Predicate predicate1 = criteriaBuilder.equal(root.get("job"), "SALESMAN"); Predicate predicate2 = criteriaBuilder.greaterThan(root.get("salary"), 1000); Predicate predicate3 = criteriaBuilder.equal(root.get("job"), "MANAGER"); Predicate predicate4 = criteriaBuilder.lessThan(root.get("salary"), 25000); Predicate predicate5 = criteriaBuilder.like(root.get("name"), "A%"); /* * where (job = 'SALESMAN' and salary > 1000) * or (job = 'MANAGER' and sal < 2500) * or name like 'A%' */ return criteriaBuilder.or( criteriaBuilder.and(predicate1, predicate2), criteriaBuilder.and(predicate3, predicate4), predicate5 ); } }; // 2. findAll() 负责干『找人』这个活。 List<Employee> list = repository.findAll(specification); list.forEach(System.out::println);
JpaSpecificationExecutor 接口中的方法也支持分页和排序等功能。
@Entity 对象转 JSON 时的一个异常
在 RESTful 风格的项目中,当 Web 层将 Service 层返回的 Entity 对象转换成 JSON 格式字符串时,有可能会报如下错误:
直接分析原因的话,是因为 jackson 库在将 Entity 序列化为 JSON 格式字符串时,发现其中有一个名为"hibernateLazyInitializer" 的属性值为 null 。这种情况下,jackson 不知道该如何处理这个属性,因此它就抛出异常报错。
但是,问题是我们的 Entity 中好似并没有名为 "hibernateLazyInitializer" 属性!
这里的关键还是也延迟加载有关。实际上 Hibernate 并未真的去直接使用我们的 Entity ,而是基于代理思想,去创建并使用了 Entity 的代理对象。从 Service 层返回到 Web 层的并不是真正的 Entity 对象,而是 Entity 的代理对象。
Entity 的代理对象中有这个 "hibernateLazyInitializer" 属性!
解决掉这个异常有 3 种办法:
-
Web 层不要对外返回 @Entity 对象,返回DTO对象。
这样,在为 DTO 对象 set 属性值时,你已经从 @Entity 对象中 get 到了值,然后才发生 jackson 将
DTO 对象转为 json-string 。这里自然就完美避过 hibernateLazyInitializer 的问题。
-
在 Entity 的头上标注 @JsonIgnoreProperties(value={"hibernateLazyInitializer"})。
实际上就是在告诉 jackson,去序列化 Entity 时忽略调其中的 hibernateLazyInitializer 属性。
-
在 Spring Boot 配置文件中配置 spring.jackson.serialization.FAIL_ON_EMPTY_BEANS=false 。
这是在告诉 jackson,去序列化对象时,如果遇到为 null 的属性不要抛出异常,而是继续序列化。
这种情况下,Web 层返回给前端的 JSON 数据中会多一项:hibernateLazyInitializer="" ,数据的接收方可
能会觉得奇怪。
建议使用第一或者第二种方法
3.总结
通过几天的使用,jpa给人的感觉就是完全不需要写sql语句,而在进行数据更改时有更高级的双向更新功能,虽然需要我们手动写绑定方法,但是写完过后的感觉就是更改了一个其他关联的数据也进行了更改,明显更符合人的思维,如在双向绑定中,部门和员工的关系,当一个员工从一个部门调到另一个部门时,两个部门的数据也进行了更改,最后直接更新员工信息就好了,相当的方便,而且在后面的查询中我们也发现当我们通过员工查部门信息时,用jpa和mybatis查完全是两个东西,jpa查两个相同部门的员工得到的部门对象是引用同一个地址,当我们修改部门信息时,两个员工的部门信息都将得到更新,而mybatis就是完全新创建了两个部门对象,感觉jpa的设计更为高级一些;
4.jpa的多表查询不够方便的解决方法
可以在查询时使用spring-jdbc进行复杂的关联查询,简单的还是可以用jpa,毕竟jdbcTemplate在使用spring时就被创建在ioc容器中了,方法中直接注入就可以使用了,也比较方便

















 2788
2788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









