




-
强化学习解决什么问题
⼀句话概括强化学习能解决的问题:序贯决策问题。 -
强化学习如何解决问题,和监督学习的区别
与之相对的是监督学习,监督学习解决的是智能感知的问题。比如手写体数字识别,通过多样化的标签数据来训练智能体,让智能体学习到输入样本的抽象特征并分类。
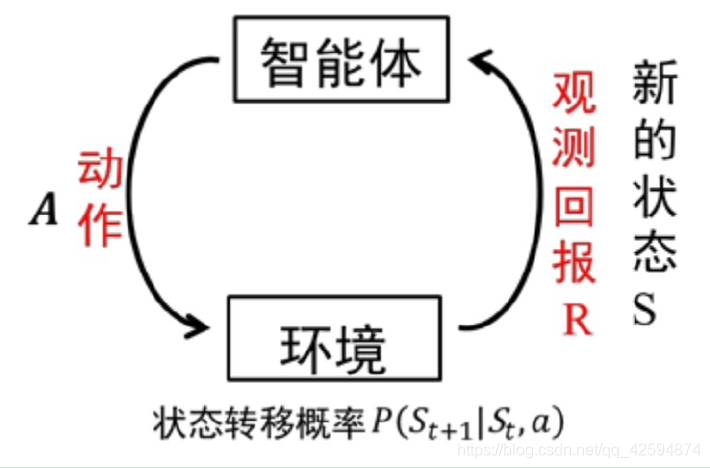
强化学习要解决序贯决策问题,不关心输入长什么样,只关心当前状态下应该采取什么动作才能实现最终的目标,即让整个任务序列达到最优。智能体通过动作和环境交互,环境返给智能体当前状态的回报,智能体根据回报评估采取的动作:有利于实现目标的动作被保留,不利于目标的动作被衰减。通过带有回报的交互数据训练智能体
-
强化学习分类
1)根据是否依赖(环境和智能体)模型分为基于模型的RL和无模型的RL。智能体在探索环境时已知转移概率,回报函数,折扣因子等。基于模型效率更高,无模型更具通用性
2)根据策略的更新和学习方法分为基于值函数的RL、基于策略搜索的RL和AC(actor-critic)的RL。基于值函数指学习值函数,最终策略通过值函数贪婪最大得到,任意状态s下,值函数最大的动作a为当前最优策略Π(a|s)。基于策略搜索是将策略参数化,学习实现目标的最有参数,通过梯度更新。基于AC是联合使用值函数和策略搜索办法
3)根据回报函数是否已知分为正向RL和逆向RL。逆向RL指回报函数未知,需要先通过学习得到
4)根据策略是否随机分为确定性策略RL和随机性策略</
《强化学习》基础知识(一)
最新推荐文章于 2025-10-11 13:25:04 发布
 强化学习专注于序贯决策问题,与监督学习不同,它关注在当前状态下选择最佳动作以达到目标。文章介绍了强化学习的分类,包括基于模型与无模型、基于值函数与策略搜索、正向与逆向,以及确定性与随机性策略。还提到了常见的强化学习环境和相关概率学概念,如随机策略、贪婪策略和ε-greedy策略。
强化学习专注于序贯决策问题,与监督学习不同,它关注在当前状态下选择最佳动作以达到目标。文章介绍了强化学习的分类,包括基于模型与无模型、基于值函数与策略搜索、正向与逆向,以及确定性与随机性策略。还提到了常见的强化学习环境和相关概率学概念,如随机策略、贪婪策略和ε-greedy策略。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









