







 本文详细介绍了jieba分词库的三种模式:精确模式、全模式和搜索引擎模式,并通过实例展示了如何使用这些模式进行文本分词。此外,还提供了一个使用jieba分词统计文本中词语频率的例子。
本文详细介绍了jieba分词库的三种模式:精确模式、全模式和搜索引擎模式,并通过实例展示了如何使用这些模式进行文本分词。此外,还提供了一个使用jieba分词统计文本中词语频率的例子。
jieba分词的三种模式
- 精确模式:把文本精确的切分开,不存在冗余单词,适合做文本分析。
- 全模式:把文本中所有可能的词语都扫描出来,速度快,但有冗余。
- 搜索引擎模式:在精确模式基础上,对长词再次切分。
| 函数 | 含义 |
|---|---|
| jieba.cut(string) | 精确模式,返回一个可迭代的数据类型 |
| jieba.cut(string,cut_all = True) | 全模式,输出文本string中的所有可能的单词 |
| jieba.cut_for_search(string) | 搜索引擎模式,适合搜索引擎建立索引的分词结果 |
| jieba.lcut(string) | 精确模式,返回一个列表类型 |
| jieba.lcut(string,cut_all = True) | 全模式,返回一个列表类型 |
| jieba.lcut_for_search(string) | 搜索引擎模式,返回一个列表类型 |
| jieba.add_word(word) | 向分词词典中增加新词 |
jieba三种模式的简单使用
# _*_ coding:utf-8 _*_
import jieba
words = jieba.cut("山东的气候属暖温带季风气候类型",cut_all=True) #全模式
print("全模式:", '/ '.join(words) )
words = jieba.lcut("山东的气候属暖温带季风气候类型",cut_all=True) #全模式,返回列表
print("全模式:", words)
words = jieba.cut("山东的气候属暖温带季风气候类型",cut_all=False) #精确模式
print("精确模式:", '/ '.join(words) )
words = jieba.lcut("山东的气候属暖温带季风气候类型",cut_all=False) #精确模式,返回列表
print("精确模式:", words )
words = jieba.cut("山东的气候属暖温带季风气候类型") #默认是精确模式
print("精确模式:", '/ '.join(words) )
words = jieba.cut_for_search("山东的气候属暖温带季风气候类型") #搜索引擎模式
print("搜索引擎模式:", '/ '.join(words) )
words = jieba.lcut_for_search("山东的气候属暖温带季风气候类型") #搜索引擎模式,返回列表
print("搜索引擎模式:", words )
运行效果:

jieba简单应用
使用 jieba 分词对一个文本进行分词,统计次数出现最多的词语,以盗墓笔记为例
# _*_ coding:utf-8 _*_
import jieba
text = open('C:/Users/dell/Desktop/test/盗墓笔记.txt', 'r' ,encoding = 'utf-8').read()
words = jieba.cut(text)
word_counts = {}
for word in words:
if len(word) < 2:
continue
word_counts[word] = word_counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加1
word_counts_items = list(word_counts.items())
word_counts_items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
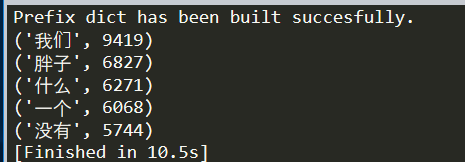
for i in range(5):
print(word_counts_items[i])
运行效果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









