







摘要
本文提出了一对生成器模型和分割模型,可以将一组未进行配对的数据集A和B进行互相转换,并在此过程中提高分割模型的性能。文中采用的数据集A为MRI图像,B为CT图像,利用总共4496张未配对的图像进行训练后,模型取得了SOTA。
方法
框架
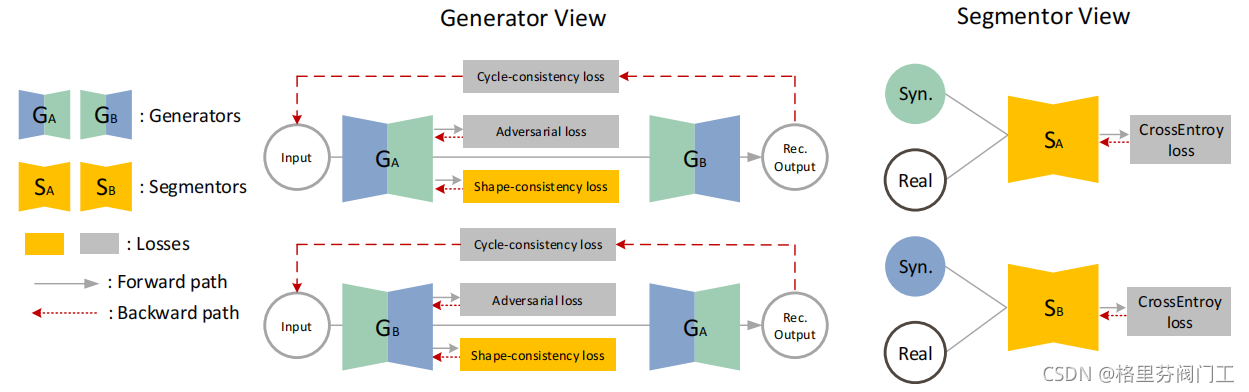
本文方法主要分为两块,一部分为生成器模型训练,一部分为分割模型训练。生成器模型部分,有三个损失,一个是生成损失Adversial Loss,用于监督图像是否真实,一个是循环一致性损失Cycle-consistency Loss,让图像经过两个生成器的变换后尽可能和原图像一致,最后是形状一致性损失Shape-consistency Loss,由分割模型提供,让转换后的图像分割结果逼近转换前的分割结果。
分割模型部分的训练就比较简单,利用真实图像和生成图像基于交叉熵训练损失即可。
这四个损失中,由作者提出来的是两个一致性损失,因此主要介绍这两个损失。
循环一致性损失
这个损失很简单,经过两个生成器转换后的图像与原图像尺寸一致,因此将两幅图像上的每个像素点做差,取绝对值,最后再求这些绝对值的平均值即可(求平均是L1损失,作者这里提了一嘴说L1损失比L2损失表现更好)。
形状一致性损失
因为本文的生成器是生成一副图像对应的另一幅图像,而CT和MRI可以表示人体的同一部位。因此,生成图像和原有图像的病灶应该是完全一致的。因此,形状一致性损失是把真实图像的GT当作生成图像被分割模型的GT,求交叉熵损失。
训练过程
基于以上几种损失,轮换着训练生成器,判别器和分割模型。固定判别器和分割模型参数,更新生成器参数,然后固定生成器参数,更新另外两个模型的参数。更新分割模型参数时,使用了真实图像和生成图像,生成图像包括一次转换后的图像,也包括两次转换后的图像。
实验
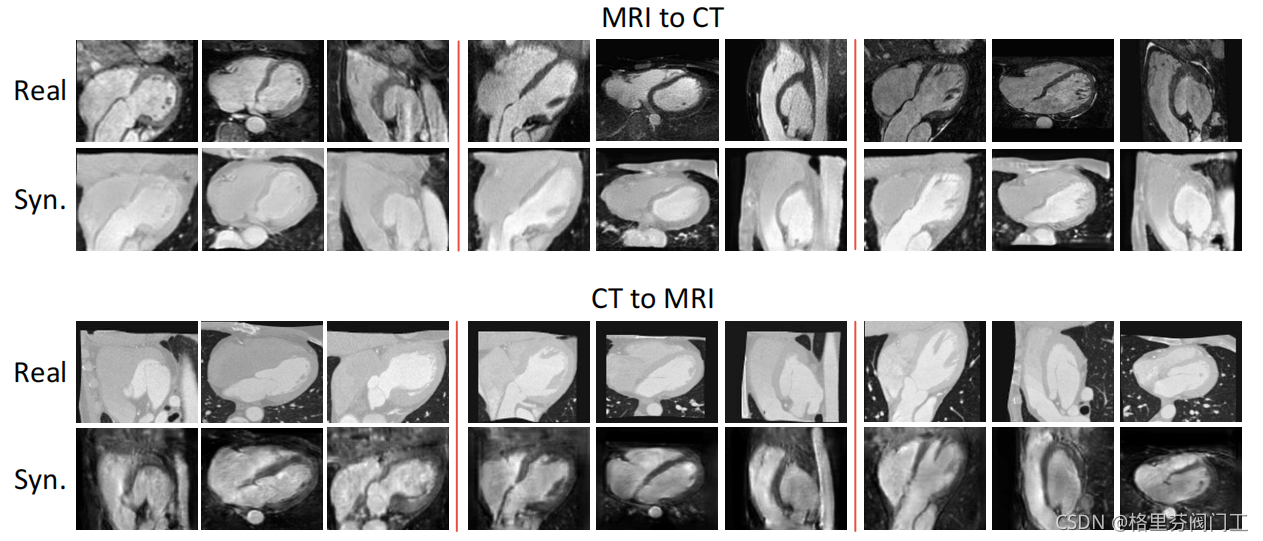
图中,红线分割开的每六幅图片为一组,三幅真,三幅合成,三幅真实图像由真实的3D图像通过三个正交的面截取得到。可以看出,生成图像接近真实图像
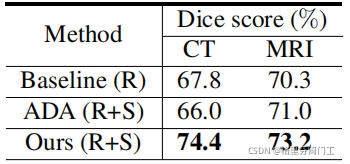
从具体的性能指标上来看,本文表现也十分优异。其中R和S分别指真实图像和生成图像。ADA使用了本文生成的图像,包括一次变换后的图像和两次变换后的近似原有真实图像的生成图像。
消融实验
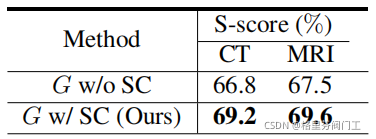
实验一探究了形状一致性的作用,采用了形状一致性的模型在S-score上要比不采用该损失的模型高两个左右的百分点
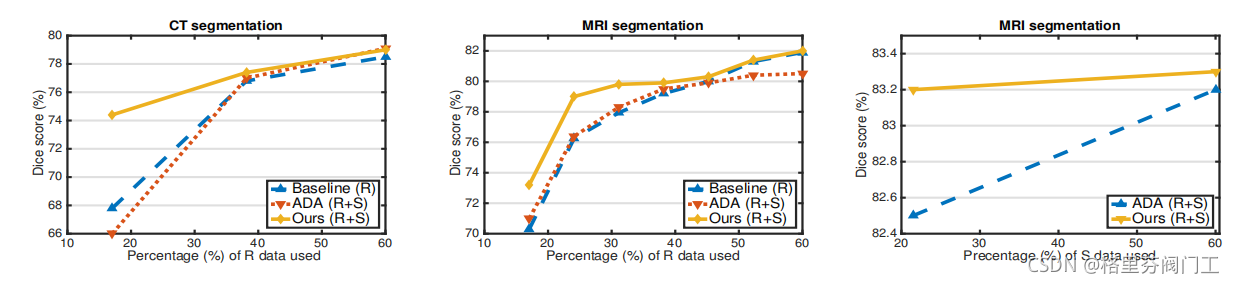
实验二探究了生成数据对模型训练的影响,左边的和中间的两个实验改变百分比的方式是固顶生成图像数量,改变真实图像数量,因此横轴为真实数据百分比。而最右边的实验是固定真实图像数量,改变合成图像数量。可见,在某种数据数量固定时,提高另一种数据的数量均可以提高模型性能,这说明合成图像对模型训练是有益的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









