







1、Python定义
Python 是一种易于学习又功能强大的编程语言。它提供了高效的高级数据结构,还能简单有效地面向对象编程。Python 优雅的语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的理想语言
2、基础语法
2.1、常见转义字符
| 字符 | 解释 |
|---|---|
| \n | 换行符 |
| \ | 反斜线 |
| ’ | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格 |
| \t | 制表符 |
| \r | 回车 |
2.2、变量
在程序设计语言中,变量是存储单元的标示牌,在这块存储单元中,可以存储任何值,我们可以通过变量名来访问存储的值

2.3、数据类型
2.4、字符串方法
2.4.1、strip()
去头尾空格
star = " NEPTUNE "
print(star)
print(len(star))
print(star.strip())
print(len(star.strip()))
2.4.2、lower()
返回小写的字符串
star = "NEPTUNE"
print(star.lower())
2.4.3、upper()
返回大写的字符串
star = "neptune"
print(star.upper())
2.4.4、replace()
用另一段字符串来替换字符串
say_hi = "Hello World!"
print(say_hi.replace("World", "Kitty"))
2.4.5、split()
按指定的分隔符分隔字符串
say_hi = "Mercury,Venus,Earth,Mars,Jupiter,Saturn,Uranus,Neptune,Pluto"
print(say_hi.split(","))
2.4.6、in / ont in
使用 in 或 not in 来检查字符串中是否存在特定短语或字符
book_name = "Men Are from Mars, Women Are from Venus"
is_exist = "Mars" in book_name
print(is_exist)
2.4.7、+
使用 + 运算符对字符串进行拼接
first_part = "Men Are from Mars"
second_part = "Women Are from Venus"
print(first_part + ', ' + second_part)
2.4.8、引用变量
字符串中引用变量的值
- 在字符串前面加小写字母
f - 在字符串中,将需要引用的变量,用花括号包起来 {name}
name = 'Earth'
age = 4.543E9
print(f"My name is {name}, {age} years old")
3、流程控制
3.1、if …
我们一定要注意语法规范:if 条件语句后面要加 :且是英文状态下的冒号 :
if 后的语句要缩进四个空格,这是因为语句块 1 是在满足 if 条件下要执行的,因此要有缩进。
weight = 65
height = 1.55
BMI = float(weight) / (float(height) * float(height))
if BMI >= 25:
print("BMI=", BMI)
print("织女体重过重")
3.2、if … else …
weight = 40
height = 1.55
BMI = float(weight) / (float(height) * float(height))
if 18.5 <= BMI < 25:
print("BMI=", BMI)
print("织女体重正常")
else:
print("织女体重过重或过轻")
3.3、if … elif … else …
elif 语句块可出现一次或多次
weight = 40
height = 1.55
BMI = float(weight) / (float(height) * float(height))
if 18.5 <= BMI < 25:
print("BMI=", BMI)
print("织女体重正常")
elif BMI < 18.5:
print("BMI=", BMI)
print("织女体重过轻")
else:
print("BMI=", BMI)
print("织女体重过重")
3.4、嵌套 if 语句
由于 if 语句允许嵌套,也就是 if 语句中可以再包含 if 语句,需要注意的是相应的语法规则要对应上(比如 if 语句的冒号、缩进、else 的冒号和缩进等等),所以上述 if 语句后面跟的语句块同样可以包含 if 语句。使用嵌套 if 语句,可以将上述代码改成如下形式:
weight = 40
height = 1.55
BMI = float(weight) / (float(height) * float(height))
if 18.5 <= BMI < 25:
print("BMI=", BMI)
print("织女体重正常")
elif BMI < 18.5:
print("BMI=", BMI)
if 16 <= BMI:
print("织女体重过轻")
elif 15 <= BMI < 16:
print("织女严重体重不足")
else:
print("织女非常严重的体重不足")
else:
print("BMI=", BMI)
if BMI < 30:
print("织女体重过重")
elif 30 <= BMI < 35:
print("织女中等肥胖")
elif 35 <= BMI < 40:
print("织女严重肥胖")
else:
print("织女非常严重肥胖")
4、列表
列表是有序数据的集合。定义的语法是使用方括号 [ ] 括起来以逗号分隔的数据。例如:
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李', '吕洞宾', '何仙姑', '蓝采和', '曹国舅']
print(eight_immortal)
eight_immortal 就是一个列表,[ ] 包含的每一个信息称为元素,'汉钟离'、'张果老'、'韩湘子'等就是元素
4.1、列表的特性
4.1.1、有序
列表不仅是数据的集合,而且这些数据还是有序的。如果两个列表包含的元素相同,但是元素的排列顺序不同,那么他们是两个不同的列表。
eight_immortal1 = ['汉钟离', '张果老', '韩湘子', '铁拐李', '吕洞宾', '何仙姑', '蓝采和', '曹国舅']
eight_immortal2 = ['吕洞宾', '何仙姑', '蓝采和', '曹国舅', '汉钟离', '张果老', '韩湘子', '铁拐李']
print(eight_immortal1 == eight_immortal2)
4.1.2、元素的数据类型
同一个列表可以包含不同类型的数据。
eight_immortal = ['汉钟离', 1, '张果老', 2, '韩湘子', 3, '铁拐李', 4,'吕洞宾', 5, '何仙姑', 6, '蓝采和', 7, '曹国舅', 8]
print(eight_immortal)
4.1.3、元素可重复
同一个列表中的元素可重复。
eight_immortal1 = ['铁拐李', '铁拐李', '何仙姑', '何仙姑', '蓝采和', '蓝采和']
print(eight_immortal1)
4.1.4、元素访问
我们可以通过索引的方式来访问列表中的元素,这个和访问字符串中的字符的原理是一样的。
- 从前往后访问时,索引的下标从 0 开始,当从后往前访问时,索引的下标从 -1 开始
- 切片操作对列表同样是适用的,语法是 列表名
[m:n],访问的元素从索引 m 开始到索引 n 结束,不包括 n。当不指定 m 和 n 时,也就是列表名[:]访问的是整个列表 - 当只指定 m ,不指定 n 时,列表名[m:] 访问的是从索引 m 开始,一直到列表结束的元素
- 当只指定 n ,不指定 m 时,列表名[:n]访问的是从索引 0 开始,一直到索引 n 的元素,不包括索引 n 对应的元素
- 列表名
[m:n:步长]步长在实际的编程中,是用数据表示的,1 表示 1 步,2 表示 2 步,步长也可以省略,省略时步长默认为 1 - 步长为 -1 时倒序
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李', '吕洞宾', '何仙姑', '蓝采和', '曹国舅']
print(eight_immortal[-1])
print(eight_immortal[3])
print(eight_immortal[1:3])
print(eight_immortal[3:])
print(eight_immortal[:2])
print(eight_immortal[:])
print(eight_immortal[0:7:2])
print(eight_immortal[::-1])
4.1.5、列表可以嵌套
列表中的元素同样可以是一个列表。
my_list = ['a', ['bb', ['ccc', 'ddd'], 'ee', 'ff'], 'g', ['hh', 'ii'], 'j']
print(my_list[0])
print(my_list[1])
print(my_list[1][0])
print(my_list[1][1][0])
4.1.6、列表元素可修改
改变元素的值
(1)一次改变一个值
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李', '吕洞宾', '何仙姑', '蓝采和', '曹国舅']
eight_immortal[0] = '逍遥闲散'
eight_immortal[5] = '清婉动人'
print(eight_immortal)
(2)一次改变多个值
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李', '吕洞宾', '何仙姑', '蓝采和', '曹国舅']
eight_immortal[0:3] = ['逍遥闲散', '倒骑毛驴','巧夺造化']
print(eight_immortal)
删除元素
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李', '吕洞宾', '何仙姑', '蓝采和', '曹国舅']
del eight_immortal[1]
print(eight_immortal)
del eight_immortal[0:3]
print(eight_immortal)
使用 + 往列表中增加元素
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李', '曹国舅']
print(eight_immortal)
eight_immortal += ['容成公', '李耳', '董仲舒','范长生','尔朱先生']
print(eight_immortal)
4.2、改变列表的方法
4.2.1、append()
也可以为列表添加元素,和 + 一样,也是在列表的结尾处添加元素,可以添加一个元素或列表。
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李']
eight_immortal.append('吕洞宾')
print(eight_immortal)
eight_immortal.append(['何仙姑', '蓝采和'])
print(eight_immortal)
4.2.2、insert()
insert() 可以在指定位置插入一个元素或列表。
语法是:insert(n, 需要添加的元素/列表值),n 为需要插入元素或列表的指定位置
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李']
eight_immortal.insert(3, '吕洞宾')
print(eight_immortal)
eight_immortal.insert(4, ['何仙姑', '蓝采和', '曹国舅'])
print(eight_immortal)
4.2.3、remove()
我们可以在列表中添加元素,也可以删除元素,我们使用 remove(元素值) 从列表中删除指定的元素,如果指定的元素在列表中不存在,则会报错。
eight_immortal = ['汉钟离', '张果老', '韩湘子', '铁拐李', '吕洞宾', '何仙姑']
eight_immortal.remove('汉钟离')
print(eight_immortal)
4.2.4、pop(index)
除了 remove(),我们还可以使用 pop(index) 来删除指定元素,index 为元素在列表中的位置。
pop(index) 语法规则为:列表名.pop(index),从列表中删除指定索引上的元素,如果不指定 index,默认删除最后一个元素。
eight_immortal = ['汉钟离', '张果老']
print(eight_immortal)
eight_immortal.pop()
print(eight_immortal)
都是删除元素,pop() 和 remove() 主要有两点不同:
- pop()传入的参数为索引值,而不是具体的元素值
- pop() 的返回值为删除的元素
5、循环
循环使得我们能够对列表中的每个元素执行相同的操作,这样对于任意长度的列表我们都可以很高效地对其进行处理
5.1、for 循环
for 循环用于迭代序列(即列表、元组、字典、集合或字符串等)。这与其他编程语言中的 for 关键字不太相似,而是更像其他面向对象编程语言中的迭代器方法。
通过使用 for 循环,我们可以为列表、元组、集合中的每个元素执行一系列的操作。
# 打印出1-20
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
for var in numbers:
print(var)
我们也可以在这个基础上进行进一步的数字计算,比如对 1 到 20 的数字进行求和:
# 对 1 到 20 的数字求和
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
count = 0
for var in numbers:
count += var
print("count = ", count)
嵌套 if 流程控制
# 天空中的太阳数量在2-10时,保持射箭!
sun_in_sky = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for i in sun_in_sky:
if i > 1:
print("继续射箭 ")
5.2、while 循环
while 循环:只要条件满足,就会一直执行一组语句。Python 中,while 表示的信息是当…时候,也就是说当 while 循环的条件满足时,会一直执行满足条件的语句。
# 打印1-20
i = 0
while i < 20:
i += 1
print(i)
我们也可以在这个基础上进行进一步的数字计算,比如对 1 到 20 的数字进行求和:
# 对 20 以内的正整数求和
count = 0
i = 1
while i <= 20:
count += i
i += 1
print("count = ", count)
5.3、break 和 continue
一般情况下,循环语句会重复执行循环体语句,直到循环条件不满足。但是,在有些情况下,我们需要提前结束本轮循环或者直接结束整个循环。这时候便要用到 break 和 continue 语句
break 和 continue 语句的使用,通常是与 if 条件语句配合的,当满足 if 条件语句的时候,结束整个循环或者结束本轮循环
5.3.1、break
将 break 用于 for 循环:对 1 到 20 的数字求和(和为 210),当和大于 100 时,停止求和,退出整个循环。
# 对 1 到 20 的数字求和,当和大于 100 时,便停止求和
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
count = 0
for var in numbers:
count += var
if count >= 100:
break
print("count = ", count)
将 break 用于 while 循环:对 1 到 20 的数字求和(和为 210),当和大于 100 时,停止求和,退出整个循环。
# 对 20 以内的正整数求和,当和大于 100 时,停止求和
count = 0
i = 1
while i <= 20:
count += i
i += 1
if count >= 100:
break
print("count = ", count)
5.3.2、continue
break 语句是结束整个循环,如果想提前结束本轮循环,可以使用 continue 语句。
将 continue 用于 for 循环
# 对 20 以内的偶数求和
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
count = 0
for var in numbers:
# 奇数,除以2的余数不为0,也就是不能被2整除
if var % 2 != 0:
# 当数字为奇数时,退出本次循环
continue
count += var
print("count = ", count)
将 continue 用于 while 循环
# 对 20 以内的偶数求和
count = 0
i = 0
while i < 20:
i += 1
if i % 2 != 0:
continue
count += i
print("count = ", count)
6、字典
{'姓名':'张三','年龄':18}就是一个字典,字典是一系列键值对的集合,姓名:张三便是一个键值对,其中键为姓名,值为 张三。创建字典时,只需要将键值对用花括号{} 括起来,每个键值对的键和值之间用冒号 : 分隔,每个键值对之间用逗号 , 分隔。
6.1、创建字典
用大括号 { } 将键值对括起来,键值对的键和值之间用冒号:分隔,键值对之间用逗号,分隔。
需要注意的是,在创建字典时,当键值重复时,以后加入的键值对为准。
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
print(ne_zha)
print(type(ne_zha))
6.2、访问字典
6.2.1、键名访问
访问字典中某个键值对的值:字典名[ 键名 ],只需要将键值对的键名放到方括号 [ ] 中就可以啦。
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450,'最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
print(ne_zha['英雄名字'])
print(ne_zha['最大生命'])
print(ne_zha['生命成长'])
6.2.2、get()
除了使用上述方式进行访问外,我们还可以使用 get() 方法进行访问,语法规则是:字典名.get(键名)
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450,'最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
print(ne_zha.get('英雄名字'))
print(ne_zha.get('最大生命'))
print(ne_zha.get('生命成长'))
6.2.3、for 循环遍历字典
除了上述两种方法,我们还可以通过遍历的方式(一般通过 for 循环来实现遍历哦)来访问字典中的键值对。
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
for a in ne_zha:
print(a,":",ne_zha[a])
# 打印值
for value in ne_zha.values():
print(value)
6.2.1、items() 函数遍历
还可以使用 items() 函数遍历键和值,语法规则是:字典名.items()
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
for key, value in ne_zha.items():
print(key, ":", value)
6.3、修改字典
和列表一样,我们可以对创建好的字典进行相应的修改。
6.3.1、添加项目
我们之前在变量和列表中都介绍了索引,现在又是索引发挥作用的时刻了,我们可以通过使用新的索引键并为其赋值,来为字典添加新的项目。
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
ne_zha['最大每5秒回血'] = 98
print(ne_zha)
6.3.2、删除项目
除了可以往字典中添加项目,我们也可以从字典中删除项目。我们可以通过多种方式删除字典中的项目,我们逐一介绍给大家:
pop()
pop() 方法删除具有指定键名的项,语法规则为字典名.pop(键名)。键名如果是字符串,记得加英文状态下的引号哟!
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
ne_zha.pop('英雄名字')
print(ne_zha)
popitem()
popitem() 方法删除最后插入的项目(在 3.7 之前的版本中,删除随机项目),语法规则为:字典名.popitem()
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
print(ne_zha)
ne_zha.popitem()
print(ne_zha)
del
我们也可以使用 del 关键字删除具有指定键名的项目,语法规则为:del 字典名[键名]
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
del ne_zha['最大生命']
print(ne_zha)
#完全删除字典
del ne_zha
clear()
clear() 函数清空字典,语法规则为:字典名.clear()
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
ne_zha.clear()
print(ne_zha)
6.4、复制字典
使用内建的字典方法 copy(),语法规则是:字典名.copy()
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
ne_zha_copy = ne_zha.copy()
print(ne_zha_copy)
制作副本的另一种方法是使用内建方法 dict(),语法规则是:dict(字典名)
ne_zha = {'英雄名字': '哪吒', '最大生命': 7268, '生命成长': 270.4, '初始生命': 3483, '最大法力': 1808, '法力成长': 97, '初始法力': 450, '最高物攻': 320, '物攻成长': 11.5, '初始物攻': 159, '最大物防': 408, '物防成长': 22.07, '初始物防': 99}
ne_zha_copy = dict(ne_zha)
print(ne_zha_copy)
6.5、使用 dict() 创建字典
我们也可以使用 dict() 构造函数创建新的字典,语法规则为:字典名 = dict(键名=键值, 键名=键值,..., 键名=键值)
# 注意:1.关键字不是字符串字面量;2.使用了等号而不是冒号来赋值。
ne_zha = dict(英雄名字='哪吒', 最大生命=7268, 生命成长=270.4, 初始生命=3483, 最大法力=1808, 法力成长=97, 初始法力=450, 最高物攻=320, 物攻成长=11.5, 初始物攻=159, 最大物防=408, 物防成长=22.07, 初始物防=99)
print(ne_zha)
7、元祖
元组和列表很像,区别在于元组创建完成后便不能被修改。创建元组很简单,只需要将用逗号分隔的元素放到 () 中,如果元素为字符串,别忘记添加引号哟!
7.1、创建元祖
loong_son = ('囚牛', '睚眦', '嘲风', '蒲牢', '狻猊', '霸下', '狴犴', '负屃', '螭吻')
print(loong_son)
如果需要创建一个仅包含一个元素的元组,必须在该元素后面添加一个逗号,否则,Python 无法将变量识别为元组。
loong_son1 = ('囚牛') # 不是元组
loong_son2 = ('囚牛',)
print(type(loong_son1))
print(type(loong_son2))
友情提示:type()是获取数据类型的方法哦!
7.2、访问元祖
7.2.1、索引访问
索引部分的内容和之前介绍的一样,正索引是从左到右,用 0 表示第一个元素;负索引是从右到左,用 -1 表示右边第一个元素,大家一定要记清楚哟!
loong_son = ('囚牛', '睚眦', '嘲风', '蒲牢', '狻猊', '霸下', '狴犴', '负屃', '螭吻')
print(loong_son[0])
print(loong_son[-2])
print(loong_son[0:3])
print(loong_son[1:])
print(loong_son[:3])
print(loong_son[:])
print(loong_son[-3:-1])
print(loong_son[-3:])
print(loong_son[:-1])
7.2.2、遍历元祖
我们也可以使用 for 循环遍历元组元素。
loong_son = ('囚牛', '睚眦', '嘲风', '蒲牢', '狻猊', '霸下', '狴犴', '负屃', '螭吻')
for elem in loong_son:
print(elem)
7.3、修改元祖
-
元组在创建完成后便不能被修改!因此任何关于修改元组的操作都会报错,比如添加新元素到元组中,或者是删除元组中的某些元素
-
元组是不可改变的,因此无法从中删除元素,但可以删除整个元组
loong_son = ('囚牛', '睚眦', '嘲风', '蒲牢', '狻猊', '霸下', '狴犴', '负屃', '螭吻')
del loong_son
7.4、合并元祖
元组不能被修改,但是两个元组是可以合并成一个新的元组的,在 Python 中,使用 + 运算符可以连接两个或多个元组
loong_son1 = ('囚牛', '睚眦', '嘲风', '蒲牢', '狻猊')
loong_son2 = ('霸下', '狴犴', '负屃', '螭吻')
loong_son = loong_son1 + loong_son2
print(loong_son)
8、集合
集合是无序元素的集合,集合中的元素不可重复,并且创建完成后,其中的元素不可更改。但是整个集合是可以更改的,我们可以向其增加元素,也可以从中删除元素。也就是说,我们无法修改集合中的元素,但是我们可以对整个集合进行添加或者是删除等更改的操作。
集合的创建非常简单,只需要将以逗号分隔的元素放在花括号 {} 中,{元素1,元素2,元素3,…,元素n}。
8.1、创建集合
集合中的元素不可重复,如果有重复元素,重复的元素将被忽略。
novels = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行'}
print(novels)
8.2、访问集合
可以通过 for 循环来遍历集合的元素,另外,还可以使用 in 关键字来判断集合中是否存在某个元素。
novels = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行'}
for novel in novels:
print(novel)
使用 in 关键字来判断集合中是否存在某个元素,如果元素在集合内,返回 True,如果元素不在集合内,返回 False
novels = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行'}
print('鸳鸯刀' in novels)
print('天龙八部' in novels)
8.3、修改集合
8.3.1、add() 和 update()
add() 和 update() 都可用于向集合添加元素
语法规则为:集合名.add(元素名)、集合名.update({元素1,元素2,...,元素n})
我们看到 add() 和 update() 的一个区别是 add() 添加的是一个元素;update() 添加的是集合或者是列表,添加的是多个元素
novels = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记'}
novels.add('笑傲江湖')
print(novels)
novels.update({'侠客行', '倚天屠龙记'}) # update 的参数为集合
print(novels)
novels.update(['碧血剑', '鸳鸯刀'])
print(novels) # update 的参数为列表
8.3.2、discard() 和 remove()
除了可以对整个集合添加元素,我们还可以删除集合中的元素
discard() 和 remove() 用于从集合中删除元素
语法规则为:集合名.discard()、集合名.remove()
这两个函数的区别在于,从集合中删除一个不存在的元素时,discard() 不会执行任何操作,而 remove() 会抛出一个异常
novels = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
novels.discard('飞狐外传')
print(novels)
novels.remove('雪山飞狐')
print(novels)
8.4、集合操作
我们在数学中,也学习到了集合的相关概念,在数学中,我们可以对集合进行一系列的操作,比如并集、交集和差集。Python 中的集合,我们也可以做相应的操作,实现 Python 集合的并集、交集和差集。
8.4.1、并集
将集合 A 和集合 B 的所有元素合并在一起,就组成了集合 A 和集合 B 的并集。实现集合并集可以使用 union() 和 | 操作符
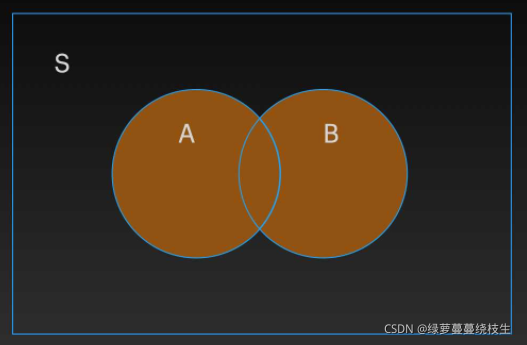
1、使用 union() 实现集合的并集,语法规则为:集合1.union(集合2)
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1.union(novels_2))
print(novels_2.union(novels_1))
2、使用 | 对两个集合进行并集的运算,语法规则为:集合1 | 集合2
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1 | novels_2)
8.4.2、交集
A,B 是两个集合,由所有属于集合 A 且属于集合 B 的元素所组成的集合,叫做集合 A 与集合 B 的交集(intersection),记作 A∩B。我们使用 intersection() 和 & 实现不同集合间的交集
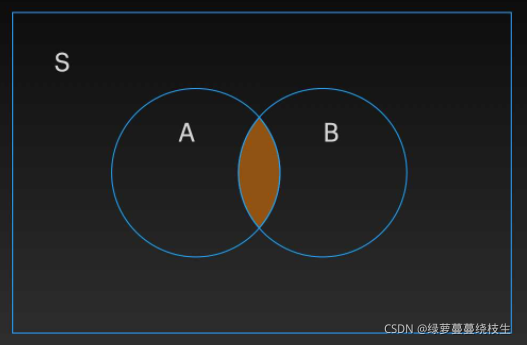
1、intersection() 可以实现集合 A 和集合 B 的交集运算,语法规则是:集合1.intersection(集合2)
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1.intersection(novels_2))
print(novels_2.intersection(novels_1))
2、& 也可以实现集合 A 和集合 B 的交集运算,语法规则是:集合1 & 集合2
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1 & novels_2)
8.4.3、差集
集合 A 和集合 B 中,只属于其中一个集合,不属于另一个集合的元素。比如属于集合 A 不属于集合 B 的元素集合,或者是属于集合 B 不属于集合 A 的元素集合
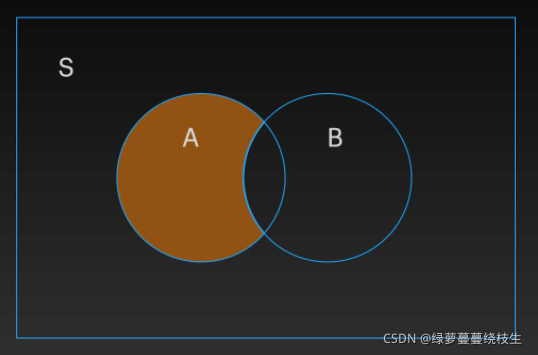
1、可以使用 difference() 来实现差集的运算,语法规则为:集合1.difference(集合2)
当集合 novels_1 在 difference() 之前时,打印的是属于集合 novels_1 不属于集合 novels_2 的元素集合,集合 novels_2 在 difference() 之前时,打印的是属于集合 novels_2 不属于集合 novels_1 的元素集合。
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1.difference(novels_2))
print(novels_2.difference(novels_1))
2、使用-来实现差集的运算,语法规则为:集合1 - 集合2
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1 - novels_2)
8.4.4、对称差集
对称差集就是属于集合 A,不属于集合 B 的以及属于集合 B 不属于集合 A 的元素集合,就是集合 A 与集合 B 的并集减去集合 A 与集合 B 的交集
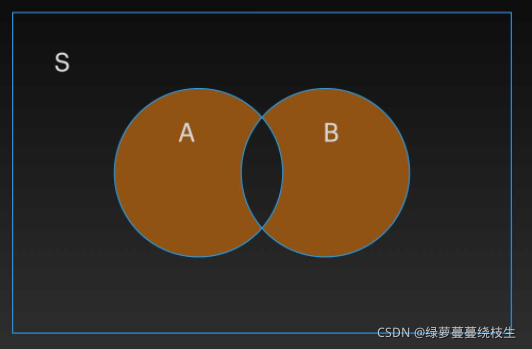
1、使用 symmetric_difference() 来实现对称差集的运算,语法规则是:集合1.symmetric_difference(集合2)
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1.symmetric_difference(novels_2))
print(novels_2.symmetric_difference(novels_1))
2、使用 ^ 来实现对称差集的运算,语法规则是:集合1^集合2
novels_1 = {'飞狐外传', '雪山飞狐', '连城诀', '天龙八部', '射雕英雄传', '白马啸西风', '鹿鼎记', '笑傲江湖'}
novels_2 = {'鹿鼎记', '笑傲江湖', '书剑恩仇录', '神雕侠侣', '侠客行', '倚天屠龙记', '碧血剑', '鸳鸯刀'}
print(novels_1 ^ novels_2)
print(novels_2 ^ novels_1)
9、函数
在 Python 中,函数是一组相关的语句,这些语句完成一个特定的任务。
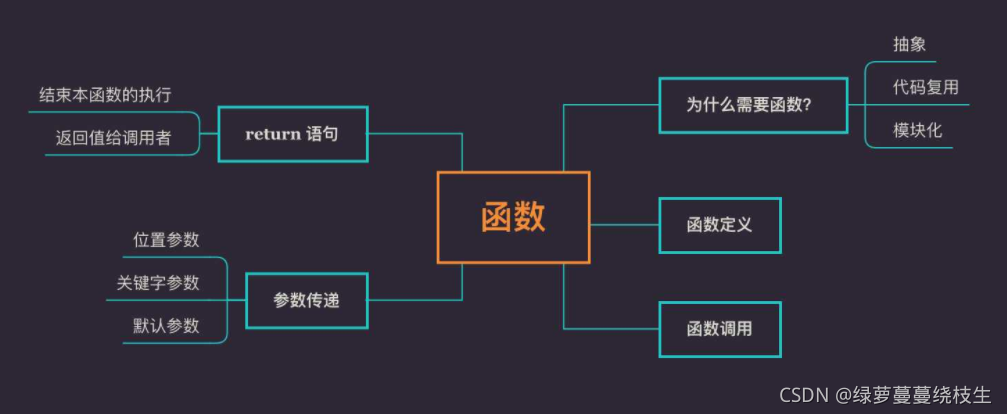
9.1、函数语法
def function_name(parameters):
statement(s)
- 关键字 def 标识函数头的开始。
- function_name 为函数名,命名规则和变量相同。
- parameters 以逗号分隔的参数列表,用来接收传递给函数的值,参数列表是可选的。虽然参数列表是可选的,但是函数名后面的括号是必须的。
:标识函数头的结束。- statement(s) 组成函数体的一条或多条语句,这些语句必须是相同的缩进(一般是缩进 4 个空格)。
9.2、函数的调用
语法:
function_name(parameters)
parameters 为传递给函数的值,是可选的。即便不需要传递值给函数,函数名后的括号也是必须的。
9.3、传递参数
虽然不带参数的函数也可以完成某些特定任务,但是,大多数时候,我们需要给函数传递值,这样的话,每次调用函数的行为都会因为传递的值不同而变得不同
9.3.1、位置参数
位置参数就是表示参数的位置对于函数的结果是有影响的,同样的参数值,在不同的位置,会有不一样的结果表达
def cal(qty, item,price):
print(f'{qty} {item} cost ${price:.2f}')
cal(6, 'bananas', 5.74)
f表示格式化输出,格式化 { } 中的内容,不在 { } 内的语句照常展示输出{ :.2f }表示保留两位小数,如果是{ :.0f }则不保留小数位
9.3.2、关键字参数
在传递值的时候,还可以带上参数的名字,具体形式为 keyword = value,这里的 keyword 必须匹配上一个函数定义中的参数名,也就是说是 参数名1=值1,参数名2=值2,参数名3=值3 这种形式
- 在指定了参数名之后,值的顺序和函数定义中的参数顺序可以不用保持一致
- 虽然顺序可以不用保持一致,但是值的个数还需要和参数的个数保持相同
def cal(qty, item, price):
print(f'{qty} {item} cost ${price:.2f}')
cal(qty=6, item='bananas', price=5.74)
9.3.3、默认参数
- 在定义函数时,我们还可以指定参数的默认值
- 指定默认值之后,在调用函数时如果没有指定某个参数的值,就用参数的默认值
(1)调用时,每个参数都给出了值,这时候便用调用时指定的值
def cal(qty=6, item='bananas', price=5.74):
print(f'{qty} {item} cost ${price:.2f}')
cal(4, 'apples', 2.24)
(2)调用时,只给出了部分参数的值,这时候没有给出值的参数,使用的就是其默认值
def cal(qty=6, item='bananas', price=5.74):
print(f'{qty} {item} cost ${price:.2f}')
cal(4, 'apples')
(3)调用时,也可以不给出参数的值,这时候全部使用默认的值
def cal(qty=6, item='bananas', price=5.74):
print(f'{qty} {item} cost ${price:.2f}')
cal()
(4)调用时,也可以指定参数名
def cal(qty=6, item='bananas', price=5.74):
print(f'{qty} {item} cost ${price:.2f}')
cal(item='kumquats', qty=9)
9.4、return 语句
(1)立即结束本函数的执行,将程序的执行控制权交还给调用者
def f(x):
if x < 0:
return
if x > 100:
return
print(x)
f(-3)
f(105)
f(64)
当调用函数 f(-3) 时,传递参数值 -3,回到函数 f(x) 中,符合语句 x < 0,执行 return 语句,立即返回;执行调用函数 f(105) 语句,符合语句 x > 100,执行 return 语句,立即返回;执行调用函数f(64) 语句,64 既不 < 0,也不 > 100,执行 print(x) 语句,打印出 64
(2)返回数据给调用者
def absolute_value(num):
if num >= 0:
return num
else:
return -num
print(absolute_value(2))
print(absolute_value(-4))
10、类和对象
Python 中的类是用来描述具有相同的属性和方法的对象的集合,它定义了该集合中每个对象所共有的属性和方法。
类是抽象的模板。
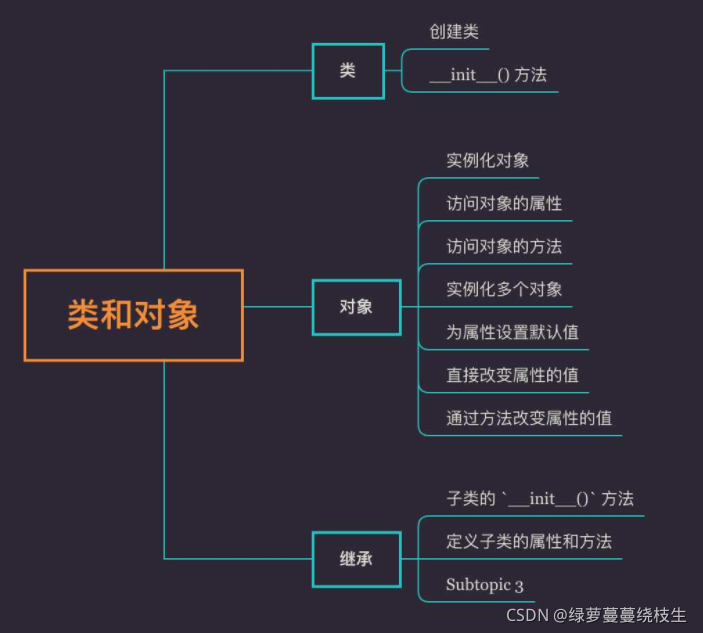
10.1、类
类的定义以关键字 class 开头,后面紧跟类名和冒号,下面跟着是类的主体部分,代码以缩进标识。
#创建类Bird
class Bird:
#对象初始化语句
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
#定义方法get_description,参数为self,自动传入
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
我们创建了一个类 Bird,并定义了类 Bird 的两种方法(类中的函数称作方法) __init__( )和get_description( ),这两个方法是所有属于类 Bird 的对象共有的方法,下面我们一起看下 Python 中初始化属性的方法 __init__( )
(1)__init__( )方法
类中的函数称作方法,__init__() 是一个特殊的方法,每当我们实例化一个对象时,这个方法都会自动执行。方法名的开头为两个下划线,结尾同样为两个下划线,这种命名的习惯主要是为了区分 Python 默认的方法名和我们自己定义的方法名。
def __init__(self, n, c, s): 语句中,参数 self 表示对象自身,代表实例化对象的引用。参数n, c, s则表示对象的属性,在我们创建的类 Bird 中就是表示,每一种鸟的具象化特征,比如鹦鹉、绿色、中等大小,因此 __init__()方法的作用是为对象的属性赋值。
参数 self 是必须的,并且要位于其他参数的前面。在方法的定义中,之所以要必须包含 self 参数,是因为当实例化对象时,会自动调用 __init__() 方法,并且自动传入参数 self。每个方法都可以包含一个会自动传入的参数 self,这个参数是实例化对象的引用。这样方法便可以访问对象的属性和方法。在实例化对象时,由于 self 参数自动传入的,所以只需要传入其他参数的值。
class Bird:
def __init__(self, n, c, s):
#对象初始化语句
self.name = n
self.color = c
self.size = s
__init__() 函数体中,赋值号左边的参数带有 self 前缀,带有 self 前缀的变量对于类中的每个方法来说都是可用的,而且也可以通过实例化的对象来访问这些变量。
- self.name = n 将参数 n 赋值给 name,name 便是实例化出来的对象的属性
- self.color = c 将参数 c 赋值给 color,color 便是实例化出来的对象的属性
- self.size = s 将参数 s 赋值给 size,size便是实例化出来的对象的属性
class Bird:
def get_description(self):
#定义方法get_description,参数为self,自动传入
description = f'{self.name} {self.color} {self.size} '
print(description)
这个方法由于不需要传入额外的信息,所以只要传入 self 参数,函数中定义了变量 description 和打印 description 的语句,当调用 get_description() 方法时,执行打印语句。
10.2、对象
类是用来描述具有相同的属性和方法的对象的集合,它定义了该集合中每个对象所共有的属性和方法。类是抽象的,对象是对类进行具象的实例化
10.2.1、实例化对象
在语句中,我们添加了一句 my_bird = Bird('鹦鹉', '绿色', '中等大小') 会实例化类 Bird 的一个对象 my_bird,在实例化的过程中,会调用 __init__() 方法
- 值
鹦鹉传递给参数 n - 值
绿色传递给参数 c - 值
中等大小传递给参数 s
#创建类Bird
class Bird:
#对象初始化语句
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
#定义方法get_description,参数为self,自动传入
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
#实例化对象my_bird,为my_bird赋予属性'鹦鹉', '绿色', '中等大小'
my_bird = Bird('鹦鹉', '绿色', '中等大小')
10.2.2、访问属性
访问属性的语法为:对象名.属性名
class Bird:
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
my_bird = Bird('鹦鹉', '绿色', '中等大小')
print(f"My bird's name is {my_bird.name}")
print(f"My bird's color is {my_bird.color}")
10.2.3、访问方法
访问方法的语法为:对象名.方法名
class Bird:
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
my_bird = Bird('鹦鹉', '绿色', '中等大小')
my_bird.get_description()
10.2.4、为属性设置默认值
我们在上述代码中添加了一个属性 age,并且将默认值设置成 1。并且添加一个方法 get_age() 用于获取属性 age 的值。
class Bird:
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
#设置属性age的默认值为1
self.age = 1
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
#定义获取属性age的方法
def get_age(self):
print(f"This bird is {self.age} ")
my_bird = Bird('鹦鹉', '绿色', '中等大小')
print(f"My bird's name is {my_bird.name}")
my_bird.get_description()
my_bird.get_age()
10.2.5、直接改变属性的值
我们也可以直接修改属性值,语法为:对象名.属性名 = 值
class Bird:
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
self.age = 1
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
def get_age(self):
print(f"This bird is {self.age} ")
my_bird = Bird('鹦鹉', '绿色', '中等大小')
my_bird.age = 3
my_bird.get_age()
10.2.6、通过方法改变属性的值
定义了一个改变属性值的方法 update_age(),通过调用 update_age()来改变属性的值。
class Bird:
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
self.age = 1
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
def get_age(self):
print(f"This bird is {self.age} ")
def update_age(self, a):
self.age = a
my_bird = Bird('鹦鹉', '绿色', '中等大小')
my_bird.update_age(5)
my_bird.get_age()
10.3、继承
在创建类时,不必每次都从零开始,假设我们想要创建的新类和已经创建过的类之间有一些共同的属性和方法,我们就可以从某个现有的类继承,新类称为子类,被继承的类称为父类。继承时,子类会获取父类的所有属性和方法,并且子类还可以定义自己的属性和方法。
子类的语法规则是:class 新类名(父类名),比如 class Penguin(Bird)就表示一个子类,父类为 Bird
10.3.1、子类的 __init__() 方法
在实例化子类的对象时,首先要为父类中的属性赋值,对父类属性的赋值可以使用父类的 __init__() 方法
class Bird:
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
self.age = 1
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
def get_age(self):
print(f"This bird is {self.age} ")
def update_age(self, a):
self.age = a
class Penguin(Bird):
def __init__(self, n, c, s):
super().__init__(n, c, s)
my_bird = Penguin('企鹅', '黑白', '大')
my_bird.get_description()
在上面的例子中,定义了一个新类 Penguin,新类继承自 Bird。在子类 Penguin 的 __init__() 方法中调用父类 Bird 的 __init__()方法对父类中的属性进行赋值。语句中的 super() 函数是用于调用父类的一个方法。
10.3.2、定义子类的属性和方法
我们也可以在子类中定义属性和方法,语法规则和在类中定义属性和方法的规则一致
class Bird:
def __init__(self, n, c, s):
self.name = n
self.color = c
self.size = s
self.age = 1
def get_description(self):
description = f'{self.name} {self.color} {self.size} '
print(description)
def get_age(self):
print(f"This bird is {self.age} ")
def update_age(self, a):
self.age = a
class Penguin(Bird):
def __init__(self, n, c, s):
super().__init__(n, c, s)
self.swimming_distance = 100
def get_swimming_distance(self):
print(f"企鹅可以游 {self.swimming_distance} 米.")
my_bird = Penguin('企鹅', '黑白', '大')
my_bird.get_description()
my_bird.get_swimming_distance()
为子类添加了属性 swimming_distance 和方法 get_swimming_distance(),通过访问属性和方法打印出相应的结果
11、模块和包
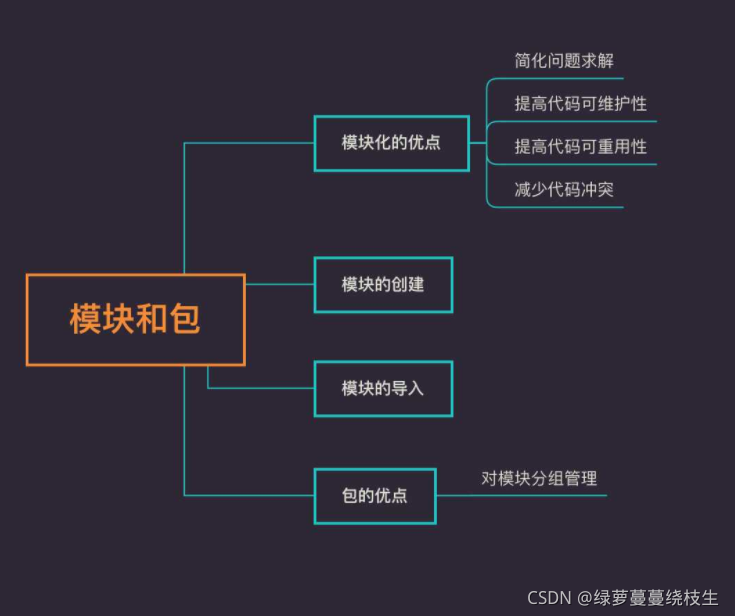
11.1、模块
Python 中,为了编写易于维护的代码,我们会将代码拆分放到不同的文件里,这样每个文件包含的代码相对就会减少。在 Python 中,一个 .py 文件称为一个模块(Module)。
模块化能够带来很多好处:
(1)简化问题求解
将所有代码放在一个文件中时,我们需要考虑的是整个问题的求解,代码实现的复杂度大大增加。将代码拆分放在多个文件中时,每个文件只需要对子问题进行求解,代码实现的复杂度大大降低。
(2)提高代码可维护性
由于解决不同子问题的代码放在了不同的文件中,代码之间的依赖性小,其中一个文件的修改对其他文件产生影响的几率大大降低。维护人员可以对其中一个文件的代码进行修改,而不必熟悉其他文件中的代码。由于每个文件专注于解决一个子问题,文件之间的并行开发成为可能。
(3)提高代码可重用性
一个模块编写完成后,可以被其他地方引用。我们在编写程序的时候,也可以引用其他模块,包括 Python 内置的模块和来自第三方的模块。这样就不需要重复造轮子。大大提高了代码的复用性和开发效率。
(4)减少代码冲突
模块提供了一个独立的命名空间,独立命名空间的好处是可以避免函数名和变量名冲突。相同名字的函数和变量可以放在不同的模块中。因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
11.1.1、模块的创建
模块的创建非常简单,一个 .py 文件便是一个模块(Module)。将下面的代码保存在 utils.py 文件中,这个操作是非常简单的,只需要我们创建一个文件名为 utils 的 py 文件,然后将代码复制到 utils 的 py 文件中就完成了一个模块的创建。
# utils.py模块
def max_num(a, b):
if a >= b:
return a
else:
return b
def min_num(a, b):
if a > b:
return b
else:
return a
这样我们便创建了一个名为 utils 的模块,在这个模块中,定义了两个函数: max_num和min_num ,两个函数分别为求两个数中的大数和小数。
11.1.2、模块的导入
11.1.2.1、import
模块创建完成后,可以使用 import 关键字来导入模块,例如:import utils
执行上述指令后,Python 首先会从自己内置模块中查找是否含有该模块的定义,若未查询到会从 sys.path 对应的模块路径查询是否含有对应模块的定义,如果搜索完成,仍然没有对应的模块时,则抛出 import 的异常。
也就是说当执行 import utils 这条指令时,Python 会从以下路径中搜索模块 utils.py 。
- 在当前目录下搜索该模块
- 在环境变量 PYTHONPATH 指定的路径列表中依次搜索
- 在 Python 安装路径的 lib 库中搜索
上述路径可以通过变量 sys.path 获得,该变量位于模块 sys 中。sys.path是 Python 的一个系统变量,是 Python 搜索模块的路径列表。其获取的方法如下:
import sys
print(sys.path)
为了让创建的模块能够被找到,需要将模块放到上述路径中的一个,因为 Python 只会在这些路径中去查找模块,如果没有将模块创建在这些路径中,则找不到对应的模块,也就没办法应用模块中的对象和方法了。
现在呢,我们想要去调用模块 utils 中的 max_num 和 min_num 方法,第一步为导入模块 utils,第二步为调用模块 utils 中的两个方法,具体语句如下:
#导入模块utils
import utils
print(utils.max_num(4, 5))
print(utils.min_num(4, 5))
我们看到为了调用模块中的函数 max_num 和 min_num,需要在函数名前面添加 utils. 前缀。如果不添加 utils. 前缀 ,则会报错。
11.1.2.2、from module_name import name(s)
直接导入模块中的对象,语法为:from 模块名 import 方法名
from utils import max_num, min_num
print(max_num(4, 5))
print(min_num(4, 5))
使用这种方式导入时,调用 max_num 和 min_num 函数便不需要添加前缀 utils.
有时候,为了方便,会使用 from module_name import * 来导入模块中的所有对象
from utils import *
print(max_num(4, 5))
print(min_num(4, 5))
11.1.2.3、from module_name import as alt_name
Python 中模块内的对象和方法也可以有自己的别名,实现语句为:from 模块名 import *** as 别名 ,该命令为导入的对象起一个别名。这样就可以通过别名来使用对象。
from utils import max_num as max_n, min_num as min_n
print(max_n(4, 5))
print(min_n(4, 5))
在上面的例子中,分别为 max_num,min_num 取了别名 max_n,min_n。这样在调用函数时,便可以使用 max_n,min_n
11.1.2.4、import module_name as alt_name
我们还可以为导入的整个模块起一个别名,这样便可以通过模块的别名来使用模块,使用方法是一样的,都是将 模块名. 作为前缀
import utils as ul
print(ul.max_num(4, 5))
print(ul.min_num(4, 5))
在上面的例子中,为模块 utils 取了别名 ul,这样在调用函数时,便可以使用 ul. 前缀
11.1.3、包含单个类的模块
我们一起来看下包含单个类的模块,我们创建一个模块(car.py),包含类 car ,语句如下:
class Car:
def __init__(self, mk, md, y, c):
self.make = mk
self.model = md
self.year = y
self.color = c
self.mileage = 0
def get_description(self):
description = f'{self.year} {self.color} {self.make} {self.model}'
print(description)
def get_mileage(self):
print(f"This car has {self.mileage} miles on it")
def update_mileage(self, mile):
self.mileage = mile
导入类(my_car.py):
from car import Car
my_car = Car('audi', 'a4', 2016, 'white')
my_car.get_description()
my_car.update_mileage(30)
my_car.get_mileage()
11.1.4、包含多个类的模块
我们创建模块(car.py),其中包含父类 car 和继承类 Electriccar ,语句如下:
class Car:
def __init__(self, mk, md, y, c):
self.make = mk
self.model = md
self.year = y
self.color = c
self.mileage = 0
def get_description(self):
description = f'{self.year} {self.color} {self.make} {self.model}'
print(description)
def get_mileage(self):
print(f"This car has {self.mileage} miles on it")
def update_mileage(self, mile):
self.mileage = mile
class ElectricCar(Car):
def __init__(self, mk, md, y, c):
super().__init__(mk, md, y, c)
self.battery_size = 100
def get_battery(self):
print(f"This car has {self.battery_size} -kWh battery.")
导入单个类(my_electirc_car.py):
from car import ElectricCar
my_tesla = ElectricCar('tesla', 'model 3', 2018, 'white')
my_tesla.get_description()
my_tesla.get_battery()
导入多个类(my_cars.py):
from car import ElectricCar, Car
my_car = Car('audi', 'a4', 2016, 'white')
my_car.update_mileage(30)
my_car.get_mileage()
my_tesla = ElectricCar('tesla', 'model 3', 2018, 'white')
my_tesla.get_description()
my_tesla.get_battery()
导入整个模块:
import car
my_car = car.Car('audi', 'a4', 2016, 'white')
my_car.update_mileage(30)
my_car.get_mileage()
my_tesla = car.ElectricCar('tesla', 'model 3', 2018, 'white')
my_tesla.get_description()
my_tesla.get_battery()
导入模块中的全部类:
from car import *
my_car = Car('audi', 'a4', 2016, 'white')
my_car.update_mileage(30)
my_car.get_mileage()
my_tesla = ElectricCar('tesla', 'model 3', 2018, 'white')
my_tesla.get_description()
my_tesla.get_battery()
11.2、包
Python 中的包实现了对模块分组管理的功能。包的创建非常简单,它利用了操作系统的分层文件结构。我们只要将模块放在一个目录下便可。
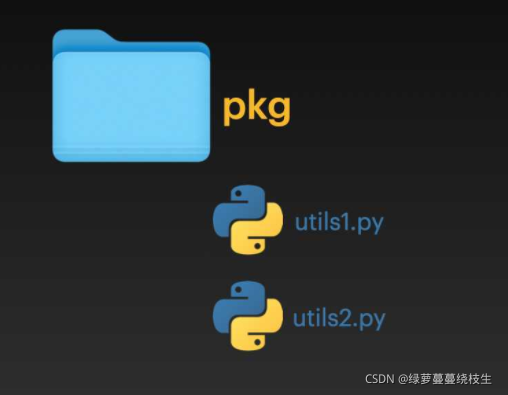
在上图中,目录 pkg 下有两个模块,utils1.py 和 utils2.py,pkg 便是一个包。(包相当于一个文件夹,模块则相当于文件夹中的文件)
两个模块中的语句如下:(语句相当于文件中的内容)
utils1.py
def max_num(a, b):
if a >= b:
return a
else:
return b
def min_num(a, b):
if a > b:
return b
else:
return a
utils2.py
def sum_num(a, b):
return a + b
def abs_num(a):
if a >= 0:
return a
else:
return -a
11.2.1、import module_name [, …]
导入包中的模块,语法规则为:import 包.模块名
import pkg.utils1
import pkg.utils2
print(pkg.utils1.max_num(4, 5))
print(pkg.utils2.sum_num(4, 5))
导入包 pkg 中的模块 utils1 和模块 utils2,并调用两个模块中的方法,将 pkg.utils1. 作为前缀放在 max_num() 方法前,表示是在 pkg 包中的模块 utils1 内的方法。
11.2.2、from package_name import modules_name[, …]
我们也可以通过 from 语句来实现模块的导入,我们一起看下方语句:
from pkg import utils1, utils2
print(utils1.max_num(4, 5))
print(utils2.sum_num(4, 5))
11.2.3、from module_name import name(s)
我们再来一起看下,定义包之后,导入指定模块中的对象,我们看下方语句:
from pkg.utils1 import max_num
print(max_num(4, 5))
11.2.4、from module_name import as alt_name
为模块内的对象和方法设置别名
from pkg.utils1 import max_num as max_n
print(max_n(4, 5))
11.2.5、from package_name import module_name as alt_name
为导入的整个模块设置别名
from pkg import utils1 as ul1
print(ul1.max_num(4, 5))
12、异常处理
12.1、什么是异常
在 Python 中,异常是在程序运行过程中发生的错误,当异常发生时,需要对异常进行处理,否则整个程序将崩溃。
print(1/0)
print("Done!")
例子中的 1 / 0 触发了 ZeroDivisionError 异常,由于没有对异常进行处理,导致了程序的崩溃,后面的语句没有再继续执行
12.2、异常的处理
当异常发生时,如果直接导致了程序的崩溃,不论对用户还是对开发者来说都是不友好的,这便要求我们在异常发生时,对异常进行处理。就像嫦娥一样,当发现品性不好的蓬蒙等人觊觎仙药时,为了阻止不好的情况发生,吞服了仙药,对异常进行了及时的处理。
12.2.1、try-except
try 和 except 语句块可以用来捕获和处理异常,try 后面跟的是需要捕获异常的代码,except 后面跟的是捕获到异常后需要做的处理。每一个 try 语句块后面必须跟上一个 except 语句块,即使 except 语句块什么也不做。
try:
print(1 / 0)
except ZeroDivisionError:
print("分母不能为0")
print("Done!")
try 语句块后面可以跟上多个 except 语句块
try:
print(1 / 0)
#除0异常
with open('test.log') as file:
#文件不存在异常
read_data = file.read()
except ZeroDivisionError:
print("ZeroDivisionError happened!")
except FileNotFoundError:
print("FileNotFoundError happened!")
print("Done!")
在执行代码 print(1 / 0) 时,发生了除 0 异常,所以没有执行后面的打开文件的代码,后面的异常处理代码输出了 ZeroDivisionError happened!
12.2.2、try-except-else
try-except 语句块后面可以跟上 else 语句块,当没有异常发生时,会执行 else 语句块中的代码
try:
print(1 / 1)
except ZeroDivisionError:
print("ZeroDivisionError happened!")
else:
print("Exception not happened")
print("Done!")
12.2.3、try-except-else-finally
try-except-else 语句块后面还可以跟上 finally 语句块,不管有没有发生异常,finally 语句块中的代码都会被执行
try:
print(1 / 1)
except ZeroDivisionError:
print("ZeroDivisionError happened!")
else:
print("Exception not happened")
finally:
print("Finally is executed!")
print("Done!")
12.3、抛出异常
前面讲的是异常出现时,可以做的处理。另外,我们也可以主动抛出异常。主动抛出异常使用 raise 关键字
x = 10
if x > 5:
raise Exception('x should not exceed 5. The value of x was: {}'.format(x))
当 x > 5 时,主动抛出异常

















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









