







Redis分片集群启动分析
分片集群为6个节点,备份方式AOF和RDB都已经开启

节点启动log分析
1:C 08 May 2023 05:34:52.156 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
#版本信息
1:C 08 May 2023 05:34:52.156 # Redis version=7.0.5, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 08 May 2023 05:34:52.156 # Configuration loaded
1:M 08 May 2023 05:34:52.157 * monotonic clock: POSIX clock_gettime
#集群信息没找到
1:M 08 May 2023 05:34:52.157 * No cluster configuration found, I'm 5d53941e8850d538fcbc98d6580bb29cd66ed827
#启动模式是集群模式
1:M 08 May 2023 05:34:52.163 * Running mode=cluster, port=7004.
1:M 08 May 2023 05:34:52.163 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1:M 08 May 2023 05:34:52.163 # Server initialized
1:M 08 May 2023 05:34:52.163 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
#这是Redis数据库在启动时创建AOF(Append Only File)文件的输出。AOF文件是一种持久化存储方式,它记录了所有修改Redis数据库的命令,这样即使服务器重启或崩溃,也可以通过重新执行AOF文件中的命令来恢复数据。
该输出表示Redis正在创建AOF文件,并且将其分成两个部分:一个基础文件(appendonly.aof.1.base.rdb)和一个增量文件(appendonly.aof.1.incr.aof)。基础文件包含了所有之前已经执行的AOF日志命令,而增量文件则会包含从Redis启动时开始新增、修改或删除的命令。这种方式可以减少在重启服务器时必须执行的命令数量,从而提高恢复速度。
1:M 08 May 2023 05:34:52.167 * Creating AOF base file appendonly.aof.1.base.rdb on server start
1:M 08 May 2023 05:34:52.174 * Creating AOF incr file appendonly.aof.1.incr.aof on server start
1:M 08 May 2023 05:34:52.174 * Ready to accept connections
目录变化,data文件夹下新增两个文件,

nodes.conf文件是Redis集群中的一个配置文件,它包含了用于描述各个节点的IP地址、端口号、节点ID等信息。
该文件主要用于Redis集群节点之间的通信和协同工作,它通常位于集群中的每个节点上,并且包含以下内容:
- 节点IP地址和端口号:这些信息是用于节点间通信的关键,每个节点都必须配置正确才能正常运行。
- 节点ID:Redis集群需要为每个节点分配一个唯一的ID,以便在处理故障时能够准确识别出哪个节点出了问题。
- 从属关系:对于Redis集群中的主/从模式,
nodes.conf文件还需要指定每个从节点所属的主节点是哪一个。 - 槽位分配:在Redis集群中,数据通常被分成多个槽位(slot),每个槽位可以存储一部分数据。
nodes.conf文件需要指定哪些槽位由哪些节点负责管理。 - 其他配置参数:除了上述信息外,
nodes.conf文件还可以包含其他一些配置参数,如密码、超时时间等等。
现在只是6个节点,没有创建集群关系,所以里面只有一个节点的信息,每个节点的nodes.conf文件全是master,而且没有分配散列插槽

appendonlydir是AOF文件存放的目录
appendonly.aof.manifest:Redis 6.2版本新增的文件,用于记录AOF文件和RDB文件之间的对应关系。
appendonly.aof.1.base.rdb:基础文件
appendonly.aof.1.incr.aof:增量文件
现在给7002节点添加数据时发现无法添加数据,原因是没有分配插槽

查看集群状态和节点信息,发现集群状态是fail,节点数量只有1个

现在连接7002客户端创建集群,replicas为1,6个节点的话就是3个master,3个slave,插槽分配的话是3个master大致平均分配,前3个ip作为master,分配slave的master则是随机
redis-cli --cluster create --cluster-replicas 1 192.168.24.61:7001 192.168.24.61:7002 192.168.24.61:7003 192.168.24.61:7004 192.168.24.61:7005 192.168.24.61:7006
#在6个节点上执行散列槽分配
>>> Performing hash slots allocation on 6 nodes...
#主节点插槽分配情况
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
#主从关系确定
Adding replica 192.168.24.61:7005 to 192.168.24.61:7001
Adding replica 192.168.24.61:7006 to 192.168.24.61:7002
Adding replica 192.168.24.61:7004 to 192.168.24.61:7003
#尝试优化主从关系
>>> Trying to optimize slaves allocation for anti-affinity
#这是Redis Sentinel的一个警告信息,表示一些Redis从节点(slaves)与它们的主节点(master)部署在同一台物理服务器上,这可能会导致单点故障。如果主节点所在的服务器遇到故障或崩溃,那么同一台服务器上的从节点也将无法正常工作。为了确保高可用性和可靠性,最好将Redis主节点和从节点分别部署在不同的物理服务器上或者虚拟机上。这样可以避免单点故障,并且使整个系统更加健壮和可靠。
[WARNING] Some slaves are in the same host as their master
#各节点信息和主从关系
M: f696a921c9e09e0a16f5230cdc26cf47f2b1401d 192.168.24.61:7001
slots:[0-5460] (5461 slots) master
M: 4d3093da35bf421ff6962736a0c16fedebbab5dd 192.168.24.61:7002
slots:[5461-10922] (5462 slots) master
M: 400fdfa3e083ff630aa519eb8366205bf9d57b1d 192.168.24.61:7003
slots:[10923-16383] (5461 slots) master
S: 5d53941e8850d538fcbc98d6580bb29cd66ed827 192.168.24.61:7004
replicates 400fdfa3e083ff630aa519eb8366205bf9d57b1d
S: 317e734522d02740163ecb7c897093990086a542 192.168.24.61:7005
replicates f696a921c9e09e0a16f5230cdc26cf47f2b1401d
S: 774a5ca1d4296278800a9a6257c35a629174e7fc 192.168.24.61:7006
replicates 4d3093da35bf421ff6962736a0c16fedebbab5dd
#是否同意上述生成的配置,同意输入yes
Can I set the above configuration? (type 'yes' to accept):
“配置纪元”(configEpoch)是Redis集群中一个用于判断节点优先级和处理故障转移的重要参数。在Redis集群中,所有节点都可以拥有相同的数据副本,但只有一个节点被允许作为主节点进行写操作。如果主节点出现故障,Redis集群需要从备份节点中选举新的主节点来负责写操作。
为了确保选举过程的正确性和一致性,Redis集群使用配置纪元来判断每个备份节点的优先级。具体来说,每个Redis集群节点都有一个维护自己状态信息的configEpoch值。当一个备份节点试图竞选成为主节点时,它会将自己的configEpoch值发送给其他备份节点,并等待其他备份节点的响应。如果其他备份节点认为这个备份节点具有更高优先级,则会将自己的configEpoch更新为更高值,并发送响应消息给该备份节点。
输入yes后
Can I set the above configuration? (type 'yes' to accept): yes
#更新节点配置
>>> Nodes configuration updated
#为每个节点分配不同的配置纪元
>>> Assign a different config epoch to each node
#发送CLUSTER MEET消息加入集群
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
#执行集群检查,使用的是7001节点(随机选择),下面是节点信息
>>> Performing Cluster Check (using node 192.168.24.61:7001)
M: f696a921c9e09e0a16f5230cdc26cf47f2b1401d 192.168.24.61:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 5d53941e8850d538fcbc98d6580bb29cd66ed827 192.168.24.61:7004
slots: (0 slots) slave
replicates f696a921c9e09e0a16f5230cdc26cf47f2b1401d
M: 4d3093da35bf421ff6962736a0c16fedebbab5dd 192.168.24.61:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 400fdfa3e083ff630aa519eb8366205bf9d57b1d 192.168.24.61:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 774a5ca1d4296278800a9a6257c35a629174e7fc 192.168.24.61:7006
slots: (0 slots) slave
replicates 400fdfa3e083ff630aa519eb8366205bf9d57b1d
S: 317e734522d02740163ecb7c897093990086a542 192.168.24.61:7005
slots: (0 slots) slave
replicates 4d3093da35bf421ff6962736a0c16fedebbab5dd
#所有节点都同意槽位配置
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
#覆盖所有16384个插槽
[OK] All 16384 slots covered.
最开始的主从关系是:
7001-》7005
7002-》7006
7003-》7004
自动优化后方案:
7001-》7004
7002-》7005
7003-》7006
此时观察其他节点log,比如7002主节点的日志
#原来的启动log
1:C 08 May 2023 05:24:04.207 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C 08 May 2023 05:24:04.207 # Redis version=7.0.5, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 08 May 2023 05:24:04.207 # Configuration loaded
1:M 08 May 2023 05:24:04.209 * monotonic clock: POSIX clock_gettime
1:M 08 May 2023 05:24:04.210 * No cluster configuration found, I'm 4d3093da35bf421ff6962736a0c16fedebbab5dd
1:M 08 May 2023 05:24:04.215 * Running mode=cluster, port=7002.
1:M 08 May 2023 05:24:04.215 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1:M 08 May 2023 05:24:04.215 # Server initialized
1:M 08 May 2023 05:24:04.215 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
1:M 08 May 2023 05:24:04.220 * Creating AOF base file appendonly.aof.1.base.rdb on server start
1:M 08 May 2023 05:24:04.226 * Creating AOF incr file appendonly.aof.1.incr.aof on server start
1:M 08 May 2023 05:24:04.226 * Ready to accept connections
#创建集群后新增的log
#Redis正在通过执行CLUSTER SET-CONFIG-EPOCH命令将configEpoch设置为2
1:M 08 May 2023 06:38:46.581 # configEpoch set to 2 via CLUSTER SET-CONFIG-EPOCH
#从节点请求同步数据,Redis主从复制中的从节点(Replica)172.17.0.1:7005正在请求进行同步操作。在主从复制中,主节点持续地将自己的数据更新发送给从节点,以保证从节点上的数据与主节点保持同步。
1:M 08 May 2023 06:38:48.590 * Replica 172.17.0.1:7005 asks for synchronization
#这是Redis增量过程中的错误日志。错误消息表示,由于ReplicationID不匹配,部分重新同步的请求被拒绝。
1:M 08 May 2023 06:38:48.590 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'f0ab9c8ea54be6d09c1be866ed85e0da7c21571f', my replication IDs are '0a1ac831d035d43ddac5ec56f4d277d618ba9284' and '0000000000000000000000000000000000000000')
#创建新的replication ID并发送给从节点
1:M 08 May 2023 06:38:48.590 * Replication backlog created, my new replication IDs are '0be710f4c78c7de83471dd19fa2240b83ff289da' and '0000000000000000000000000000000000000000'
#开始执行BGSAVE命令生成RDB快照文件
1:M 08 May 2023 06:38:48.590 * Delay next BGSAVE for diskless SYNC
1:M 08 May 2023 06:38:51.560 # Cluster state changed: ok
#表示主服务器开始执行后台保存操作,用于为从服务器进行全量同步准备RDB文件。
1:M 08 May 2023 06:38:53.366 * Starting BGSAVE for SYNC with target: replicas sockets
#表示Redis正在后台进行RDB文件的转移操作,“pid 30”表示负责执行BGSAVE操作的进程ID号
1:M 08 May 2023 06:38:53.366 * Background RDB transfer started by pid 30
#在Redis进行RDB转储操作时,它会使用一个新的子进程来执行这个任务。当子进程需要复制父进程内存内容时,如果有多个进程共享相同的内存资源,则会采用写时复制(Copy-on-Write,CoW)技术来减少内存开销。CoW技术可以避免不必要的内存拷贝操作,并且可以将多个子进程指向相同的物理页面,从而节省系统资源。“current”,“peak”和“average”分别表示当前、峰值和平均值。
30:C 08 May 2023 06:38:53.367 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
#“done reading from pipe”表示主服务器已经读取完整个RDB文件,并将其传输到从服务器上;“1 replicas still up”表示当前有一个从服务器仍然处于连接状态
1:M 08 May 2023 06:38:53.367 # Diskless rdb transfer, done reading from pipe, 1 replicas still up.
1:M 08 May 2023 06:38:53.374 * Background RDB transfer terminated with success
#RDB文件使用socket套接字成功地从主服务器传输到了IP地址为172.17.0.1、端口号为7005的从节点,正在等待从服务器的确认消息,以便启用数据流式同步机制
1:M 08 May 2023 06:38:53.374 * Streamed RDB transfer with replica 172.17.0.1:7005 succeeded (socket). Waiting for REPLCONF ACK from slave to enable streaming
#同步成功
1:M 08 May 2023 06:38:53.374 * Synchronization with replica 172.17.0.1:7005 succeeded
Partial resynchronization not accepted: Replication ID mismatch (Replica asked for ‘f0ab9c8ea54be6d09c1be866ed85e0da7c21571f’, my replication IDs are ‘0a1ac831d035d43ddac5ec56f4d277d618ba9284’ and ‘0000000000000000000000000000000000000000’)
由于集群是第一次启动,没有通讯过,replication ID对应不上。主从第一次同步需要全量同步,但是从节点发送的是增量同步的命令,master判断是第一次来同步数据,因此触发的还是全量更新
master如何判断slave是不是第一次来同步数据?这里会用到两个参数:
•Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
•offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据
Delay next BGSAVE for diskless SYNC
Delay next BGSAVE for diskless SYNC是一个针对从服务器的优化配置项。它指定了当从服务器通过没有磁盘持久化的方式进行复制(比如使用SYNC命令或者AOF方式),并且主服务器正在执行后台保存操作(BGSAVE命令)时,是否需要延迟下一次后台保存操作。
这个配置项的默认值为yes,也就是如果从服务器使用了diskless SYNC,则不会在主服务器执行BGSAVE命令之后立即进行下一次后台保存操作。这是因为在diskless SYNC模式下,数据只存在于主服务器内存中,并没有通过磁盘持久化到文件中。如果此时主服务器进行了BGSAVE操作,会将所有数据都写入磁盘文件中,导致短时间内出现大量IO操作,影响系统性能。
Starting BGSAVE for SYNC with target: replicas sockets
表示主服务器开始执行后台保存操作,用于为从服务器进行全量同步准备RDB文件。
这个日志提示除了显示BGSAVE命令启动外,还额外指定了一个同步目标:replicas sockets,即从服务器的套接字连接。这个提示信息表明,在进行全量同步时,主服务器正在创建一个RDB快照文件,并将其传输给所有连接的从服务器。而在传输完毕之前,如果有新的写操作执行,则会将这些操作记录到内存缓冲区中,并在BGSAVE完成后保存到AOF文件中。
需要注意的是,在执行BGSAVE命令时,Redis会将所有新的写操作都保存到内存缓冲区中。而当BGSAVE完成后,Redis会根据内存缓冲区中的写操作更新AOF和RDB文件。因此,在进行全量同步时,我们可以选择使用AOF文件或者RDB文件作为数据源。具体使用哪种方式取决于应用程序和系统要求。
总之,Starting BGSAVE for SYNC with target: replicas sockets这个日志提示信息是Redis进行全量同步时非常重要的组成部分之一。它向用户展示了Redis正在执行什么样的操作,并提醒用户系统当前状态是否正常。
7002节点的从节点是7005,看一下7005在集群创建时的动作
#原来的启动log
1:C 08 May 2023 05:45:43.848 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C 08 May 2023 05:45:43.848 # Redis version=7.0.5, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 08 May 2023 05:45:43.848 # Configuration loaded
1:M 08 May 2023 05:45:43.849 * monotonic clock: POSIX clock_gettime
1:M 08 May 2023 05:45:43.850 * No cluster configuration found, I'm 317e734522d02740163ecb7c897093990086a542
1:M 08 May 2023 05:45:43.855 * Running mode=cluster, port=7005.
1:M 08 May 2023 05:45:43.855 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1:M 08 May 2023 05:45:43.855 # Server initialized
1:M 08 May 2023 05:45:43.855 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
1:M 08 May 2023 05:45:43.860 * Creating AOF base file appendonly.aof.1.base.rdb on server start
1:M 08 May 2023 05:45:43.868 * Creating AOF incr file appendonly.aof.1.incr.aof on server start
1:M 08 May 2023 05:45:43.868 * Ready to accept connections
#集群创建时新增的log
#Redis正在通过执行CLUSTER SET-CONFIG-EPOCH命令将configEpoch设置为5
1:M 08 May 2023 06:38:46.582 # configEpoch set to 5 via CLUSTER SET-CONFIG-EPOCH
#集群没创建之前该节点是主节点,现在要转化为从节点,首先会为该节点创建一个缓存节点,后面变为从节点和主节点去数据同步时,有些数据就可以直接从缓存节点同步,可以提高同步速度和减少网络带宽的使用
1:S 08 May 2023 06:38:48.588 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
#连接主节点
1:S 08 May 2023 06:38:48.588 * Connecting to MASTER 192.168.24.61:7002
#主从数据同步
1:S 08 May 2023 06:38:48.588 * MASTER <-> REPLICA sync started
#集群状态OK
1:S 08 May 2023 06:38:48.589 # Cluster state changed: ok
#异步同步数据时打印的一条日志消息。这条消息表明Redis正在使用非阻塞方式连接到主节点以进行同步,并且已经触发了相应的事件。Redis使用异步方式进行同步以提高性能,并允许其他操作在同步期间继续执行。与此同时,Redis还会监控主节点的状态,以确保同步过程顺利完成并且数据正确。
1:S 08 May 2023 06:38:48.589 * Non blocking connect for SYNC fired the event.
#这是Redis复制过程中输出的一条日志信息。该消息表示主节点成功响应了从节点发送的PING命令,并确认复制可以继续进行。
1:S 08 May 2023 06:38:48.589 * Master replied to PING, replication can continue...
#从节点请求增量同步,发送的是ReplicationID和序列号(不是偏移量)
1:S 08 May 2023 06:38:48.589 * Trying a partial resynchronization (request f0ab9c8ea54be6d09c1be866ed85e0da7c21571f:1).
#主节点判断是第一次同步,于是开始全量同步,使用的ReplicationID是主节点重新生成发送过来的,0是偏移量
1:S 08 May 2023 06:38:53.366 * Full resync from master: 0be710f4c78c7de83471dd19fa2240b83ff289da:0
#使用主节点的RDB文件进行全量同步
1:S 08 May 2023 06:38:53.367 * MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF to disk
#丢弃之前缓存的主服务器状态信息
1:S 08 May 2023 06:38:53.367 * Discarding previously cached master state.
#主节点和从节点正在进行同步,Redis正在清除旧数据并将数据库加载到内存中。显示正在加载一个由版本7.0.5生成的RDB文件,RDB文件的年龄为0秒,这意味着文件是最新的,并且Redis正在首次加载它。Redis实例使用了1.78 Mb的内存来保存数据库的快照
1:S 08 May 2023 06:38:53.367 * MASTER <-> REPLICA sync: Flushing old data
1:S 08 May 2023 06:38:53.368 * MASTER <-> REPLICA sync: Loading DB in memory
1:S 08 May 2023 06:38:53.373 * Loading RDB produced by version 7.0.5
1:S 08 May 2023 06:38:53.373 * RDB age 0 seconds
1:S 08 May 2023 06:38:53.373 * RDB memory usage when created 1.78 Mb
#表示Redis已经完成了RDB文件的加载,并且在加载期间没有发现任何键或键的过期。因此,日志显示“keys loaded: 0, keys expired: 0”,这表示Redis从RDB文件中加载了0个键,并且在加载期间没有发现任何已过期的键
1:S 08 May 2023 06:38:53.373 * Done loading RDB, keys loaded: 0, keys expired: 0.
#主从同步完成
1:S 08 May 2023 06:38:53.373 * MASTER <-> REPLICA sync: Finished with success
#表示它正在后台创建一个AOF增量文件'temp-appendonly.aof.incr',该文件包含从当前AOF文件创建新AOF文件期间写入的所有命令
1:S 08 May 2023 06:38:53.373 * Creating AOF incr file temp-appendonly.aof.incr on background rewrite
1:S 08 May 2023 06:38:53.374 * Background append only file rewriting started by pid 19
#表示它已经成功创建了一个临时的AOF基础文件'temp-rewriteaof-bg-19.aof',这个文件包含了重写过程中已经完成的操作,作为新AOF文件的基础。在AOF重写期间,Redis会将重写过程中执行的所有命令追加到临时文件中,直到完成重写。完成后,Redis会将临时文件重命名为新的AOF文件名,并开始使用它来记录写操作。这个过程可以确保不会丢失任何数据,因为Redis在重写期间会一直追加新的命令到临时文件中,而在完成后再使用新文件来代替旧文件。
19:C 08 May 2023 06:38:53.377 * Successfully created the temporary AOF base file temp-rewriteaof-bg-19.aof
19:C 08 May 2023 06:38:53.377 * Fork CoW for AOF rewrite: current 0 MB, peak 0 MB, average 0 MB
1:S 08 May 2023 06:38:53.466 * Background AOF rewrite terminated with success
#成功将临时的AOF基础文件'temp-rewriteaof-bg-19.aof'重命名为'appendonly.aof.2.base.rdb'。这个文件包含了AOF重写期间执行的所有命令,并作为新的AOF文件的基础
1:S 08 May 2023 06:38:53.466 * Successfully renamed the temporary AOF base file temp-rewriteaof-bg-19.aof into appendonly.aof.2.base.rdb
1:S 08 May 2023 06:38:53.466 * Successfully renamed the temporary AOF incr file temp-appendonly.aof.incr into appendonly.aof.2.incr.aof
1:S 08 May 2023 06:38:53.472 * Removing the history file appendonly.aof.1.incr.aof in the background
1:S 08 May 2023 06:38:53.472 * Removing the history file appendonly.aof.1.base.rdb in the background
#AOF重写完成
1:S 08 May 2023 06:38:53.480 * Background AOF rewrite finished successfully
第一次全量同步的过程:
- 从节点向主节点发送SYNC命令,请求进行同步。
- 主节点接收到SYNC命令后,会执行BGSAVE命令生成一个RDB文件。在生成RDB文件期间,主节点将会停止处理所有写命令请求,并将这些命令缓存在内存中的缓冲区。
- 当BGSAVE命令执行完毕,主节点将会将生成的RDB文件发送给从节点,并将缓冲区中记录的所有写操作命令发送给从节点。
- 从节点接收到RDB文件和写操作命令后,会丢弃所有旧数据,并开始执行所有写操作命令。在执行这些写操作命令期间,从节点将不会处理来自客户端的任何请求。
- 当从节点追上主节点的数据时,主节点会将缓冲区中的写操作命令发送给从节点,以确保从节点保持最新的数据。
- 当缓冲区中的所有写操作命令都被传输给从节点并执行后,主节点和从节点之间的同步完成。
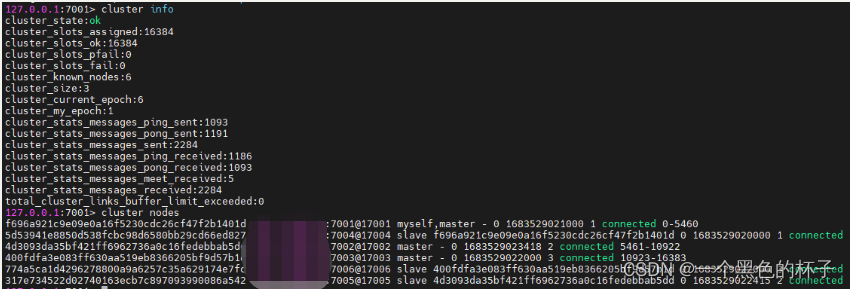
再次查看redis集群状态,状态为ok,有效节点(主节点,有插槽)3个,节点数量6个

















 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









