




AI时代下,学习如何使用和管理GPU是基础入门技能,本文以常见的NVIDIA GPU为例,介绍在普通机器、Docker和Kubernetes等不同的环境下如何使用和管理GPU。
一、概述
以常见的NVIDIA GPU为例,系统为Linux
1.1 裸机环境BMS
安装对应的GPU Driver(GPU驱动),以及CUDA Toolkit
1.2 Docker环境
需额外安装nvidia-container-toolkit,配置docker使用nvidia-runtime
1.3 Kubernetes环境
需额外安装对应的device-plugin,使得kubelet能感知到节点上的GPU设备
备注:一般在k8s环境,直接使用gpu-operator方案安装
二、Docker环境
2.1 安装Docker环境及配置
Docker容器中使用GPU,大致包括以下三步:
Step1 安装 nvidia-container-toolkit 组件
Step2 Docker 配置使用 nvidia-runtime
Step3 启动容器时增加 --gpu 参数
接下来,我们逐一展开
2.2 安装nvidia-container-toolkit
用途:NVIDIA Container Toolkit主要作用,将NVIDIA GPU设备挂载到容器中
NVIDIA兼容了主流容器运行时
-
Docker
-
Containerd
-
Cri-o
2.2.1 官方安装文档
参考NVIDIA官方安装文档执行即可
Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.17.3 documentation
2.3 配置使用该Runtime
支持Docker,Containerd,CRI-O,Podman等CRI
官方文档
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#configuration
2.4 以Docker为例配置
2.4.1 旧版Toolkit配置
旧版本,手动在 /etc/docker/daemon.json 增加配置,指定使用的 nvidia 的 runtime
"runtimes":{
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}2.4.2 新版Toolkit配置
新版toolkit自带一个nvidia-ctk 工具,执行以下命令可一键配置
sudo nvidia-ctk runtime configure --runtime=docker重启Docker即可
sudo systemctl restart docker2.5 测试安装效果
安装 nvidia-container-toolkit后 ,整个调用链如下
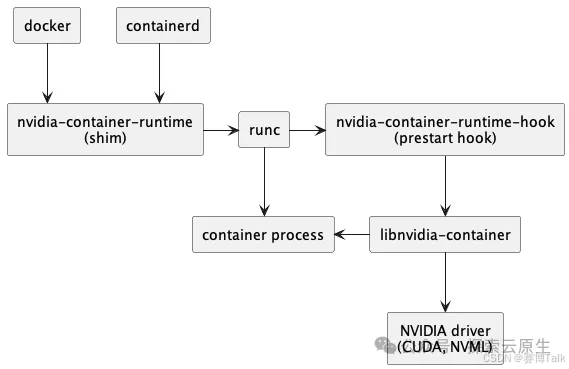
安装前-调用链
containerd --> runC安装后-调用链
containerd --> nvida-containerd-runtime --> runC2.5 Docker环境中CUDA调用过程
2.5.1 调用原理
1 Nvidia-containerd-runtime 中间拦截 容器spec
2 把GPU相关配置添加进去
3 再传给runC的spec里面就包含GPU信息
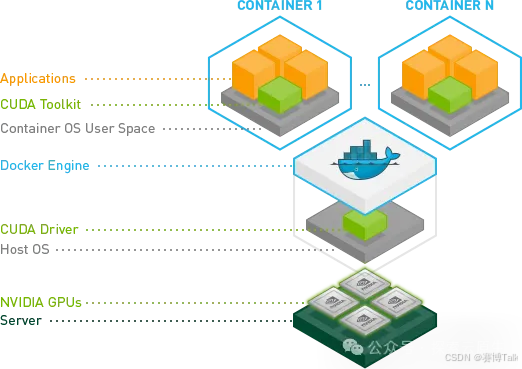
2.5.2 对比裸机方案
对比于裸机方案,CUDA Toolkit跑在容器里,宿主机不需要再安装CUDA Toolkit(容器内使用一个带CUDA Toolkit镜像即可)
2.6 启动Docker容器测试
2.6.1 --gpus 启动参数
启动命令增加 --gpu 参数指定要分配给容器的GPU
--gpu 可选参数
--gpus all #分配节点上所有GPU给该容器
--gpus “device=0,1,2,..” #指定id编号将GPU分配给容器
2.6.2 NVIDIA GPU命令行管理程序
执行nvidia-smi可监控和管理NVIDIA GPU状态和性能,可查看GPU设备编号
nvidia-smi #NVIDIA GPU命令行管理2.6.3 带cuda镜像测试
docker run --rm --gpus all nvidia/cuda:12.0.1-runtime-ubuntu22.04 nvidia-smiDocker运行环境和GPU设备正常情况下,可打印出容器中的GPU信息
结语
至此,我们已完成安装nvidia-container-toolkit,并配置Docker为Runtime环境的过程,下篇文章将介绍如何在Kubernetes环境安装及使用GPU,敬请期待噢~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









