






* Redis键(key)
* keys* # 查看当前库所有key(匹配:keys"1)
* exists key # 判断某个key是否存在.
* type key # 查看你的key是什么类型.
* del key # 删除指定的key 数据.
unlink key根据value选择非阻塞删除
仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
expire key 10 10秒钟:为给定的key设置过期时间
ttl key查看还有多少秒过期,-1表示永不过期,-2表示已过期.
select命令切换数据库.
dbsize查看当前数据库的key的数量.
flushdb清当前库.
flushall通杀全部库.I"
Redis Lpush 命令将一个或多个值插入到列表头部。 如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。 当 key 存在但不是列表类型时,返回一个错误。
注意:在Redis 2.4版本以前的 LPUSH 命令,都只接受单个 value 值。
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
集合对象的编码可以是 intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
GETRANGE KEY 0 -1 #获取全部的字符串
GETRANGE KEY 0 3 #截取字符串 [0,3]
SETRANGE KEY XX #替换指定位置开始的字符串
1. lpush
在key对应 list的头部添加字符串元素
2. rpush
在key对应 list 的尾部添加字符串元素
3. linsert
在key对应 list 的特定位置之前或之后添加字符串元素
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
1. Sadd
#向SET中添加一个元素
2. SMEMBERS
#查询指定set的所有值
3. SISMEMBER
#判断某一个值是不是set集合中
4. SCARD
#获取set集合中的内容元素个数!
5. SREM
#移除set集合中的指定元素
6. SET
无序不重复集合,抽随机!
7. SRANDMEMBE
#随机抽选出一个元素
8. SRANDMEMBE SET
*随机抽选出指定个数的元素
9. SRANDMEMBER
随机抽出一个元素
10. SPOP
#随机删除一些set集合中的元素
SMOVE myset1 myset2 #将一个指定的值,移动到另外一个SET集合
SDIFF key1 key2 #差集 !只针对于SET
SINTER key1 key2 #交集
SUNION key1 key2 #并集
Hash(哈希)
Map集合,key-map!时候这个值是一个map集合!本质和String类型没有太大区别,还是一个简单的key-value
set myhash field hukai
hset myhash field1 hukai #set一个具体key-value
hmset myhash field1 hello field2 world # set一个具体的key-value
hget myhash field1 #获取一个字段值
hmget myhash field1 field2 #获取多个字段值
hgetall myhash #获取全部的数据
hdel myhash field1 #删除hash指定key字段!对应的value信息也会消失
hlen myhash #获取哈市表的字段长度
hexists myhash field1 #判断hash中的指定字段是否存在
hkeys myhash #获取所有的字段
hvals myhash #获取所有的字段值
hset myhash field3 5 # 指定增量
HINCRBY myhash field3
hsetnx myhash field4 hello #如果不存在则可以设置
hsetnx myhsh field4 world #如果存在则不能设置
Hash变更的数据 user\name\,尤其是用户信息的保存,或者是变动的信息,hash更适合对象的存储,String更适合字符串存储。
Zset(有序集合)
在Set的基础上,增加了一个值 SET K1
zadd myset 1 one #添加一个值
(integer) 1
zadd myset 2 two 3 three #添加多个值
(integer) 2
zrange myset 0 -1
1) "one"
2) "two"
3) "three"
###########
排序如何实现
zadd salary 2500 zhangsan
(integer) 1
zadd salary 5000 lisi
(integer) 1
zadd salary 500 wangwu
(integer) 1
zrangebyscore salary -inf +inf #显示全部用户从小到大
1) "wangwu"
2) "zhangsan"
3) "lisi"
zrevrange salary 0 -1 #从大到小进行排序
zrangebyscore salary -inf +inf withscores #显示全部用户并且附带薪水
1) "wangwu"
2) "500"
3) "zhangsan"
4) "2500"
5) "lisi"
6) "5000"
zrangebyscore salary -inf 2500 withscores #显示工资小于2500员工的升序排序
1) "wangwu"
2) "500"
3) "zhangsan"
4) "2500"
#####
移除rem中的元素
zrem salary xiaohong #移除有序集合中的元素
zcard salary #查看有序集合中的元素
案例思路: Set排序,存储班级成绩表,工资表排序!
普通消息 1.重要消息 2.带权重进行判断
排行榜应用实现,取Top N测试
三种特殊的数据类型
Redis的Geo在Reds3.2版本就推出了!这个功能可以推算地理位置的信息,两地之间的距离,方圆几里的人!
可以查询一些测试数据;http://www,isons.cn/ingcodeinfo/0706099c19A781A3
GETADD
#GETADD 添加地理位置
#规则:两级无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入群参数key
#geoadd china:city 39.90 116.40 beijing
(error) ERR invalid longitude,latitude pair 39.900000,116.400000
#参数 key(纬度、经度、名称)
geoadd china:city 116.40 39.90 beijing 121.47 31.23 shanghai 106.50 29.53 chongqing
(integer) 3
geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 2
GEOPS
geopos china:city beijing #获取城市的经纬度
1) "116.39999896287918091"
2) "39.90000009167092543"
geopos china:city beijing chongqing
1) "116.39999896287918091"
2) "39.90000009167092543"
1) "106.49999767541885376"
2) "29.52999957900659211"
GEODIST
两人之间的距离!单位:
* m表示单位为米
* km表示单位为千米
* mi表示单位为英里
* ft表示单位为英尺
GEODIST china:city beijing shanghai km #查看北京到上海的直线距离
GEODIST china:city beijing chongqi km #查看北京到上海的直线距离,换算成千米
GEORADIUS
georadius china:city 110 30 1000 km
1) "chongqing"
2) "xian"
3) "hangzhou"
georadius china:city 110 30 500 km
1) "chongqing"
2) "xian"
georadius china:city 110 30 500 km withdist
1) 1) "chongqing"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
GEORADUISBYMEMBER
GEO底层的实现原理其实就是Zset!我们可以使用Zset命令来操作GEO
zrange china:city 0 -1 #查看地图中的全部元素
1) "chongqing"
2) "xian"
3) "hangzhou"
4) "shanghai"
5) "beijing"
zrem china:city beijing #移除地图中的指定元素
(integer) 1
zrange china:city 0 -1
1) "chongqing"
2) "xian"
3) "hangzhou"
4) "shanghai"
Hyperloglog
什么是基数?
A{1.3.5.7.8}
B{1.3.5.7.8}
基数(不重复的元素)=5,可以接受误差!
简介
- Redis2.8.9更新了Hyperloglog数据结构
- Redis Hyperloglog 基数统计的算法
- 优点: 占用的内存是固定,2^64不同的元素的技术,只需要废12kb内存,如果要从内存角度比较的话Hyperloglog首选!
测试使用
pfadd mykey a b c d e f g h i j #创建第一组元素 mykey
(integer) 1
pfcount mykey #统计mykey元素中的基数数量
(integer) 10
pfadd mykey2 i j z x c v b n m #创建第二组 mykey2
(integer) 1
pfcount mykey2
(integer) 9
PFMERGE mykey3 mykey mykey2 #合并两组 mykey mykey2 ==》 mykey3
OK
pfcount mykey3 #查看并集的数量
(integer) 16
网页的UV(一个人访问一个网站多次,但是还是算作一个人)
传统的方式,set保存的用户id,然后可以统计set中的元素数量作为标准判断!
这个方式如果保存大量的用户id,就会比较麻烦!我们的目的是为了计数,而不是保存用户id;
Bitmaps
位存储
- 统计疫情感染人数: 0 1 01 1 0 1
- 统计用户信息,活跃,不活跃,登录,未登录
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LWqRuoo1-1652357809803)(https://gitee.com/kai98/Album/raw/master/2022-1-13/1642056550977-image.png)]
事务
Redis事务本质:一组命令的集合@一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行!
一次性,顺序性,排他性!执行一些列的命令!
----队列 set set set 执行 ----
Redis事务没有隔离级别的概念
所有的命令在事务中,并没有直接被执行!只有发起执行命令的时候才会执行
Redis单条命令式保存原子性的,但是事务不保证原子性!
Redis的事务
- 开启事务(multi)
- 命令入队()
- 执行事务(exec)
正常执行事务
127.0.0.1:6379> multi #开启事务
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec #执行事务
1) OK
2) 1) "k1"
3) OK
4) OK
放弃事务
127.0.0.1:6379> multi #开启事务
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> DISCARD # 取消事务
OK
127.0.0.1:6379> get k4 #事务队列中的命令都不会执行
(nil)
编译型异常(代码有问题,命令有错),事务中所有的命令都不会被执行
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> getset k3 #错误的命令
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> exec # 执行事务时出错
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k5 #所有的命令都不会被执行!
(nil)
运行时异常(1/0),如果事务队列中存在语法性,那么执行命令的时候,其他命令是可以正常执行的
127.0.0.1:6379> set k1 "v1"
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr k1 # 错误的命令,字符串不能自增
QUEUED
127.0.0.1:6379> set k3 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> get k3
QUEUED
127.0.0.1:6379> exec #虽然第一条命令报错了,但是依旧正常执行成功了
1) (error) ERR value is not an integer or out of range
2) OK
3) OK
4) "v3"
127.0.0.1:6379> get k2
(nil)
127.0.0.1:6379> get k3
"v3"
监控 Wathch
悲观锁:
- 很悲观,什么时候都会出问题,无论做什么都会加锁!
乐观锁:
- 很乐观,认为什么时候都不会出问题,所以不会上锁,更新数据的时候去判断一下,再次期间是否友人修改过这个数据,version
- 获取version
- 更新的时候比较version
Redis监视测试
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money #监视 money 对象
OK
127.0.0.1:6379> multi #事务正常结束,数据期间没有发生变动,这个时候就会执行成功
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY out 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
测试多线程修改值,使用watch可以当作redis的乐观锁操作!
127,0.0.1:6379> watch money #监视money
OK
127,0,0,1:6379>mu1ti
OK
127.0.0.1:6379> DECRBY money 10
QUEUED
127,0,0,1:6379> INCRBY out 10
QUEUE
127.0.0.1:6379> exec #执行之前,1另外一个线程,修改了我们的值,这个时候,就会导致我们执行失败!
(ni1)
Jedis
我们要使用java来操作Redis
什么时jedis,是Redis官方推荐的Java连接工具!使用java操作Redis的中间件!如果你要使用Java操作redis,那么一定要对jedis十分的熟悉!
1.导入jedis的依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.78</version>
</dependency>
编码测试
- 连接数据库
- 操作命令
public class TestPing {
public static void main(String[] args){
//1. new Jedis 对象即可
Jedis jedis = new Jedis("127.0.0.1",6379);
//Jedis所有的命令就是我们之前学些的所有指令!
System.out.println(jedis.ping());
}
}
常用的API
1.SETBIT key offset value
对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
在redis中,存储的字符串都是以二进制的形式存在的。
我们知道 ‘a’ 的ASCII码是 97。转换为二进制是:01100001。offset的学名叫做“偏移” 。二进制中的每一位就是offset值啦,比如在这里 offset 0 等于 ‘0’ ,offset 1等于 ‘1’ ,offset 2 等于 ‘1’,offset 6 等于 ‘0’ ,没错,offset是从左往右计数的,也就是从高位往低位。
我们通过SETBIT 命令将 andy中的 ‘a’ 变成 ‘b’ 应该怎么变呢?
也就是将 01100001 变成 01100010 (b的ASCII码是98),这个很简单啦,也就是将’a’中的offset 6从0变成1,将offset 7 从1变成0 。
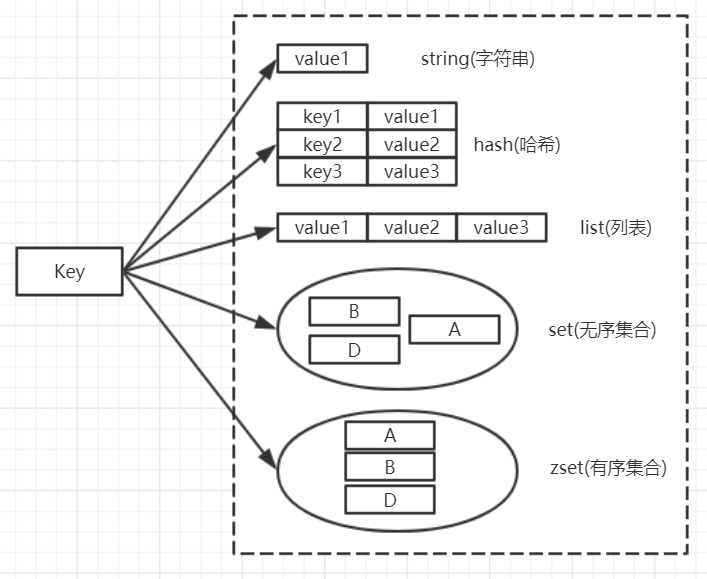
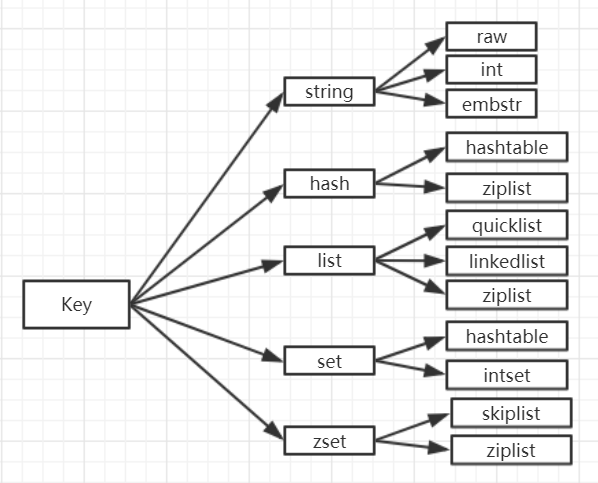
redis 的基本数据结构对应的底层实现如下图所示:
list的特点是:
- 有序
- 可以重复
- 右边进左边出或者左边进右边出,则列表可以充当队列
- 左边进左边出或者右边进右边出,则列表可以充当栈

















 9524
9524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









