







 本文深入讲解了TensorFlow中tf.data API的使用方法,包括Dataset的基础操作、读取CSV和TFRecord文件、数据预处理及批处理技巧。通过实例演示如何构建高效的数据管道,提升模型训练效率。
本文深入讲解了TensorFlow中tf.data API的使用方法,包括Dataset的基础操作、读取CSV和TFRecord文件、数据预处理及批处理技巧。通过实例演示如何构建高效的数据管道,提升模型训练效率。
tf.data API使用
tf.data 的作用是处理数据,读取数据,对数据做一些预处理,然后把数据塞给程序进行训练。
- Dataset 基础API使用
- Dataset读取csv文件(csv文件,用逗号分隔,按行存储的文件)
- Dataset读取tfrecord文件(tfrecord是TensorFlow独有存储格式,这种格式读取速度快)
API列表


读取文本文件和解析csv

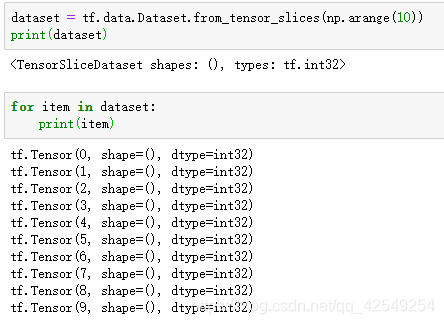
从内存中去构建数据集,参数可以是普通列表,numpy数组,字典
遍历dataset
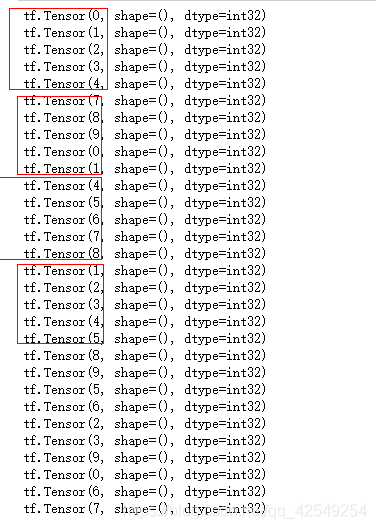
# 1. repeat epoch 遍历数据集
# 2. get batch 从数据集中选小部分数据进行训练
# 遍历3次 每次返回7个数据
dataset = dataset.repeat(3).batch(7)
for item in dataset:
print(item)

最后剩下两个 30 / 7 …2
# interleave: 对每个元素进行处理,产生新的结果,合并这些结果,形成一个新的数据集
# case: 文件dataset -> 具体数据集
dataset2 = dataset.interleave(
# 每次从数据集取出一个元素 形成新的数据集
lambda v: tf.data.Dataset.from_tensor_slices(v), # map_fn 做的变化
cycle_length = 5, # cycle_length 并行长度,同时处理多少个元素
block_length = 5, # block_length 从上面变化的结果中每次取多少个元素
)
for item in dataset2:
print(item)
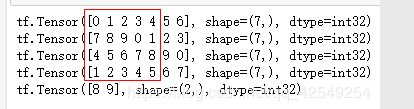
取出上面元素的前一个,取到8,9后面不够,取回第一行剩余元素。
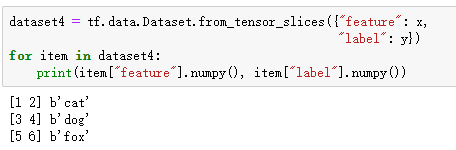
# 传入元组
x = np.array([[1, 2], [3, 4], [5, 6]])
# 传入numpy向量
y = np.array(['cat', 'dog', 'fox'])
dataset3 = tf.data.Dataset.from_tensor_slices((x, y))
print(dataset3)
for item_x, item_y in dataset3:
print(item_x.numpy(), item_y.numpy())

# 输入是字典
dataset4 = tf.data.Dataset.from_tensor_slices({"feature": x,
"label": y})
for item in dataset4:
print(item["feature"].numpy(), item["label"].numpy())
生成csv文件
#生成文件夹
output_dir = "generate_csv"
if not os.path.exists(output_dir):
os.mkdir(output_dir)
def save_to_csv(output_dir, data, name_prefix,
header=None, n_parts=10): #分为十个文件存储
# 生成文件名 第一括号填写name_prefix(看是train,valid还是test)名字 第二括号填写一个两位整数的数字
path_format = os.path.join(output_dir, "{}_{:02d}.csv")
filenames = []
for file_idx, row_indices in enumerate(
np.array_split(np.arange(len(data)), n_parts)):
# 生成文件名
part_csv = path_format.format(name_prefix, file_idx)
filenames.append(part_csv)
# 打开文件
with open(part_csv, "wt", encoding="utf-8") as f:
if header is not None:
f.write(header + "\n")
for row_index in row_indices:
f.write(",".join(
[repr(col) for col in data[row_index]]))
f.write('\n')
return filenames
# 按行进行merge
train_data = np.c_[x_train_scaled, y_train]
valid_data = np.c_[x_valid_scaled, y_valid]
test_data = np.c_[x_test_scaled, y_test]
# 八个特征 + 最后的输出特征
header_cols = housing.feature_names + ["MidianHouseValue"]
#使用逗号连接
header_str = ",".join(header_cols)
train_filenames = save_to_csv(output_dir, train_data, "train",
header_str, n_parts=20)
valid_filenames = save_to_csv(output_dir, valid_data, "valid",
header_str, n_parts=10)
test_filenames = save_to_csv(output_dir, test_data, "test",
header_str, n_parts=10)
生成csv

查看生成文件名

读取csv文件形成dataset
# 1. filename -> dataset
# 2. read file -> dataset -> datasets -> merge
# 3. parse csv
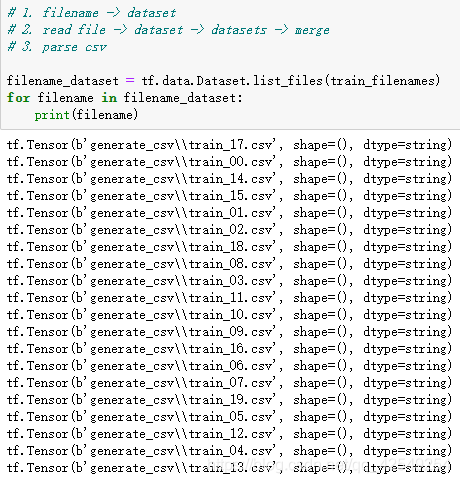
filename_dataset = tf.data.Dataset.list_files(train_filenames)
for filename in filename_dataset:
print(filename)
- filename -> dataset
- read file -> dataset -> datasets -> merge
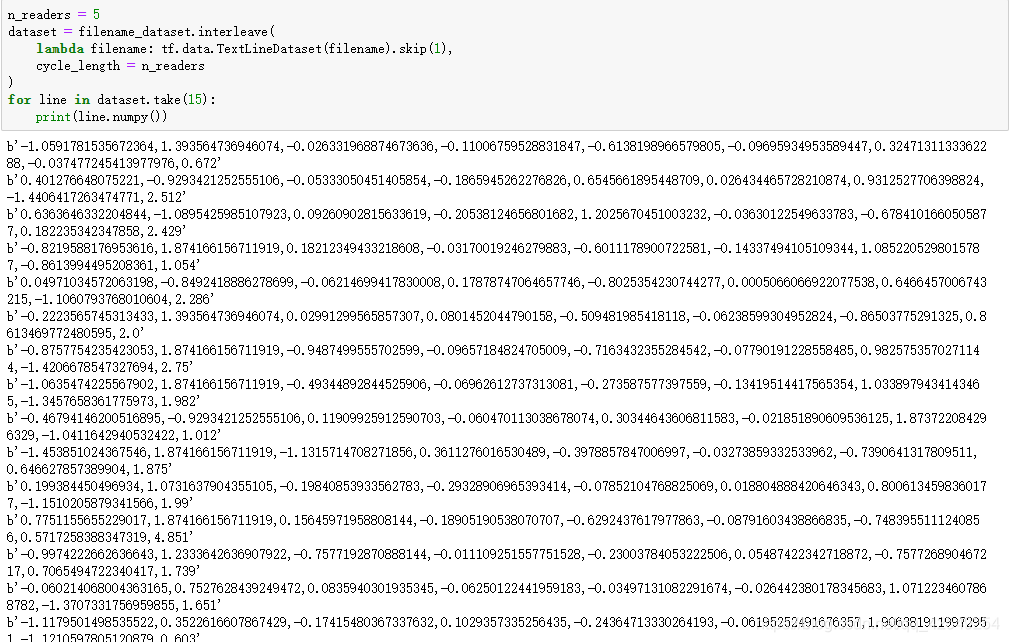
n_readers = 5
dataset = filename_dataset.interleave(
#.skip(1)省略header 第一行 按行读取文本形成dataset
lambda filename: tf.data.TextLineDataset(filename).skip(1),
cycle_length = n_readers
)
for line in dataset.take(15):
print(line.numpy())
3. parse csv 解析csv
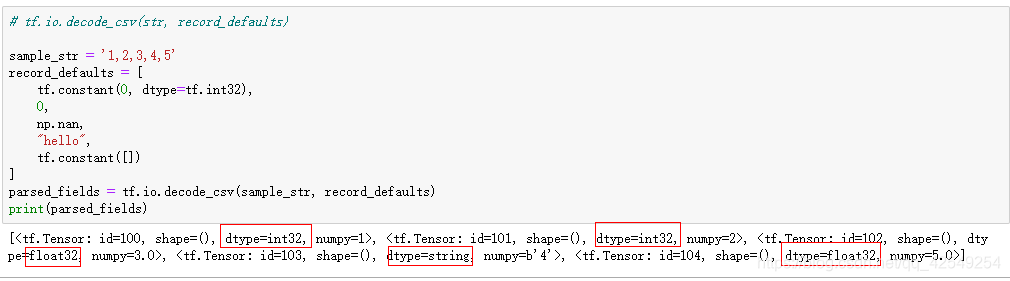
# tf.io.decode_csv(str, record_defaults)
sample_str = '1,2,3,4,5'
# 定义每个值的类型,当缺失的时候自动填写默认值
record_defaults = [
tf.constant(0, dtype=tf.int32),
0,
np.nan,
"hello",
tf.constant([])
]
parsed_fields = tf.io.decode_csv(sample_str, record_defaults)
print(parsed_fields)
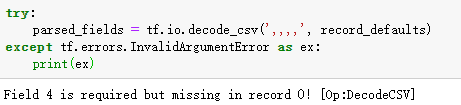
空值异常
.
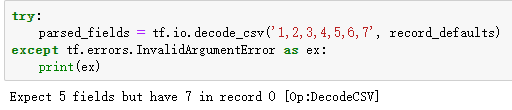
赋值过多异常
def parse_csv_line(line, n_fields = 9):
defs = [tf.constant(np.nan)] * n_fields
# 提取字符串
parsed_fields = tf.io.decode_csv(line, record_defaults=defs)
# 前八个值为一个向量
x = tf.stack(parsed_fields[0:-1])
# 最后一个值为一个向量
y = tf.stack(parsed_fields[-1:])
return x, y
parse_csv_line(b'-0.9868720801669367,0.832863080552588,-0.18684708416901633,-0.14888949288707784,-0.4532302419670616,-0.11504995754593579,1.6730974284189664,-0.7465496877362412,1.138',
n_fields=9)
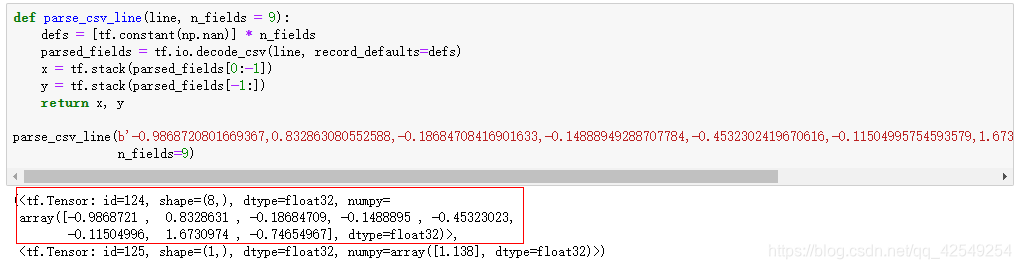
一个长度为8的向量和一个长度为1的y向量
转换解析整个csv
# 1. filename -> dataset
# 2. read file -> dataset -> datasets -> merge
# 3. parse csv
def csv_reader_dataset(filenames, n_readers=5,
batch_size=32, n_parse_threads=5,
shuffle_buffer_size=10000):
#filename -> dataset
dataset = tf.data.Dataset.list_files(filenames)
dataset = dataset.repeat()
# 文件名转化为文本内容
dataset = dataset.interleave(
lambda filename: tf.data.TextLineDataset(filename).skip(1),
cycle_length = n_readers
)
dataset.shuffle(shuffle_buffer_size)
# 一对一
dataset = dataset.map(parse_csv_line,
num_parallel_calls=n_parse_threads)
dataset = dataset.batch(batch_size)
return dataset
# 每次取出三个结果
train_set = csv_reader_dataset(train_filenames, batch_size=3)
for x_batch, y_batch in train_set.take(2):
print("x:")
pprint.pprint(x_batch)
print("y:")
pprint.pprint(y_batch)

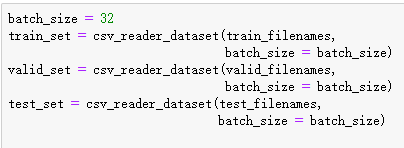
定义model进行fit
之前的model

model = keras.models.Sequential([
keras.layers.Dense(30, activation='relu',
#已知到是长度为8的向量
input_shape=[8]),
keras.layers.Dense(1),
])
model.compile(loss="mean_squared_error", optimizer="sgd")
callbacks = [keras.callbacks.EarlyStopping(
patience=5, min_delta=1e-2)]
#setl里面包含x和y数据
history = model.fit(train_set,
validation_data = valid_set,
#dataset是不停产生数据集的 设置迭代次数
steps_per_epoch = 11160 // batch_size,
validation_steps = 3870 // batch_size,
epochs = 100,
callbacks = callbacks)

测试



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









