







 本文介绍了MobileNet,一种针对移动和嵌入式视觉应用设计的高效卷积神经网络。它主要采用了深度可分离卷积,通过将标准卷积分解为深度卷积和点状卷积两步,显著减少了计算成本和模型大小。文中提出了两个全局超参数——宽度乘法器和分辨率乘法器,用于在精度和效率之间进行权衡。实验结果表明,即使在模型缩小的情况下,MobileNet也能保持较高的准确率,适用于各种任务,包括图像分类、目标检测、人脸识别等。
本文介绍了MobileNet,一种针对移动和嵌入式视觉应用设计的高效卷积神经网络。它主要采用了深度可分离卷积,通过将标准卷积分解为深度卷积和点状卷积两步,显著减少了计算成本和模型大小。文中提出了两个全局超参数——宽度乘法器和分辨率乘法器,用于在精度和效率之间进行权衡。实验结果表明,即使在模型缩小的情况下,MobileNet也能保持较高的准确率,适用于各种任务,包括图像分类、目标检测、人脸识别等。
文章目录
论文基本信息
- 标题:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- 作者:Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
- 机构:Google Inc.{howarda,menglong,bochen,dkalenichenko,weijunw,weyand,anm,hadam}@google.com
- 时间:2017
- 论文地址:arXiv:1704.04861v1 [cs.CV] 17 Apr 2017
- code:https://github.com/OUCTheoryGroup/colab_demo/blob/master/202003_models/MobileNetV1_CIFAR10.ipynb
研究背景
在AlexNet于ImageNet挑战赛获胜后,卷积神经网络在计算机视觉中变得无处不在。
实验者们为了达到更高的精度,一般趋势是使网络更深入、更复杂。然而,这些提高精准性的进步并不一定使网络在规模和速度方面更加高效。
总结一句话:只求高精准率,而不在乎网络的规模和速度。
本文描述了一种高效的网络架构和一组两个超参数,以建立非常小、低延迟的模型,可以很容易地匹配移动和嵌入式视觉应用程序的设计需求。
读过摘要后提出的问题
- 深度可分离卷积网络的架构是?
- 两个全局超参数是什么?怎么权衡延迟和精准性?
读完论文后对上述问题的回答
深度可分离网络
深度可分离卷积是一种分解卷积,将标准卷积分解为深度卷积核1*1卷积(点态卷积)。
一个标准的卷积可以在一步内将输入和输出组合成一组新的输出。而深度可分离卷积将其分为两层,分别用于过滤和合并,这种因子分解具有显著减少计算量和模型大小的效果。


这里需要注意的是:利用深度可分离卷积来打破了输出通道数量和核大小之间的相互影响。
标准卷积运算在卷积核的基础上过滤特征,结合特征产生新的表示。滤波核组合步骤可以通过分层卷积,被称为深度可分离卷积分解,分为了两个步骤,大大降低了计算成本。
深度可分离卷积由深度卷积和点向卷积两层组成,后接Batch Norm和ReLU。

深度卷积的计算成本:

其中计算代价与输入通道数M、输出通道数N、核大小Dk× Dk、特征映射大小DF× DF相乘。
深度可分离卷积的计算成本:

MobileNet使用3*3深度可分离卷积,其计算量比标准卷积少8到9倍,精度仅略有下降。具体见实验部分。
两个全局超参数
宽度倍增器:更薄的模型
引入了一个非常简单的参数
α
\alpha
α,称为宽度乘法器。
宽度乘法器的作用是使网络在每一层均匀地变薄。对于给定的层和宽度乘法器
α
\alpha
α,输入通道数M变为
α
\alpha
αM,输出通道数N变为
α
\alpha
αN。
具有宽度乘子
α
\alpha
α的深度可分解卷积的计算代价为:

其中
α
\alpha
α∈(0,1),其经典设置为1.0,0.75,0.5,0.25。
α
\alpha
α=1是基线MoblieNet。
α
\alpha
α<1是降低的MoblieNet。宽度乘法器具有近似
α
\alpha
α的二次方的降低计算成本和参数数量的效果。
宽度乘法器
α
\alpha
α可以应用于任何模型结构,以定义一个新的更小的模型,具有合理的精度、延迟和大小权衡。它用于定义新的简化结构,需要从头开始训练。
分辨率乘法器:简化的表示
降低神经网络计算成本的第二个超参数是分辨率乘法器
ρ
\rho
ρ。
我们将此应用于输入图像,然后每一层的内部表示随后被相同的乘法器减少。在实际中,我们通过设置输入分辨率隐式地设置
ρ
\rho
ρ。
现在的网络和薪酬的计算代价表示为 深度可分离卷积,其宽度乘法器
α
\alpha
α和分辨率乘法器
ρ
\rho
ρ:

其中
ρ
\rho
ρ∈(0,1)通常隐式设置,使网络的输入分辨率为224、192、160或128。ρ = 1是基线MobileNet,
ρ
\rho
ρ < 1是简化计算MobileNet。分辨率乘法器具有降低计算成本的效果。
实验验证
我们首先研究深度卷积的效果,以及通过减少网络的宽度而不是层的数量来进行收缩的选择。然后,我们展示了基于两个超参数:宽度乘法器和分辨率乘法器减少网络的权衡,并将结果与一些流行的模型进行了比较。然后研究了应用于许多不同应用程序的MoblieNet。
模型的选择
展示带有深度可分离卷积的MoblieNet与完全卷积模型的对比结果。

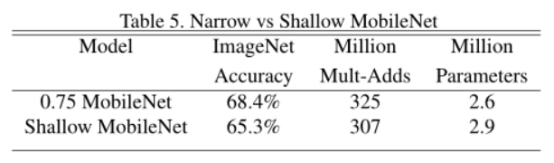
在表4中,我们看到,与完全卷积相比,使用深度可分离卷积只在ImageNet上降低了1%的精度,极大地节省了多添加和参数。我们接下来展示的结果比较薄模型与宽度倍增器浅模型使用更少的层。为了使MobileNet更浅,我们去掉了表1中特征尺寸为14 × 14 × 512的5层可分离滤波器。从表5可以看出,在相似的计算和参数数量下,使mobilenet变薄比使其变浅要好3%。
收缩模型超参数
表6显示了用宽度乘法器α缩小MobileNet体系结构的精度、计算和尺寸权衡。在α = 0.25时,精度平稳下降,直到架构变得太小。
表7显示了通过降低输入分辨率训练mobilenet,不同分辨率乘法器的精度、计算和大小权衡。精度在分辨率上平稳下降。
图4显示了由宽度乘子α∈{1,0.75,0.5,0.25}和分辨率{224,192,160,128}交叉积的16个模型的ImageNet精度和计算之间的权衡。当模型在α = 0.25处变得非常小时,结果是具有跳跃的对数线性。
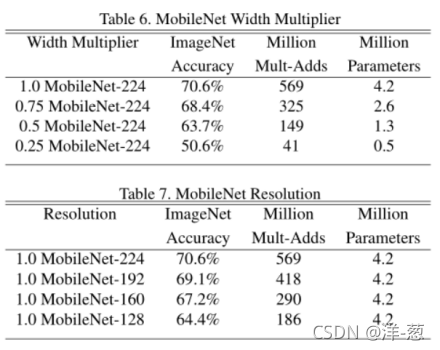
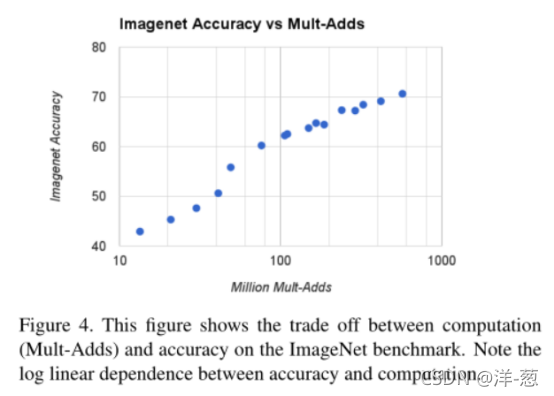
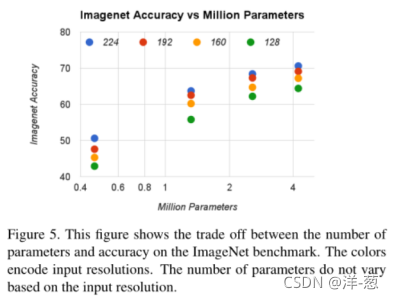
图5显示了宽度乘子α∈{1,0.75,0.5,0.25}与分辨率{224,192,160,128}交叉积的16个模型的ImageNet精度和参数数量之间的权衡。
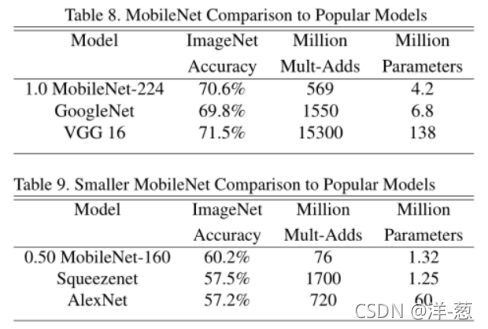
表8比较了完整的MobileNet与原始的GoogleNet[30]和VGG16[27]。MobileNet几乎与VGG16一样精确,但它比VGG16小32倍,计算密集型低27倍。它比GoogleNet更精确,同时体积更小,计算量更少2.5倍以上。
表9比较了缩小后的MobileNet,其宽度乘法器α = 0.5,分辨率为160 × 160。reduce MobileNet比AlexNet[19]小了45×,计算量少了9.4×,比AlexNet[19]小了4%。与Squeezenet[12]相比,在尺寸相同的情况下,其计算量减少了22倍,也提高了4%。
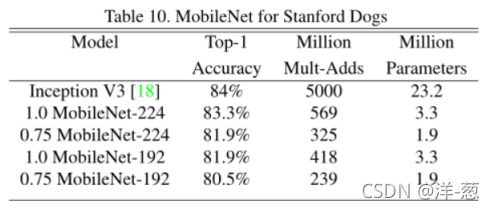
细粒度的识别
我们训练MobileNet在Stanford Dogs数据集[17]上进行细粒度识别。我们扩展了[18]的方法,从网络上收集了比[18]更大但更有噪声的训练集。我们使用嘈杂的网络数据来预训练一个细粒度的狗识别模型,然后在斯坦福狗训练集上对模型进行微调。Stanford Dogs测试集的结果如表10所示。MobileNet几乎可以在大大减少计算和大小的情况下实现[18]的最新结果。
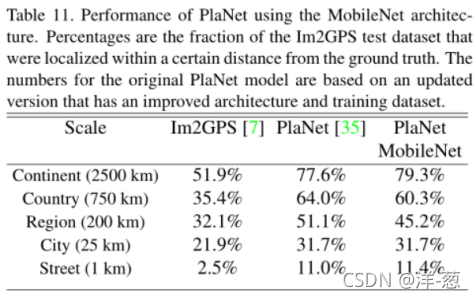
大规模地理定位
行星[35]把确定照片拍摄地点的任务作为一个分类问题。该方法将地球划分成一个由地理单元组成的网格,这些单元作为目标类别,并在数百万张地理标记照片上训练卷积神经网络。PlaNet已经被证明能够成功地定位大量不同的照片,并胜过Im2GPS[6,7]处理相同任务。
我们在相同的数据上使用MobileNet架构重新训练PlaNet。而基于Inception V3架构的完整PlaNet模型[31]有5200万个参数和57.4亿个多重添加。MobileNet模型只有1300万个参数,通常有300万个用于主体,1000万个用于最后一层,58万个多重添加。如表11所示,尽管MobileNet版本更加紧凑,但与PlaNet相比,其性能仅略有下降。而且,它的表现仍然远远超过Im2GPS。
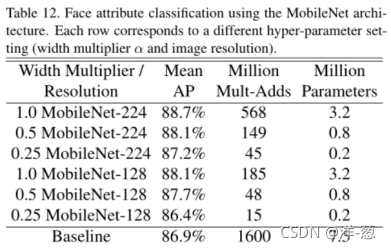
面对属性
MobileNet的另一个用例是使用未知或深奥的培训过程压缩大型系统。在人脸属性分类任务中,我们证明了MobileNet和精馏[9]之间的协同关系,精馏[9]是一种用于深度网络的知识转移技术。我们试图减少一个拥有7500万个参数和1600万个mult - add的大型人脸属性分类器。在类似于YFCC100M[32]的多属性数据集上训练分类器。
我们使用MobileNet体系结构提取人脸属性分类器。蒸馏[9]通过训练分类器来模拟更大的model2而不是ground-truth标签的输出来工作,因此可以从大型(可能是无限的)未标记数据集进行训练。结合蒸馏训练的可扩展性和MobileNet的精简参数化,终端系统不仅不需要正则化(如权重衰减和早停),而且性能也得到了提高。从表12中可以明显看出,基于mobilenet的分类器对激进的模型收缩具有弹性:它实现了与内部相似的跨属性平均精度(平均AP),而只消耗1%的multi - add。
对象检测
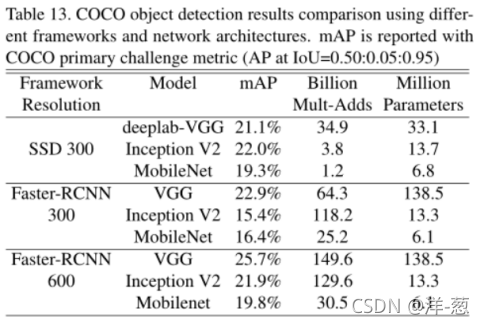
在现代目标检测系统中,MobileNet也可以作为一个有效的基础网络部署。基于最近赢得2016年COCO挑战[10]的工作,我们报告了基于COCO数据进行目标检测的MobileNet训练的结果。在表13中,MobileNet在Faster-RCNN[23]和SSD[21]框架下与VGG和Inception V2[13]进行了比较。在我们的实验中,SSD以300输入分辨率进行评估(SSD 300), Faster-RCNN与300和600输入分辨率(FasterRCNN 300, Faster-RCNN 600)进行比较。Faster-RCNN模型对每幅图像评估300个RPN建议框。模型在COCO train+val上训练,不包括8k的微型图像并在最小值上进行评估。对于这两种框架,MobileNet只需要很小的计算复杂性和模型大小就能获得与其他网络相当的结果。
面对嵌入
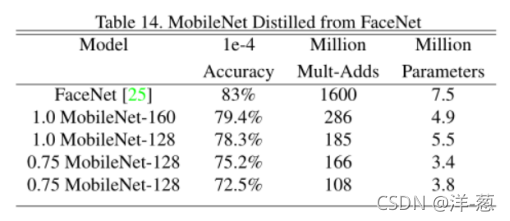
FaceNet模型是最新的人脸识别模型[25]。它基于三联体损耗构建人脸嵌入。为了建立移动FaceNet模型,我们使用蒸馏的方法,通过最小化FaceNet和MobileNet输出在训练数据上的平方差来进行训练。非常小的MobileNet模型的结果可以在表14中找到。
代码分析
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
#导入所需的包
class Block(nn.Module):#定义block,即上文设定的可分离卷积+点态卷积
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
# Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# Pointwise 卷积,1*1 的卷积核
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
创建Dataloader
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#检测设备中的gpu或者cpu
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),#图像裁剪为32*32大小的
transforms.RandomHorizontalFlip(),#以给定的概率水平旋转给定的PIL图像,默认为0.5
transforms.ToTensor(),#将给定的图像转为Tensor
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])#归一化处理
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
创建 MobileNetV1 网络 32×32×3 ==>
32×32×32 ==> 32×32×64 ==> 16×16×128 ==> 16×16×128 ==>
8×8×256 ==> 8×8×256 ==> 4×4×512 ==> 4×4×512 ==>
2×2×1024 ==> 2×2×1024
接下来为均值 pooling ==> 1×1×1024
最后全连接到 10个输出节点
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
实例化网络
# 网络放到GPU/CPU上
net = MobileNetV1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
模型训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
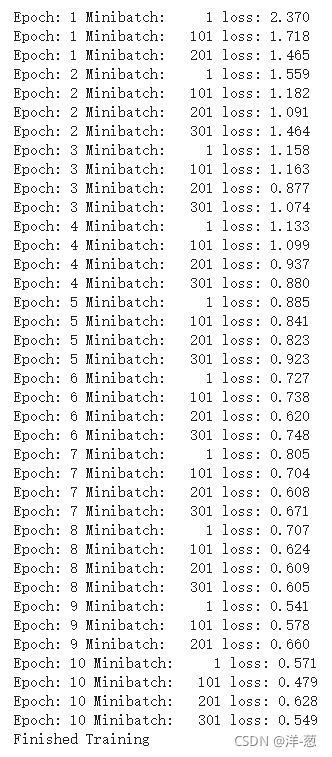
模型训练过程:
模型测试
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
测试结果:
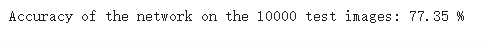
目前存在的疑惑
为啥代码中没有查看到两个超参数 α \alpha α, ρ \rho ρ的使用

















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









