






基于通义千问大模型和Flask的PDF批量提取系统
在当今数字化时代,处理大量PDF文档并从中提取关键信息已成为许多企业的日常需求。本文将介绍如何利用通义千问大模型和Flask框架构建一个高效的PDF批量提取系统。
系统架构
该系统主要由三个核心模块组成:
- 前端界面 :基于HTML5和Tailwind CSS构建的用户界面
- 后端服务 :使用Flask框架搭建的RESTful API
- AI处理引擎 :基于通义千问大模型的PDF内容提取模块
核心功能
- PDF文件批量上传
- 多进程并行处理
- 实时进度监控
- 结果自动保存为Excel
- 处理结果下载
技术亮点
1. 通义千问大模型集成
系统通过OpenAI SDK与通义千问大模型进行集成,实现PDF内容的智能提取。核心处理逻辑如下:
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def process_with_retry(client, file_object):
completion = client.chat.completions.create(
model="qwen-long",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'system', 'content': f'fileid://{file_object.id}'},
{'role': 'user',
'content': '抽取信息的话术'}
],
stream=True,
stream_options={"include_usage": True},
timeout=60.0
)
return completion
2. 多进程并行处理
系统采用Python的multiprocessing模块实现多进程并行处理,显著提升处理效率
def process_pdfs_multi(self, directory_path, year, month, pdf_limit=None, multi_process=False, process_num=None):
# ... 省略部分代码 ...
if multi_process and len(pdf_files) > 1:
with ProcessPoolExecutor(max_workers=process_num) as executor:
futures = [executor.submit(process_pdf_in_process, task, shared_status) for task in pdf_tasks]
for future in as_completed(futures):
# 处理完成的任务
result_info = future.result()
# ... 处理结果 ...
3. 实时进度监控
前端通过WebSocket与后端保持通信,实时更新处理进度:
function updateProgress() {
fetch('/status')
.then(response => response.json())
.then(data => {
const progress = (data.data.processed_files / data.data.total_files) * 100;
document.getElementById('progressBar').style.width = `${progress}%`;
document.getElementById('progressPercentage').textContent = `${Math.round(progress)}%`;
// ... 更新其他状态信息 ...
});
}
4. 结果自动保存
处理完成后,系统会自动将结果保存为Excel文件
if all_results:
df = pd.DataFrame(all_results)
output_name = os.path.abspath(os.path.join(directory_path, f"{year}年{month}月电费账单.xlsx"))
df.to_excel(output_name, index=False)
系统实现
在这里插入图片描述
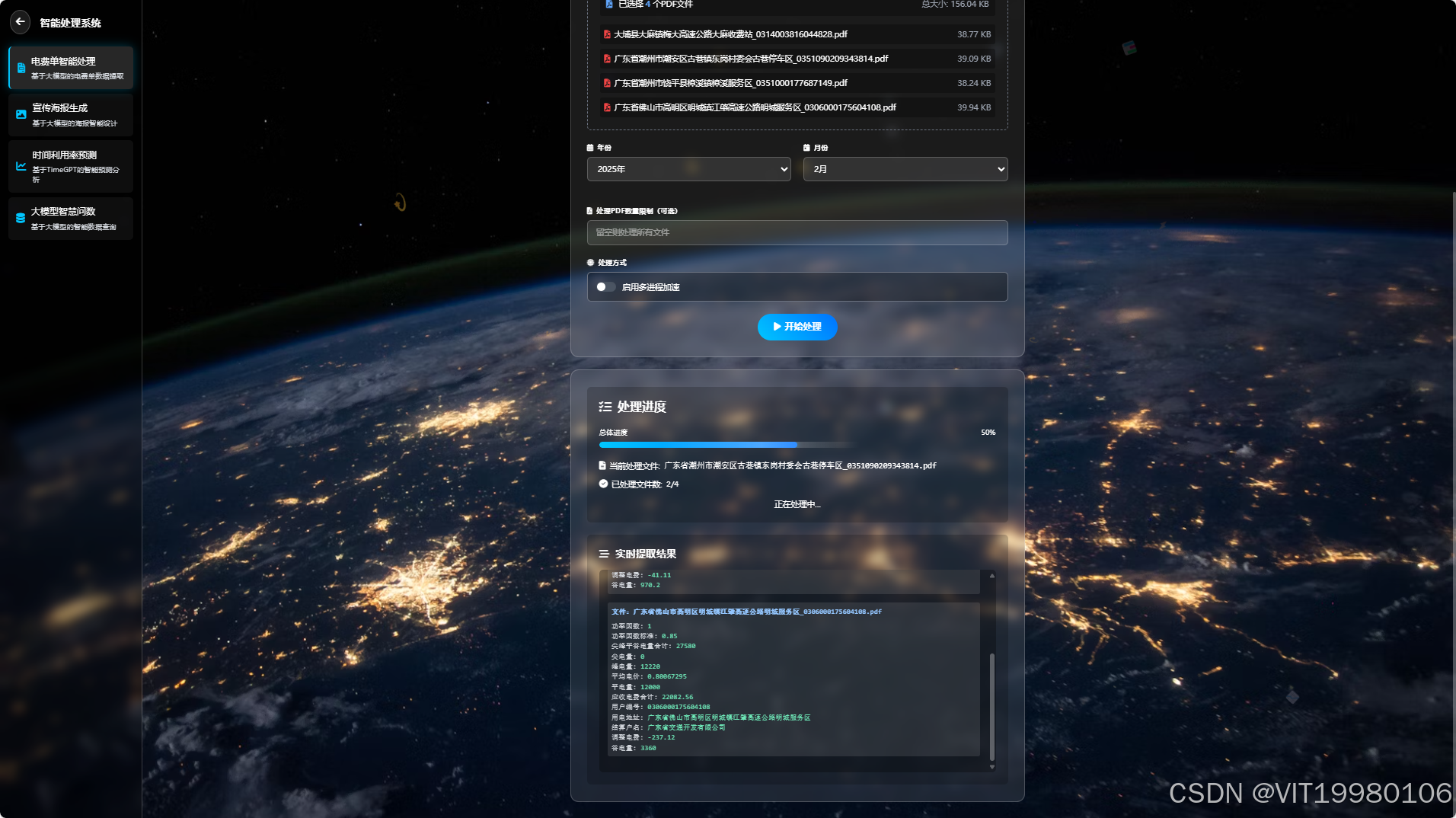
系统优势
- 高效性 :多进程并行处理大幅提升处理速度
- 可靠性 :重试机制确保处理过程的稳定性
- 易用性 :直观的用户界面和实时进度显示
- 扩展性 :模块化设计便于功能扩展
- 安全性 :文件上传和处理的隔离机制
应用场景
- 电力公司电费单批量处理
- 金融机构合同文档分析
- 政府部门公文处理
- 企业财务报表分析
- 教育机构试卷批改



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











