







 本文从CPU结构出发,探讨了汇编语言中函数调用的过程,特别是call指令与jal指令如何实现跳转,以及参数如何通过push和pop指令入栈。通过解析栈指针的工作方式,解释了如何在函数执行过程中保存和恢复参数,以及数据存储和清理的逻辑。建议对计算机组成原理感兴趣的读者进一步学习栈和数据结构。
本文从CPU结构出发,探讨了汇编语言中函数调用的过程,特别是call指令与jal指令如何实现跳转,以及参数如何通过push和pop指令入栈。通过解析栈指针的工作方式,解释了如何在函数执行过程中保存和恢复参数,以及数据存储和清理的逻辑。建议对计算机组成原理感兴趣的读者进一步学习栈和数据结构。
学习汇编语言,相信大家对函数的调用和堆栈着实是百般无奈,辣么多参数,突然就一个调用,鬼知道是怎么回事!!!
不过,最近写了一边单周期CPU之后,突然感觉其实这个问题并没有辣么复杂。
CPU的结构:
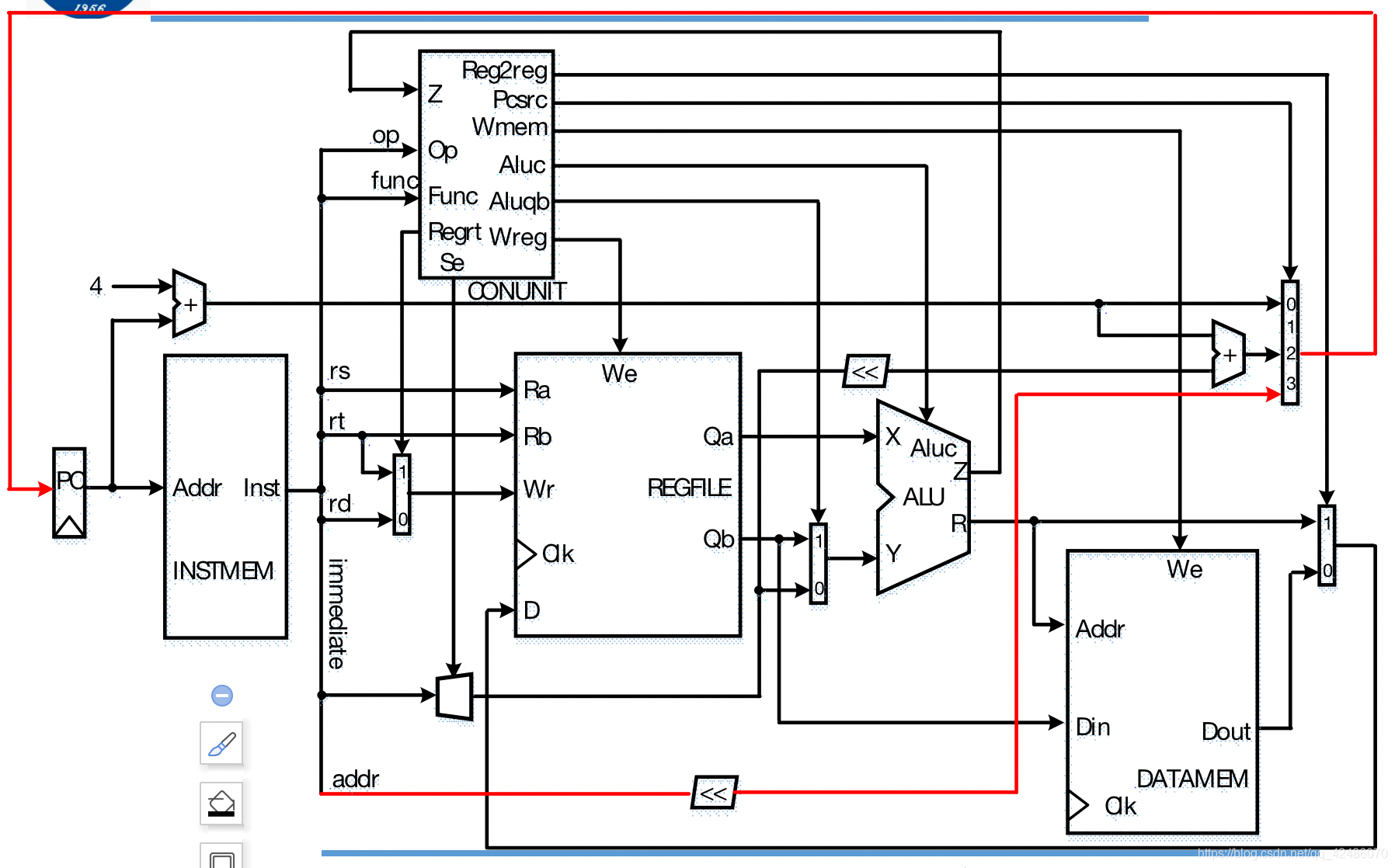
我们知道,单周期CPU主要有几个重要的部件组成:
控制单元Control Unit:
根据指令存储器输入的指令(利用前6位的Op字段与后6位的Func字段),输出多个多路选择器的选择信号与写使能信号
算术逻辑单元Arithmatic-Logic Unit:
根据输入的X、Y与控制信号Aluc进行各种运算
寄存器堆:
32个通用寄存器组成,大多数需要读、写的操作在此完成
寄存器:
单独的寄存器。
既然有了寄存器堆,为什么还要寄存器呢?
其实很简单,一方面,寄存器堆的输入参数是与指令密切相关的,那么当出现了一种与其他指令结构截然不同的指令,再使用寄存器堆就显得异常麻烦,需要更改很多线路设置以及控制单元输出,不如设置特殊的寄存器。
另一方面,有时候即便不涉及到指令本身,我们也有一些需要记录的数据,比如指令的地址,我们需要记录到pc寄存器中,等到时钟信号上升沿到来时,自动根据指令种类变化为下一条指令的地址,输出给指令存储器,为下一条指令所需要的数据最好准备。
至于其他零零散散的组件,都是用于服务以上部件的辅助线路,不足为道。
call:
咳咳,扯远了
回到正题,函数的调用
我们知道,在汇编语言中,调用函数是需要把好几个参数入栈之后,再call的,那么,这个过程在CPU中是怎样的呢?
在机器指令中,有一个指令与call密切相关,那就是jal
j
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









